 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Unified Parametric Assumption for Nonconvex Optimization
Feb 17, 2025Nonconvex optimization is central to modern machine learning, but the general framework of nonconvex optimization yields weak convergence guarantees that are too pessimistic compared to practice. On the other hand, while convexity enables efficient optimization, it is of limited applicability to many practical problems. To bridge this gap and better understand the practical success of optimization algorithms in nonconvex settings, we introduce a novel unified parametric assumption. Our assumption is general enough to encompass a broad class of nonconvex functions while also being specific enough to enable the derivation of a unified convergence theorem for gradient-based methods. Notably, by tuning the parameters of our assumption, we demonstrate its versatility in recovering several existing function classes as special cases and in identifying functions amenable to efficient optimization. We derive our convergence theorem for both deterministic and stochastic optimization, and conduct experiments to verify that our assumption can hold practically over optimization trajectories.
The Road Less Scheduled
May 24, 2024Existing learning rate schedules that do not require specification of the optimization stopping step T are greatly out-performed by learning rate schedules that depend on T. We propose an approach that avoids the need for this stopping time by eschewing the use of schedules entirely, while exhibiting state-of-the-art performance compared to schedules across a wide family of problems ranging from convex problems to large-scale deep learning problems. Our Schedule-Free approach introduces no additional hyper-parameters over standard optimizers with momentum. Our method is a direct consequence of a new theory we develop that unifies scheduling and iterate averaging. An open source implementation of our method is available (https://github.com/facebookresearch/schedule_free).
Directional Smoothness and Gradient Methods: Convergence and Adaptivity
Mar 06, 2024



We develop new sub-optimality bounds for gradient descent (GD) that depend on the conditioning of the objective along the path of optimization, rather than on global, worst-case constants. Key to our proofs is directional smoothness, a measure of gradient variation that we use to develop upper-bounds on the objective. Minimizing these upper-bounds requires solving implicit equations to obtain a sequence of strongly adapted step-sizes; we show that these equations are straightforward to solve for convex quadratics and lead to new guarantees for two classical step-sizes. For general functions, we prove that the Polyak step-size and normalized GD obtain fast, path-dependent rates despite using no knowledge of the directional smoothness. Experiments on logistic regression show our convergence guarantees are tighter than the classical theory based on L-smoothness.
Tuning-Free Stochastic Optimization
Feb 12, 2024Large-scale machine learning problems make the cost of hyperparameter tuning ever more prohibitive. This creates a need for algorithms that can tune themselves on-the-fly. We formalize the notion of "tuning-free" algorithms that can match the performance of optimally-tuned optimization algorithms up to polylogarithmic factors given only loose hints on the relevant problem parameters. We consider in particular algorithms that can match optimally-tuned Stochastic Gradient Descent (SGD). When the domain of optimization is bounded, we show tuning-free matching of SGD is possible and achieved by several existing algorithms. We prove that for the task of minimizing a convex and smooth or Lipschitz function over an unbounded domain, tuning-free optimization is impossible. We discuss conditions under which tuning-free optimization is possible even over unbounded domains. In particular, we show that the recently proposed DoG and DoWG algorithms are tuning-free when the noise distribution is sufficiently well-behaved. For the task of finding a stationary point of a smooth and potentially nonconvex function, we give a variant of SGD that matches the best-known high-probability convergence rate for tuned SGD at only an additional polylogarithmic cost. However, we also give an impossibility result that shows no algorithm can hope to match the optimal expected convergence rate for tuned SGD with high probability.
