 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Euclidean Gradient Descent Operates at the Edge of Stability
Mar 05, 2026The Edge of Stability (EoS) is a phenomenon where the sharpness (largest eigenvalue) of the Hessian converges to $2/η$ during training with gradient descent (GD) with a step-size $η$. Despite (apparently) violating classical smoothness assumptions, EoS has been widely observed in deep learning, but its theoretical foundations remain incomplete. We provide an interpretation of EoS through the lens of Directional Smoothness Mishkin et al. [2024]. This interpretation naturally extends to non-Euclidean norms, which we use to define generalized sharpness under an arbitrary norm. Our generalized sharpness measure includes previously studied vanilla GD and preconditioned GD as special cases, as well as methods for which EoS has not been studied, such as $\ell_{\infty}$-descent, Block CD, Spectral GD, and Muon without momentum. Through experiments on neural networks, we show that non-Euclidean GD with our generalized sharpness also exhibits progressive sharpening followed by oscillations around or above the threshold $2/η$. Practically, our framework provides a single, geometry-aware spectral measure that works across optimizers.
In Search of Adam's Secret Sauce
May 27, 2025Understanding the remarkable efficacy of Adam when training transformer-based language models has become a central research topic within the optimization community. To gain deeper insights, several simplifications of Adam have been proposed, such as the signed gradient and signed momentum methods. In this work, we conduct an extensive empirical study - training over 1,300 language models across different data configurations and scales - comparing Adam to several known simplified variants. We find that signed momentum methods are faster than SGD, but consistently underperform relative to Adam, even after careful tuning of momentum, clipping setting and learning rates. However, our analysis reveals a compelling option that preserves near-optimal performance while allowing for new insightful reformulations: constraining the Adam momentum parameters to be equal. Beyond robust performance, this choice affords new theoretical insights, highlights the "secret sauce" on top of signed momentum, and grants a precise statistical interpretation: we show that Adam in this setting implements a natural online algorithm for estimating the mean and variance of gradients-one that arises from a mean-field Gaussian variational inference perspective.
The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm
May 22, 2025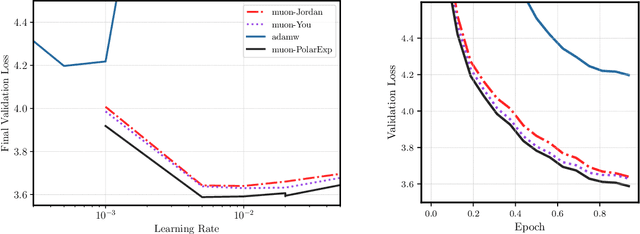
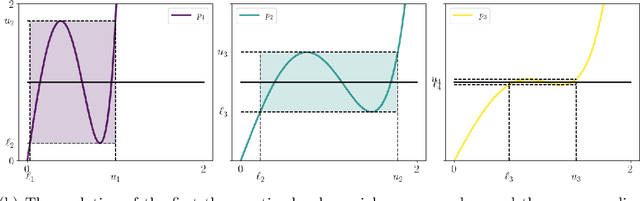
