Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Policy Gradient with the Polyak Step-Size Adaption
Paper and Code
Apr 11, 2024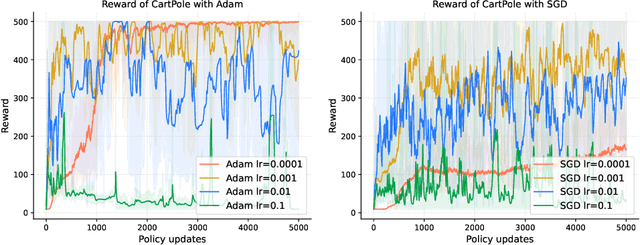
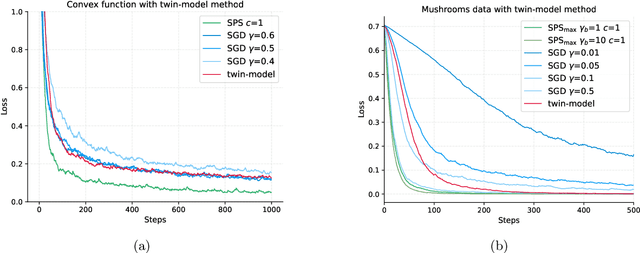
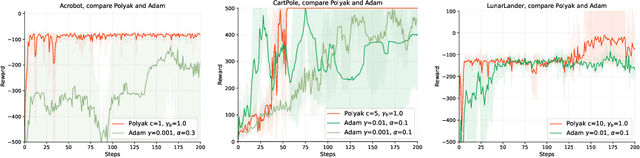
Policy gradient is a widely utilized and foundational algorithm in the field of reinforcement learning (RL). Renowned for its convergence guarantees and stability compared to other RL algorithms, its practical application is often hindered by sensitivity to hyper-parameters, particularly the step-size. In this paper, we introduce the integration of the Polyak step-size in RL, which automatically adjusts the step-size without prior knowledge. To adapt this method to RL settings, we address several issues, including unknown f* in the Polyak step-size. Additionally, we showcase the performance of the Polyak step-size in RL through experiments, demonstrating faster convergence and the attainment of more stable policies.
View paper on