Dynamic Electro-Optic Analog Memory for Neuromorphic Photonic Computing
Jan 29, 2024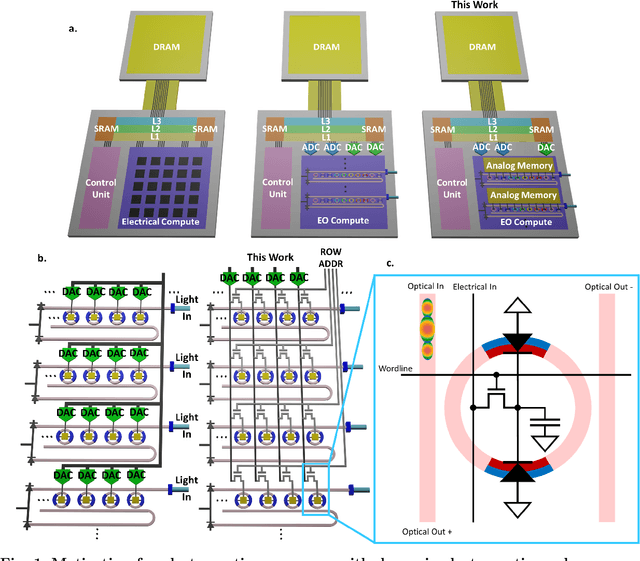

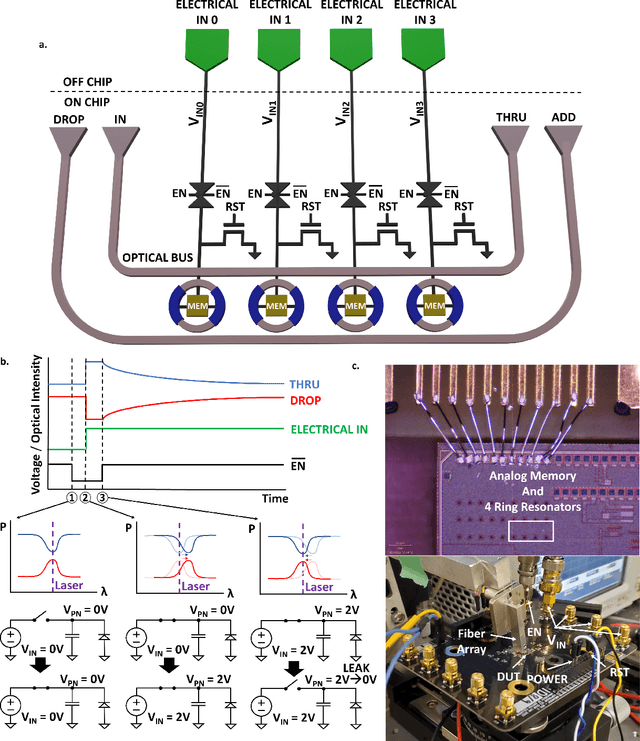
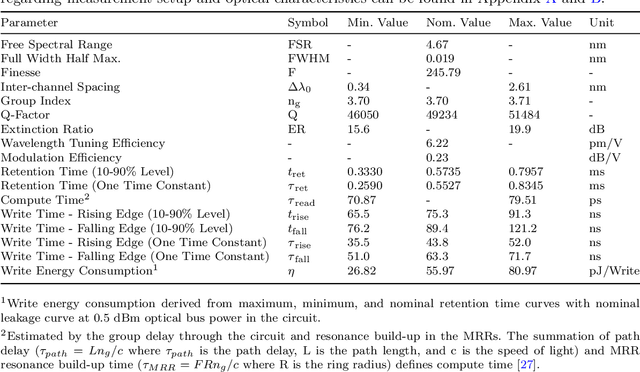
Artificial intelligence (AI) has seen remarkable advancements across various domains, including natural language processing, computer vision, autonomous vehicles, and biology. However, the rapid expansion of AI technologies has escalated the demand for more powerful computing resources. As digital computing approaches fundamental limits, neuromorphic photonics emerges as a promising platform to complement existing digital systems. In neuromorphic photonic computing, photonic devices are controlled using analog signals. This necessitates the use of digital-to-analog converters (DAC) and analog-to-digital converters (ADC) for interfacing with these devices during inference and training. However, data movement between memory and these converters in conventional von Neumann computing architectures consumes energy. To address this, analog memory co-located with photonic computing devices is proposed. This approach aims to reduce the reliance on DACs and ADCs and minimize data movement to enhance compute efficiency. This paper demonstrates a monolithically integrated neuromorphic photonic circuit with co-located capacitive analog memory and compares various analog memory technologies for neuromorphic photonic computing using the MNIST dataset as a benchmark.
