 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Electro-Optic Analog Memory for Neuromorphic Photonic Computing
Jan 29, 2024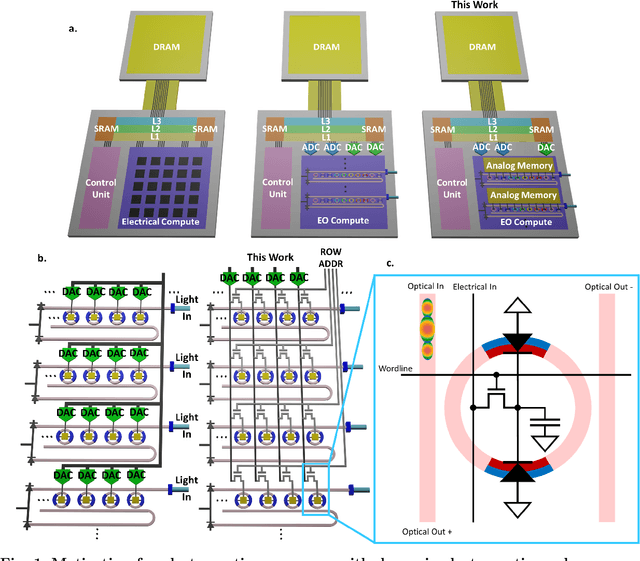

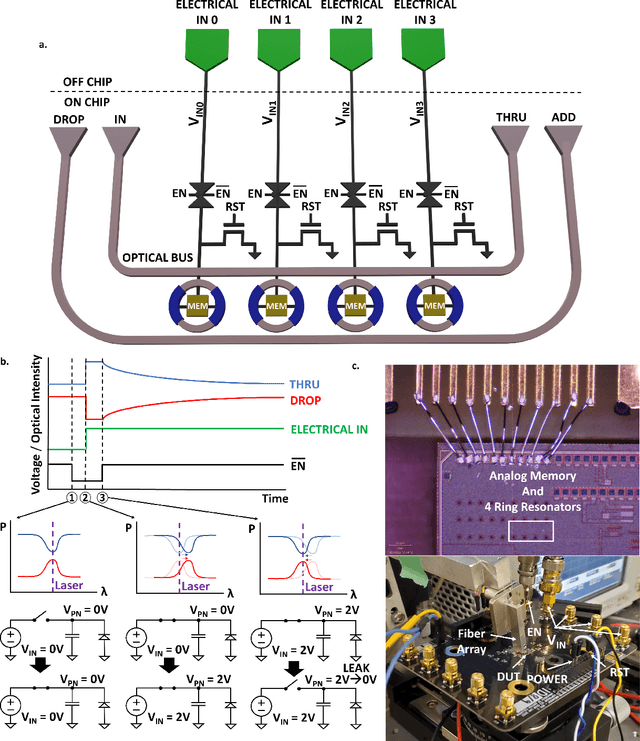
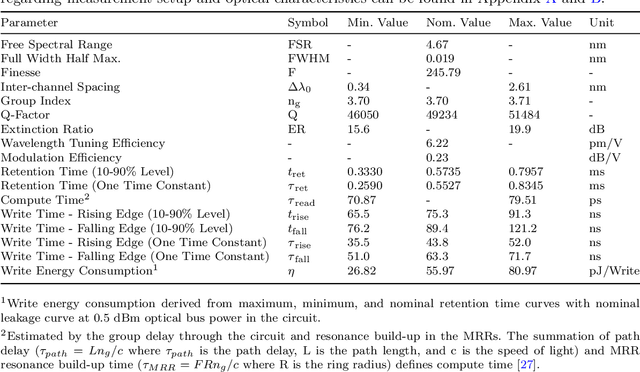
Artificial intelligence (AI) has seen remarkable advancements across various domains, including natural language processing, computer vision, autonomous vehicles, and biology. However, the rapid expansion of AI technologies has escalated the demand for more powerful computing resources. As digital computing approaches fundamental limits, neuromorphic photonics emerges as a promising platform to complement existing digital systems. In neuromorphic photonic computing, photonic devices are controlled using analog signals. This necessitates the use of digital-to-analog converters (DAC) and analog-to-digital converters (ADC) for interfacing with these devices during inference and training. However, data movement between memory and these converters in conventional von Neumann computing architectures consumes energy. To address this, analog memory co-located with photonic computing devices is proposed. This approach aims to reduce the reliance on DACs and ADCs and minimize data movement to enhance compute efficiency. This paper demonstrates a monolithically integrated neuromorphic photonic circuit with co-located capacitive analog memory and compares various analog memory technologies for neuromorphic photonic computing using the MNIST dataset as a benchmark.