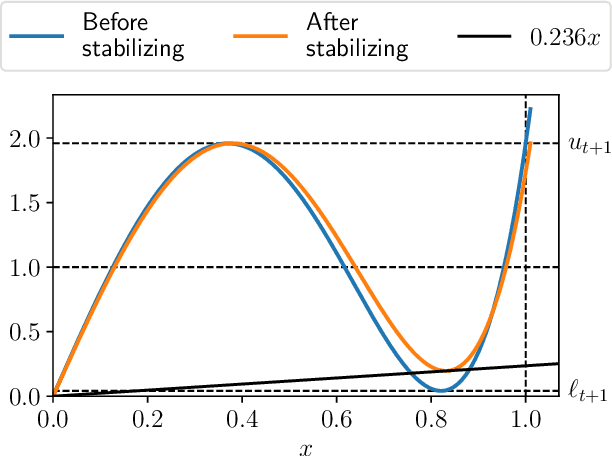
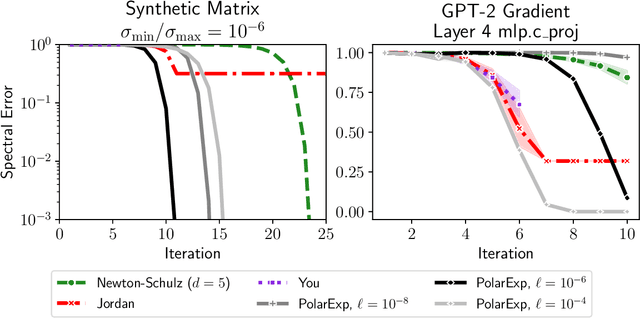
Computing the polar decomposition and the related matrix sign function, has been a well-studied problem in numerical analysis for decades. More recently, it has emerged as an important subroutine in deep learning, particularly within the Muon optimization framework. However, the requirements in this setting differ significantly from those of traditional numerical analysis. In deep learning, methods must be highly efficient and GPU-compatible, but high accuracy is often unnecessary. As a result, classical algorithms like Newton-Schulz (which suffers from slow initial convergence) and methods based on rational functions (which rely on QR decompositions or matrix inverses) are poorly suited to this context. In this work, we introduce Polar Express, a GPU-friendly algorithm for computing the polar decomposition. Like classical polynomial methods such as Newton-Schulz, our approach uses only matrix-matrix multiplications, making it GPU-compatible. Motivated by earlier work of Chen & Chow and Nakatsukasa & Freund, Polar Express adapts the polynomial update rule at each iteration by solving a minimax optimization problem, and we prove that it enjoys a strong worst-case optimality guarantee. This property ensures both rapid early convergence and fast asymptotic convergence. We also address finite-precision issues, making it stable in bfloat16 in practice. We apply Polar Express within the Muon optimization framework and show consistent improvements in validation loss on large-scale models such as GPT-2, outperforming recent alternatives across a range of learning rates.
SGD with Clipping is Secretly Estimating the Median Gradient
Feb 20, 2024



There are several applications of stochastic optimization where one can benefit from a robust estimate of the gradient. For example, domains such as distributed learning with corrupted nodes, the presence of large outliers in the training data, learning under privacy constraints, or even heavy-tailed noise due to the dynamics of the algorithm itself. Here we study SGD with robust gradient estimators based on estimating the median. We first consider computing the median gradient across samples, and show that the resulting method can converge even under heavy-tailed, state-dependent noise. We then derive iterative methods based on the stochastic proximal point method for computing the geometric median and generalizations thereof. Finally we propose an algorithm estimating the median gradient across iterations, and find that several well known methods - in particular different forms of clipping - are particular cases of this framework.