DoWG Unleashed: An Efficient Universal Parameter-Free Gradient Descent Method
May 25, 2023This paper proposes a new easy-to-implement parameter-free gradient-based optimizer: DoWG (Distance over Weighted Gradients). We prove that DoWG is efficient -- matching the convergence rate of optimally tuned gradient descent in convex optimization up to a logarithmic factor without tuning any parameters, and universal -- automatically adapting to both smooth and nonsmooth problems. While popular algorithms such as AdaGrad, Adam, or DoG compute a running average of the squared gradients, DoWG maintains a new distance-based weighted version of the running average, which is crucial to achieve the desired properties. To our best knowledge, DoWG is the first parameter-free, efficient, and universal algorithm that does not require backtracking search procedures. It is also the first parameter-free AdaGrad style algorithm that adapts to smooth optimization. To complement our theory, we also show empirically that DoWG trains at the edge of stability, and validate its effectiveness on practical machine learning tasks. This paper further uncovers the underlying principle behind the success of the AdaGrad family of algorithms by presenting a novel analysis of Normalized Gradient Descent (NGD), that shows NGD adapts to smoothness when it exists, with no change to the stepsize. This establishes the universality of NGD and partially explains the empirical observation that it trains at the edge of stability in a much more general setup compared to standard gradient descent. The latter might be of independent interest to the community.
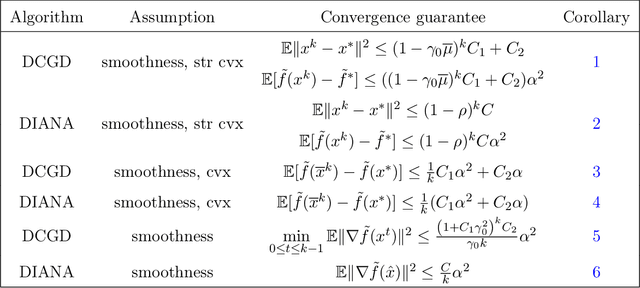
Faster federated optimization under second-order similarity
Sep 06, 2022
Federated learning (FL) is a subfield of machine learning where multiple clients try to collaboratively learn a model over a network under communication constraints. We consider finite-sum federated optimization under a second-order function similarity condition and strong convexity, and propose two new algorithms: SVRP and Catalyzed SVRP. This second-order similarity condition has grown popular recently, and is satisfied in many applications including distributed statistical learning and differentially private empirical risk minimization. The first algorithm, SVRP, combines approximate stochastic proximal point evaluations, client sampling, and variance reduction. We show that SVRP is communication efficient and achieves superior performance to many existing algorithms when function similarity is high enough. Our second algorithm, Catalyzed SVRP, is a Catalyst-accelerated variant of SVRP that achieves even better performance and uniformly improves upon existing algorithms for federated optimization under second-order similarity and strong convexity. In the course of analyzing these algorithms, we provide a new analysis of the Stochastic Proximal Point Method (SPPM) that might be of independent interest. Our analysis of SPPM is simple, allows for approximate proximal point evaluations, does not require any smoothness assumptions, and shows a clear benefit in communication complexity over ordinary distributed stochastic gradient descent.