Monolithic Silicon Photonic Architecture for Training Deep Neural Networks with Direct Feedback Alignment
Nov 12, 2021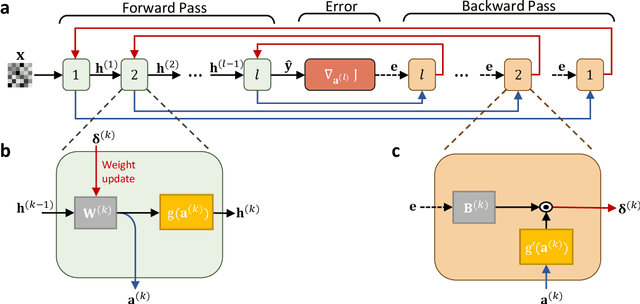
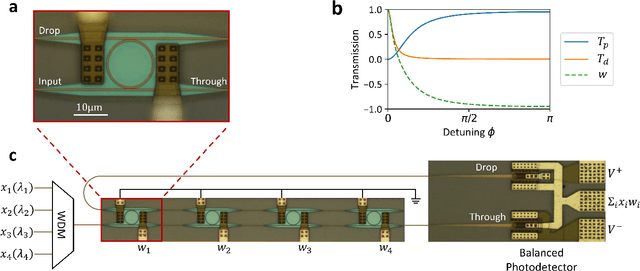
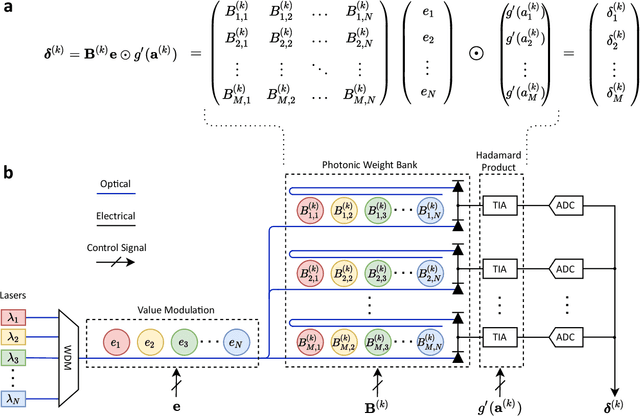
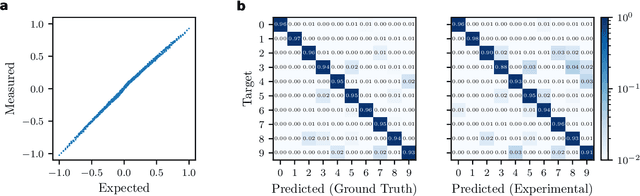
The field of artificial intelligence (AI) has witnessed tremendous growth in recent years, however some of the most pressing challenges for the continued development of AI systems are the fundamental bandwidth, energy efficiency, and speed limitations faced by electronic computer architectures. There has been growing interest in using photonic processors for performing neural network inference operations, however these networks are currently trained using standard digital electronics. Here, we propose on-chip training of neural networks enabled by a CMOS-compatible silicon photonic architecture to harness the potential for massively parallel, efficient, and fast data operations. Our scheme employs the direct feedback alignment training algorithm, which trains neural networks using error feedback rather than error backpropagation, and can operate at speeds of trillions of multiply-accumulate (MAC) operations per second while consuming less than one picojoule per MAC operation. The photonic architecture exploits parallelized matrix-vector multiplications using arrays of microring resonators for processing multi-channel analog signals along single waveguide buses to calculate the gradient vector of each neural network layer in situ, which is the most computationally expensive operation performed during the backward pass. We also experimentally demonstrate training a deep neural network with the MNIST dataset using on-chip MAC operation results. Our novel approach for efficient, ultra-fast neural network training showcases photonics as a promising platform for executing AI applications.
Takens-inspired neuromorphic processor: a downsizing tool for random recurrent neural networks via feature extraction
Jul 06, 2019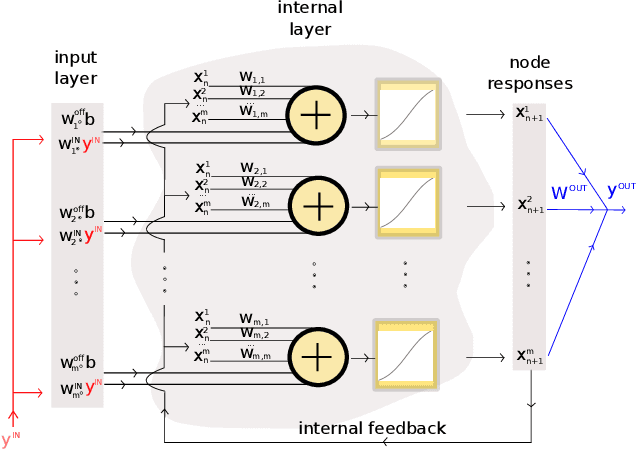
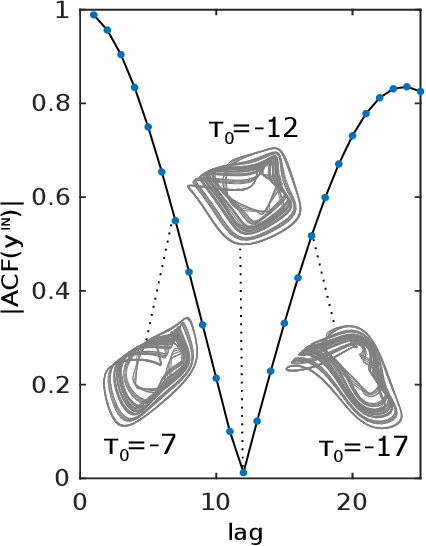


We describe a new technique which minimizes the amount of neurons in the hidden layer of a random recurrent neural network (rRNN) for time series prediction. Merging Takens-based attractor reconstruction methods with machine learning, we identify a mechanism for feature extraction that can be leveraged to lower the network size. We obtain criteria specific to the particular prediction task and derive the scaling law of the prediction error. The consequences of our theory are demonstrated by designing a Takens-inspired hybrid processor, which extends a rRNN with a priori designed delay external memory. Our hybrid architecture is therefore designed including both, real and virtual nodes. Via this symbiosis, we show performance of the hybrid processor by stabilizing an arrhythmic neural model. Thanks to our obtained design rules, we can reduce the stabilizing neural network's size by a factor of 15 with respect to a standard system.