Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregate and mixed-order Markov models for statistical language processing
Paper and Code
Jun 09, 1997
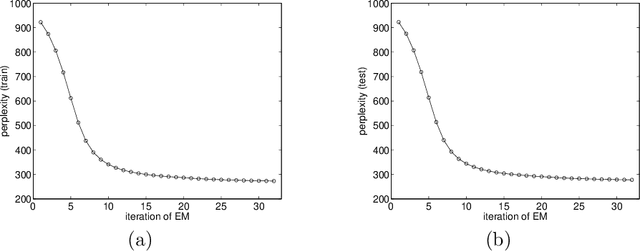

We consider the use of language models whose size and accuracy are intermediate between different order n-gram models. Two types of models are studied in particular. Aggregate Markov models are class-based bigram models in which the mapping from words to classes is probabilistic. Mixed-order Markov models combine bigram models whose predictions are conditioned on different words. Both types of models are trained by Expectation-Maximization (EM) algorithms for maximum likelihood estimation. We examine smoothing procedures in which these models are interposed between different order n-grams. This is found to significantly reduce the perplexity of unseen word combinations.
* 9 pages, 4 PostScript figures, uses psfig.sty and aclap.sty; to
appear in the proceedings of EMNLP-2
View paper on