 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRole of Spatial Coherence in Diffractive Optical Neural Networks
Oct 05, 2023Diffractive optical neural networks (DONNs) have emerged as a promising optical hardware platform for ultra-fast and energy-efficient signal processing for machine learning tasks, particularly in computer vision. However, previous experimental demonstrations of DONNs have only been performed using coherent light, which is not present in the natural world. Here, we study the role of spatial optical coherence in DONN operation. We propose a numerical approach to efficiently simulate DONNs under input illumination with arbitrary spatial coherence and discuss the corresponding computational complexity using coherent, partially coherent, and incoherent light. We also investigate the expressive power of DONNs and examine how coherence affects their performance. In particular, we show that under fully incoherent illumination, the DONN performance cannot surpass that of a linear model. As a demonstration, we train and evaluate simulated DONNs on the MNIST dataset of handwritten digits using light with varying spatial coherence.
Scaling Laws Beyond Backpropagation
Oct 26, 2022Alternatives to backpropagation have long been studied to better understand how biological brains may learn. Recently, they have also garnered interest as a way to train neural networks more efficiently. By relaxing constraints inherent to backpropagation (e.g., symmetric feedforward and feedback weights, sequential updates), these methods enable promising prospects, such as local learning. However, the tradeoffs between different methods in terms of final task performance, convergence speed, and ultimately compute and data requirements are rarely outlined. In this work, we use scaling laws to study the ability of Direct Feedback Alignment~(DFA) to train causal decoder-only Transformers efficiently. Scaling laws provide an overview of the tradeoffs implied by a modeling decision, up to extrapolating how it might transfer to increasingly large models. We find that DFA fails to offer more efficient scaling than backpropagation: there is never a regime for which the degradation in loss incurred by using DFA is worth the potential reduction in compute budget. Our finding comes at variance with previous beliefs in the alternative training methods community, and highlights the need for holistic empirical approaches to better understand modeling decisions.
Monolithic Silicon Photonic Architecture for Training Deep Neural Networks with Direct Feedback Alignment
Nov 12, 2021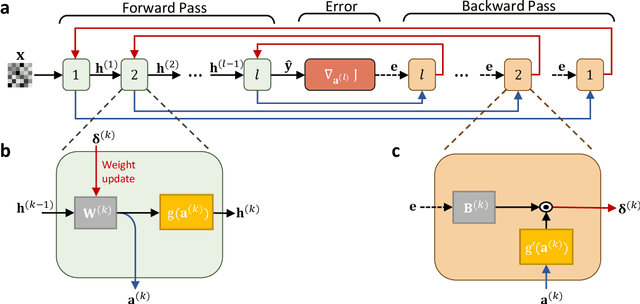
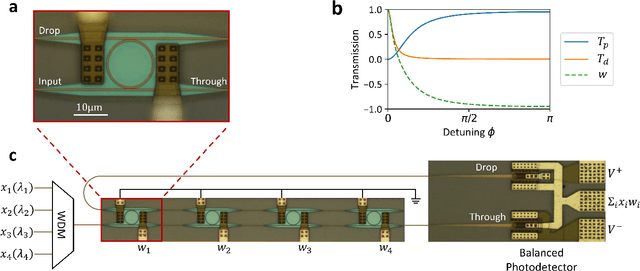
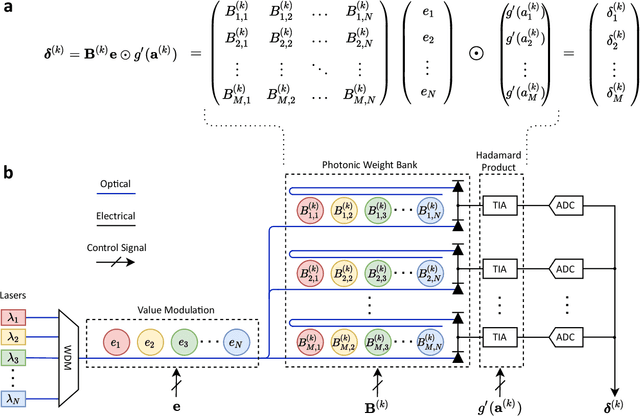
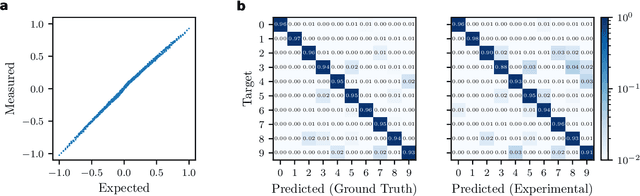
The field of artificial intelligence (AI) has witnessed tremendous growth in recent years, however some of the most pressing challenges for the continued development of AI systems are the fundamental bandwidth, energy efficiency, and speed limitations faced by electronic computer architectures. There has been growing interest in using photonic processors for performing neural network inference operations, however these networks are currently trained using standard digital electronics. Here, we propose on-chip training of neural networks enabled by a CMOS-compatible silicon photonic architecture to harness the potential for massively parallel, efficient, and fast data operations. Our scheme employs the direct feedback alignment training algorithm, which trains neural networks using error feedback rather than error backpropagation, and can operate at speeds of trillions of multiply-accumulate (MAC) operations per second while consuming less than one picojoule per MAC operation. The photonic architecture exploits parallelized matrix-vector multiplications using arrays of microring resonators for processing multi-channel analog signals along single waveguide buses to calculate the gradient vector of each neural network layer in situ, which is the most computationally expensive operation performed during the backward pass. We also experimentally demonstrate training a deep neural network with the MNIST dataset using on-chip MAC operation results. Our novel approach for efficient, ultra-fast neural network training showcases photonics as a promising platform for executing AI applications.