 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-Size Stability in Stochastic Optimization: A Theoretical Perspective
Feb 10, 2026We present a theoretical analysis of stochastic optimization methods in terms of their sensitivity with respect to the step size. We identify a key quantity that, for each method, describes how the performance degrades as the step size becomes too large. For convex problems, we show that this quantity directly impacts the suboptimality bound of the method. Most importantly, our analysis provides direct theoretical evidence that adaptive step-size methods, such as SPS or NGN, are more robust than SGD. This allows us to quantify the advantage of these adaptive methods beyond empirical evaluation. Finally, we show through experiments that our theoretical bound qualitatively mirrors the actual performance as a function of the step size, even for nonconvex problems.
Schedulers for Schedule-free: Theoretically inspired hyperparameters
Nov 11, 2025The recently proposed schedule-free method has been shown to achieve strong performance when hyperparameter tuning is limited. The current theory for schedule-free only supports a constant learning rate, where-as the implementation used in practice uses a warm-up schedule. We show how to extend the last-iterate convergence theory of schedule-free to allow for any scheduler, and how the averaging parameter has to be updated as a function of the learning rate. We then perform experiments showing how our convergence theory has some predictive power with regards to practical executions on deep neural networks, despite that this theory relies on assuming convexity. When applied to the warmup-stable-decay (wsd) schedule, our theory shows the optimal convergence rate of $\mathcal{O}(1/\sqrt{T})$. We then use convexity to design a new adaptive Polyak learning rate schedule for schedule-free. We prove an optimal anytime last-iterate convergence for our new Polyak schedule, and show that it performs well compared to a number of baselines on a black-box model distillation task.
Fisher meets Feynman: score-based variational inference with a product of experts
Oct 24, 2025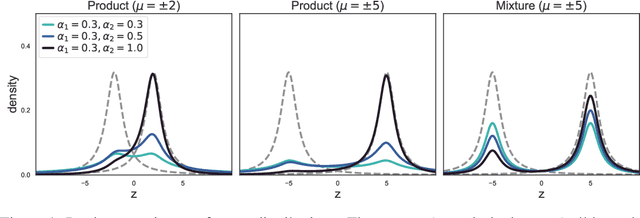
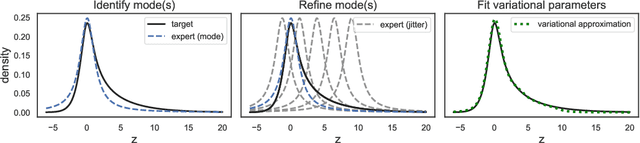
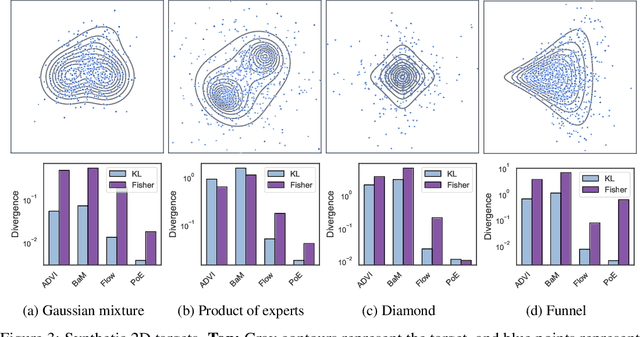
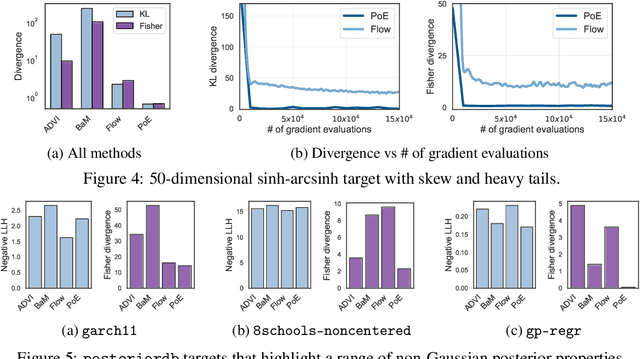
We introduce a highly expressive yet distinctly tractable family for black-box variational inference (BBVI). Each member of this family is a weighted product of experts (PoE), and each weighted expert in the product is proportional to a multivariate $t$-distribution. These products of experts can model distributions with skew, heavy tails, and multiple modes, but to use them for BBVI, we must be able to sample from their densities. We show how to do this by reformulating these products of experts as latent variable models with auxiliary Dirichlet random variables. These Dirichlet variables emerge from a Feynman identity, originally developed for loop integrals in quantum field theory, that expresses the product of multiple fractions (or in our case, $t$-distributions) as an integral over the simplex. We leverage this simplicial latent space to draw weighted samples from these products of experts -- samples which BBVI then uses to find the PoE that best approximates a target density. Given a collection of experts, we derive an iterative procedure to optimize the exponents that determine their geometric weighting in the PoE. At each iteration, this procedure minimizes a regularized Fisher divergence to match the scores of the variational and target densities at a batch of samples drawn from the current approximation. This minimization reduces to a convex quadratic program, and we prove under general conditions that these updates converge exponentially fast to a near-optimal weighting of experts. We conclude by evaluating this approach on a variety of synthetic and real-world target distributions.