Federated Optimization Algorithms with Random Reshuffling and Gradient Compression
Jun 14, 2022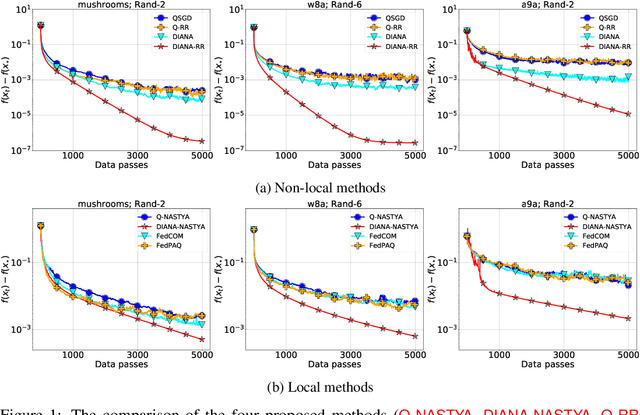


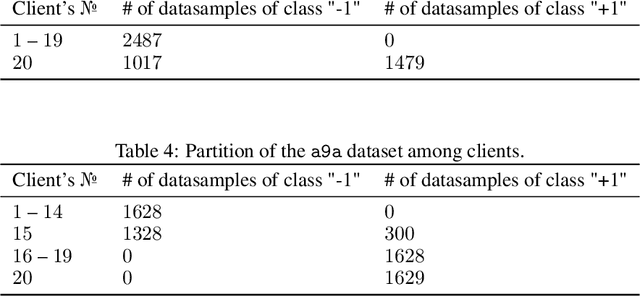
Gradient compression is a popular technique for improving communication complexity of stochastic first-order methods in distributed training of machine learning models. However, the existing works consider only with-replacement sampling of stochastic gradients. In contrast, it is well-known in practice and recently confirmed in theory that stochastic methods based on without-replacement sampling, e.g., Random Reshuffling (RR) method, perform better than ones that sample the gradients with-replacement. In this work, we close this gap in the literature and provide the first analysis of methods with gradient compression and without-replacement sampling. We first develop a distributed variant of random reshuffling with gradient compression (Q-RR), and show how to reduce the variance coming from gradient quantization through the use of control iterates. Next, to have a better fit to Federated Learning applications, we incorporate local computation and propose a variant of Q-RR called Q-NASTYA. Q-NASTYA uses local gradient steps and different local and global stepsizes. Next, we show how to reduce compression variance in this setting as well. Finally, we prove the convergence results for the proposed methods and outline several settings in which they improve upon existing algorithms.
FLIX: A Simple and Communication-Efficient Alternative to Local Methods in Federated Learning
Nov 22, 2021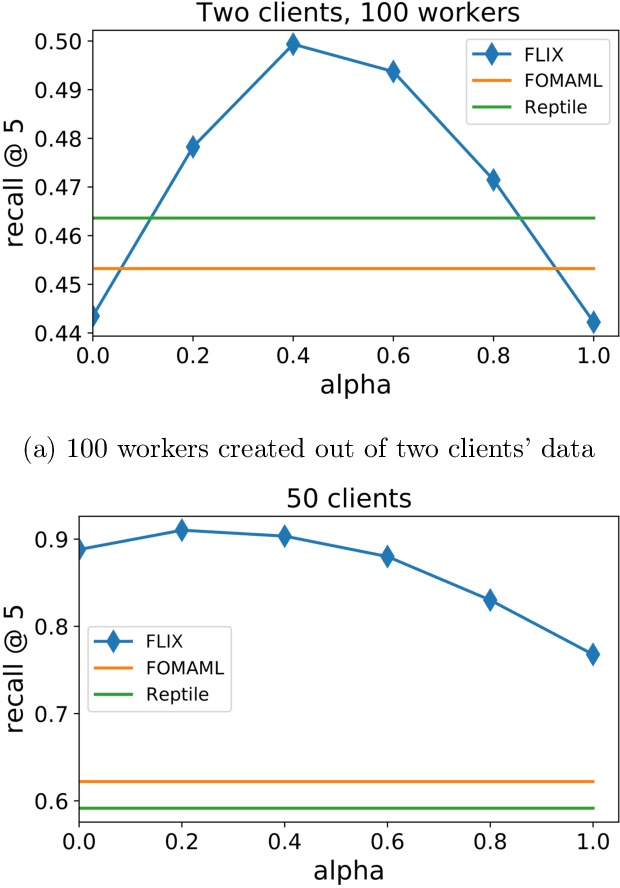
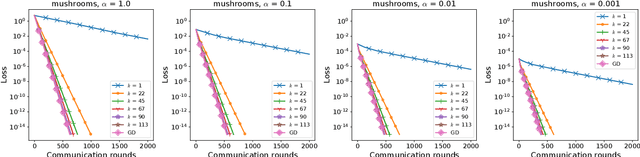
Federated Learning (FL) is an increasingly popular machine learning paradigm in which multiple nodes try to collaboratively learn under privacy, communication and multiple heterogeneity constraints. A persistent problem in federated learning is that it is not clear what the optimization objective should be: the standard average risk minimization of supervised learning is inadequate in handling several major constraints specific to federated learning, such as communication adaptivity and personalization control. We identify several key desiderata in frameworks for federated learning and introduce a new framework, FLIX, that takes into account the unique challenges brought by federated learning. FLIX has a standard finite-sum form, which enables practitioners to tap into the immense wealth of existing (potentially non-local) methods for distributed optimization. Through a smart initialization that does not require any communication, FLIX does not require the use of local steps but is still provably capable of performing dissimilarity regularization on par with local methods. We give several algorithms for solving the FLIX formulation efficiently under communication constraints. Finally, we corroborate our theoretical results with extensive experimentation.