SANIA: Polyak-type Optimization Framework Leads to Scale Invariant Stochastic Algorithms
Dec 28, 2023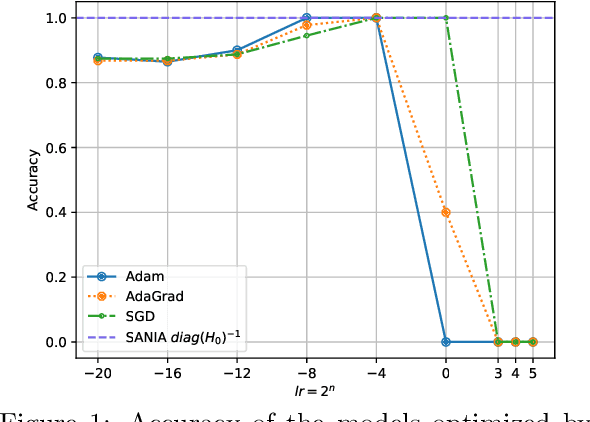
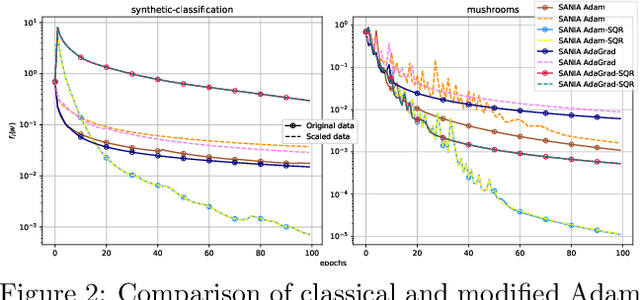
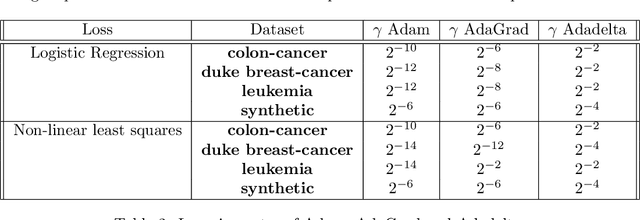
Adaptive optimization methods are widely recognized as among the most popular approaches for training Deep Neural Networks (DNNs). Techniques such as Adam, AdaGrad, and AdaHessian utilize a preconditioner that modifies the search direction by incorporating information about the curvature of the objective function. However, despite their adaptive characteristics, these methods still require manual fine-tuning of the step-size. This, in turn, impacts the time required to solve a particular problem. This paper presents an optimization framework named SANIA to tackle these challenges. Beyond eliminating the need for manual step-size hyperparameter settings, SANIA incorporates techniques to address poorly scaled or ill-conditioned problems. We also explore several preconditioning methods, including Hutchinson's method, which approximates the Hessian diagonal of the loss function. We conclude with an extensive empirical examination of the proposed techniques across classification tasks, covering both convex and non-convex contexts.
Variational Inference with Gaussian Score Matching
Jul 15, 2023Variational inference (VI) is a method to approximate the computationally intractable posterior distributions that arise in Bayesian statistics. Typically, VI fits a simple parametric distribution to the target posterior by minimizing an appropriate objective such as the evidence lower bound (ELBO). In this work, we present a new approach to VI based on the principle of score matching, that if two distributions are equal then their score functions (i.e., gradients of the log density) are equal at every point on their support. With this, we develop score matching VI, an iterative algorithm that seeks to match the scores between the variational approximation and the exact posterior. At each iteration, score matching VI solves an inner optimization, one that minimally adjusts the current variational estimate to match the scores at a newly sampled value of the latent variables. We show that when the variational family is a Gaussian, this inner optimization enjoys a closed form solution, which we call Gaussian score matching VI (GSM-VI). GSM-VI is also a ``black box'' variational algorithm in that it only requires a differentiable joint distribution, and as such it can be applied to a wide class of models. We compare GSM-VI to black box variational inference (BBVI), which has similar requirements but instead optimizes the ELBO. We study how GSM-VI behaves as a function of the problem dimensionality, the condition number of the target covariance matrix (when the target is Gaussian), and the degree of mismatch between the approximating and exact posterior distribution. We also study GSM-VI on a collection of real-world Bayesian inference problems from the posteriorDB database of datasets and models. In all of our studies we find that GSM-VI is faster than BBVI, but without sacrificing accuracy. It requires 10-100x fewer gradient evaluations to obtain a comparable quality of approximation.
Provable convergence guarantees for black-box variational inference
Jun 04, 2023
While black-box variational inference is widely used, there is no proof that its stochastic optimization succeeds. We suggest this is due to a theoretical gap in existing stochastic optimization proofs-namely the challenge of gradient estimators with unusual noise bounds, and a composite non-smooth objective. For dense Gaussian variational families, we observe that existing gradient estimators based on reparameterization satisfy a quadratic noise bound and give novel convergence guarantees for proximal and projected stochastic gradient descent using this bound. This provides the first rigorous guarantee that black-box variational inference converges for realistic inference problems.