Analysis of an Idealized Stochastic Polyak Method and its Application to Black-Box Model Distillation
Apr 02, 2025
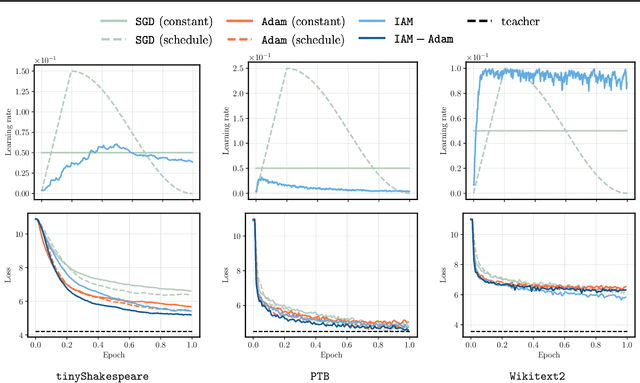

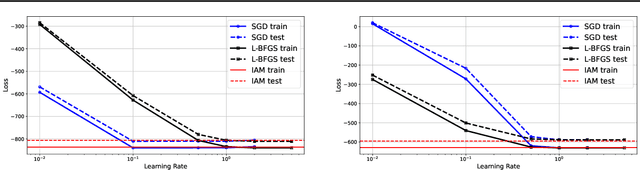
We provide a general convergence theorem of an idealized stochastic Polyak step size called SPS$^*$. Besides convexity, we only assume a local expected gradient bound, that includes locally smooth and locally Lipschitz losses as special cases. We refer to SPS$^*$ as idealized because it requires access to the loss for every training batch evaluated at a solution. It is also ideal, in that it achieves the optimal lower bound for globally Lipschitz function, and is the first Polyak step size to have an $O(1/\sqrt{t})$ anytime convergence in the smooth setting. We show how to combine SPS$^*$ with momentum to achieve the same favorable rates for the last iterate. We conclude with several experiments to validate our theory, and a more practical setting showing how we can distill a teacher GPT-2 model into a smaller student model without any hyperparameter tuning.