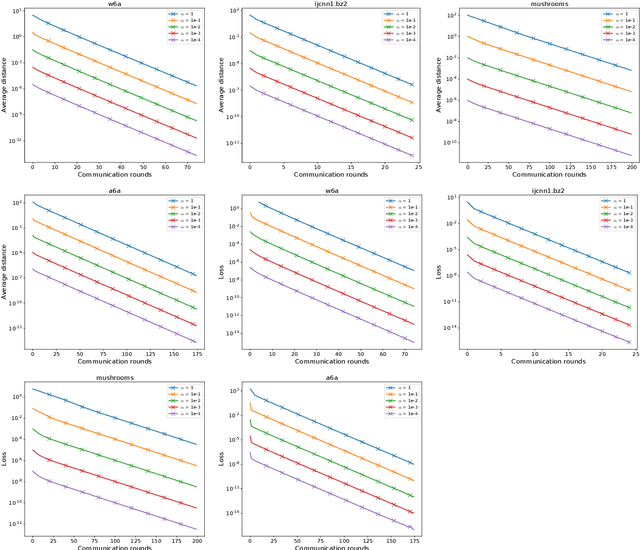
Proximal and Federated Random Reshuffling
Feb 12, 2021
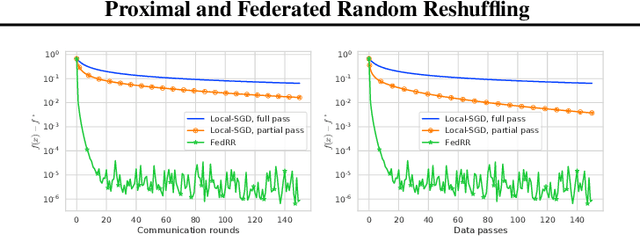
Random Reshuffling (RR), also known as Stochastic Gradient Descent (SGD) without replacement, is a popular and theoretically grounded method for finite-sum minimization. We propose two new algorithms: Proximal and Federated Random Reshuffing (ProxRR and FedRR). The first algorithm, ProxRR, solves composite convex finite-sum minimization problems in which the objective is the sum of a (potentially non-smooth) convex regularizer and an average of $n$ smooth objectives. We obtain the second algorithm, FedRR, as a special case of ProxRR applied to a reformulation of distributed problems with either homogeneous or heterogeneous data. We study the algorithms' convergence properties with constant and decreasing stepsizes, and show that they have considerable advantages over Proximal and Local SGD. In particular, our methods have superior complexities and ProxRR evaluates the proximal operator once per epoch only. When the proximal operator is expensive to compute, this small difference makes ProxRR up to $n$ times faster than algorithms that evaluate the proximal operator in every iteration. We give examples of practical optimization tasks where the proximal operator is difficult to compute and ProxRR has a clear advantage. Finally, we corroborate our results with experiments on real data sets.