 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Inference with Gaussian Score Matching
Jul 15, 2023Variational inference (VI) is a method to approximate the computationally intractable posterior distributions that arise in Bayesian statistics. Typically, VI fits a simple parametric distribution to the target posterior by minimizing an appropriate objective such as the evidence lower bound (ELBO). In this work, we present a new approach to VI based on the principle of score matching, that if two distributions are equal then their score functions (i.e., gradients of the log density) are equal at every point on their support. With this, we develop score matching VI, an iterative algorithm that seeks to match the scores between the variational approximation and the exact posterior. At each iteration, score matching VI solves an inner optimization, one that minimally adjusts the current variational estimate to match the scores at a newly sampled value of the latent variables. We show that when the variational family is a Gaussian, this inner optimization enjoys a closed form solution, which we call Gaussian score matching VI (GSM-VI). GSM-VI is also a ``black box'' variational algorithm in that it only requires a differentiable joint distribution, and as such it can be applied to a wide class of models. We compare GSM-VI to black box variational inference (BBVI), which has similar requirements but instead optimizes the ELBO. We study how GSM-VI behaves as a function of the problem dimensionality, the condition number of the target covariance matrix (when the target is Gaussian), and the degree of mismatch between the approximating and exact posterior distribution. We also study GSM-VI on a collection of real-world Bayesian inference problems from the posteriorDB database of datasets and models. In all of our studies we find that GSM-VI is faster than BBVI, but without sacrificing accuracy. It requires 10-100x fewer gradient evaluations to obtain a comparable quality of approximation.
Large Deviation Methods for Approximate Probabilistic Inference
Jan 30, 2013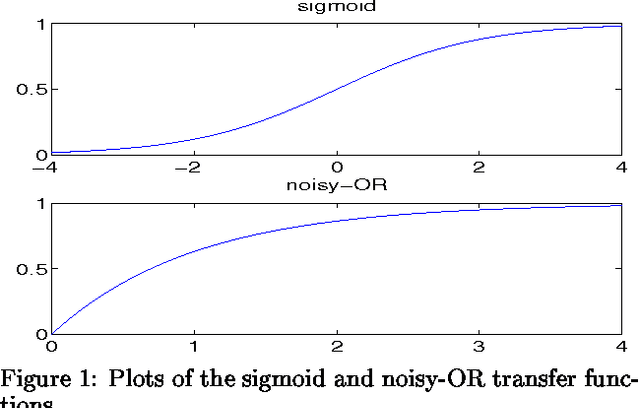
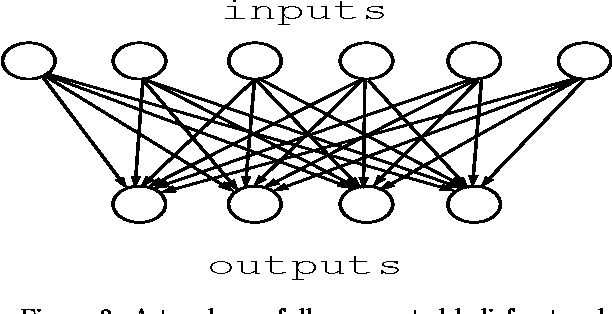
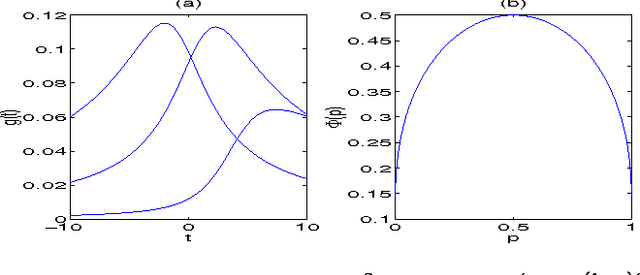
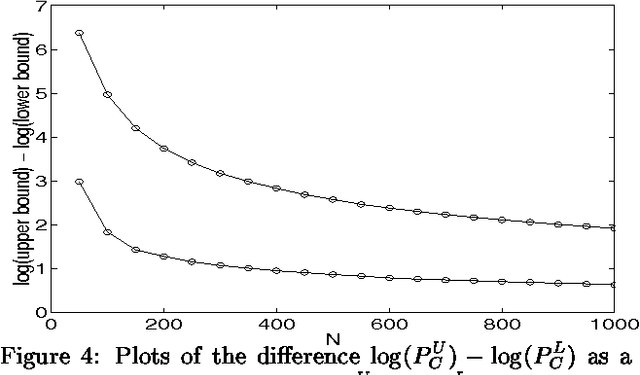
We study two-layer belief networks of binary random variables in which the conditional probabilities Pr[childlparents] depend monotonically on weighted sums of the parents. In large networks where exact probabilistic inference is intractable, we show how to compute upper and lower bounds on many probabilities of interest. In particular, using methods from large deviation theory, we derive rigorous bounds on marginal probabilities such as Pr[children] and prove rates of convergence for the accuracy of our bounds as a function of network size. Our results apply to networks with generic transfer function parameterizations of the conditional probability tables, such as sigmoid and noisy-OR. They also explicitly illustrate the types of averaging behavior that can simplify the problem of inference in large networks.
Aggregate and mixed-order Markov models for statistical language processing
Jun 09, 1997
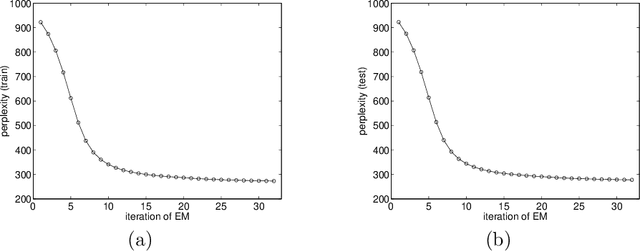

We consider the use of language models whose size and accuracy are intermediate between different order n-gram models. Two types of models are studied in particular. Aggregate Markov models are class-based bigram models in which the mapping from words to classes is probabilistic. Mixed-order Markov models combine bigram models whose predictions are conditioned on different words. Both types of models are trained by Expectation-Maximization (EM) algorithms for maximum likelihood estimation. We examine smoothing procedures in which these models are interposed between different order n-grams. This is found to significantly reduce the perplexity of unseen word combinations.