EigenVI: score-based variational inference with orthogonal function expansions
Oct 31, 2024


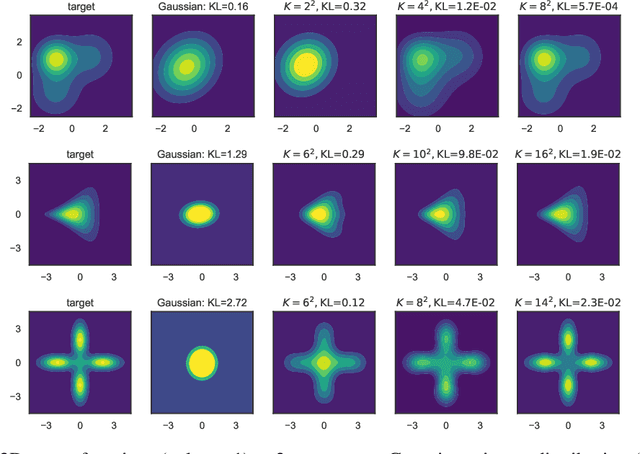
We develop EigenVI, an eigenvalue-based approach for black-box variational inference (BBVI). EigenVI constructs its variational approximations from orthogonal function expansions. For distributions over $\mathbb{R}^D$, the lowest order term in these expansions provides a Gaussian variational approximation, while higher-order terms provide a systematic way to model non-Gaussianity. These approximations are flexible enough to model complex distributions (multimodal, asymmetric), but they are simple enough that one can calculate their low-order moments and draw samples from them. EigenVI can also model other types of random variables (e.g., nonnegative, bounded) by constructing variational approximations from different families of orthogonal functions. Within these families, EigenVI computes the variational approximation that best matches the score function of the target distribution by minimizing a stochastic estimate of the Fisher divergence. Notably, this optimization reduces to solving a minimum eigenvalue problem, so that EigenVI effectively sidesteps the iterative gradient-based optimizations that are required for many other BBVI algorithms. (Gradient-based methods can be sensitive to learning rates, termination criteria, and other tunable hyperparameters.) We use EigenVI to approximate a variety of target distributions, including a benchmark suite of Bayesian models from posteriordb. On these distributions, we find that EigenVI is more accurate than existing methods for Gaussian BBVI.
Enhancing Policy Gradient with the Polyak Step-Size Adaption
Apr 11, 2024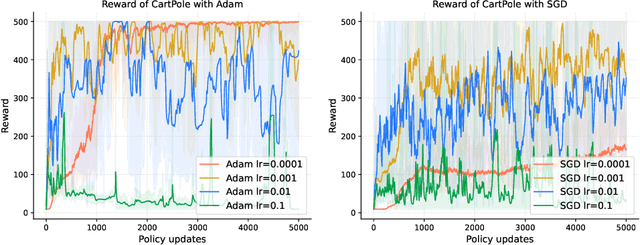
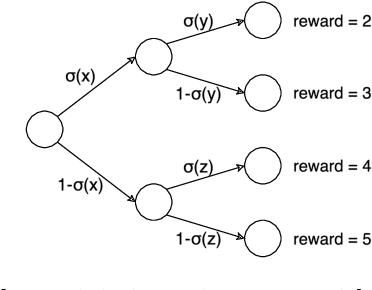
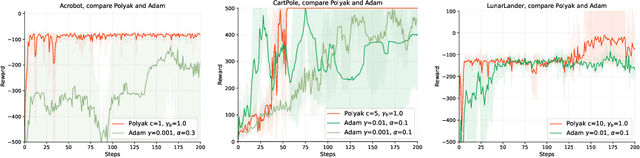
Policy gradient is a widely utilized and foundational algorithm in the field of reinforcement learning (RL). Renowned for its convergence guarantees and stability compared to other RL algorithms, its practical application is often hindered by sensitivity to hyper-parameters, particularly the step-size. In this paper, we introduce the integration of the Polyak step-size in RL, which automatically adjusts the step-size without prior knowledge. To adapt this method to RL settings, we address several issues, including unknown f* in the Polyak step-size. Additionally, we showcase the performance of the Polyak step-size in RL through experiments, demonstrating faster convergence and the attainment of more stable policies.
Directional Smoothness and Gradient Methods: Convergence and Adaptivity
Mar 06, 2024



We develop new sub-optimality bounds for gradient descent (GD) that depend on the conditioning of the objective along the path of optimization, rather than on global, worst-case constants. Key to our proofs is directional smoothness, a measure of gradient variation that we use to develop upper-bounds on the objective. Minimizing these upper-bounds requires solving implicit equations to obtain a sequence of strongly adapted step-sizes; we show that these equations are straightforward to solve for convex quadratics and lead to new guarantees for two classical step-sizes. For general functions, we prove that the Polyak step-size and normalized GD obtain fast, path-dependent rates despite using no knowledge of the directional smoothness. Experiments on logistic regression show our convergence guarantees are tighter than the classical theory based on L-smoothness.
Level Set Teleportation: An Optimization Perspective
Mar 05, 2024



We study level set teleportation, an optimization sub-routine which seeks to accelerate gradient methods by maximizing the gradient norm on a level-set of the objective function. Since the descent lemma implies that gradient descent (GD) decreases the objective proportional to the squared norm of the gradient, level-set teleportation maximizes this one-step progress guarantee. For convex functions satisfying Hessian stability, we prove that GD with level-set teleportation obtains a combined sub-linear/linear convergence rate which is strictly faster than standard GD when the optimality gap is small. This is in sharp contrast to the standard (strongly) convex setting, where we show level-set teleportation neither improves nor worsens convergence rates. To evaluate teleportation in practice, we develop a projected-gradient-type method requiring only Hessian-vector products. We use this method to show that gradient methods with access to a teleportation oracle uniformly out-perform their standard versions on a variety of learning problems.
Batch and match: black-box variational inference with a score-based divergence
Feb 22, 2024



Most leading implementations of black-box variational inference (BBVI) are based on optimizing a stochastic evidence lower bound (ELBO). But such approaches to BBVI often converge slowly due to the high variance of their gradient estimates. In this work, we propose batch and match (BaM), an alternative approach to BBVI based on a score-based divergence. Notably, this score-based divergence can be optimized by a closed-form proximal update for Gaussian variational families with full covariance matrices. We analyze the convergence of BaM when the target distribution is Gaussian, and we prove that in the limit of infinite batch size the variational parameter updates converge exponentially quickly to the target mean and covariance. We also evaluate the performance of BaM on Gaussian and non-Gaussian target distributions that arise from posterior inference in hierarchical and deep generative models. In these experiments, we find that BaM typically converges in fewer (and sometimes significantly fewer) gradient evaluations than leading implementations of BBVI based on ELBO maximization.
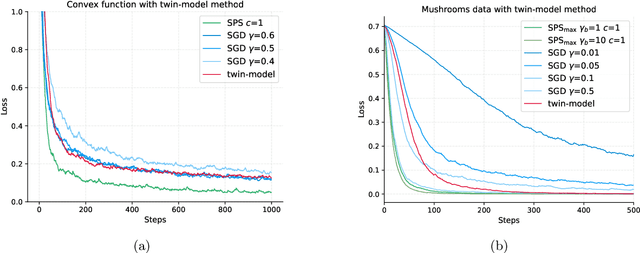
Function Value Learning: Adaptive Learning Rates Based on the Polyak Stepsize and Function Splitting in ERM
Jul 26, 2023

Here we develop variants of SGD (stochastic gradient descent) with an adaptive step size that make use of the sampled loss values. In particular, we focus on solving a finite sum-of-terms problem, also known as empirical risk minimization. We first detail an idealized adaptive method called $\texttt{SPS}_+$ that makes use of the sampled loss values and assumes knowledge of the sampled loss at optimality. This $\texttt{SPS}_+$ is a minor modification of the SPS (Stochastic Polyak Stepsize) method, where the step size is enforced to be positive. We then show that $\texttt{SPS}_+$ achieves the best known rates of convergence for SGD in the Lipschitz non-smooth. We then move onto to develop $\texttt{FUVAL}$, a variant of $\texttt{SPS}_+$ where the loss values at optimality are gradually learned, as opposed to being given. We give three viewpoints of $\texttt{FUVAL}$, as a projection based method, as a variant of the prox-linear method, and then as a particular online SGD method. We then present a convergence analysis of $\texttt{FUVAL}$ and experimental results. The shortcomings of our work is that the convergence analysis of $\texttt{FUVAL}$ shows no advantage over SGD. Another shortcomming is that currently only the full batch version of $\texttt{FUVAL}$ shows a minor advantages of GD (Gradient Descent) in terms of sensitivity to the step size. The stochastic version shows no clear advantage over SGD. We conjecture that large mini-batches are required to make $\texttt{FUVAL}$ competitive. Currently the new $\texttt{FUVAL}$ method studied in this paper does not offer any clear theoretical or practical advantage. We have chosen to make this draft available online nonetheless because of some of the analysis techniques we use, such as the non-smooth analysis of $\texttt{SPS}_+$, and also to show an apparently interesting approach that currently does not work.