 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotoFourier: A Photonic Joint Transform Correlator-Based Neural Network Accelerator
Nov 10, 2022The last few years have seen a lot of work to address the challenge of low-latency and high-throughput convolutional neural network inference. Integrated photonics has the potential to dramatically accelerate neural networks because of its low-latency nature. Combined with the concept of Joint Transform Correlator (JTC), the computationally expensive convolution functions can be computed instantaneously (time of flight of light) with almost no cost. This 'free' convolution computation provides the theoretical basis of the proposed PhotoFourier JTC-based CNN accelerator. PhotoFourier addresses a myriad of challenges posed by on-chip photonic computing in the Fourier domain including 1D lenses and high-cost optoelectronic conversions. The proposed PhotoFourier accelerator achieves more than 28X better energy-delay product compared to state-of-art photonic neural network accelerators.
Batch Processing and Data Streaming Fourier-based Convolutional Neural Network Accelerator
Dec 23, 2021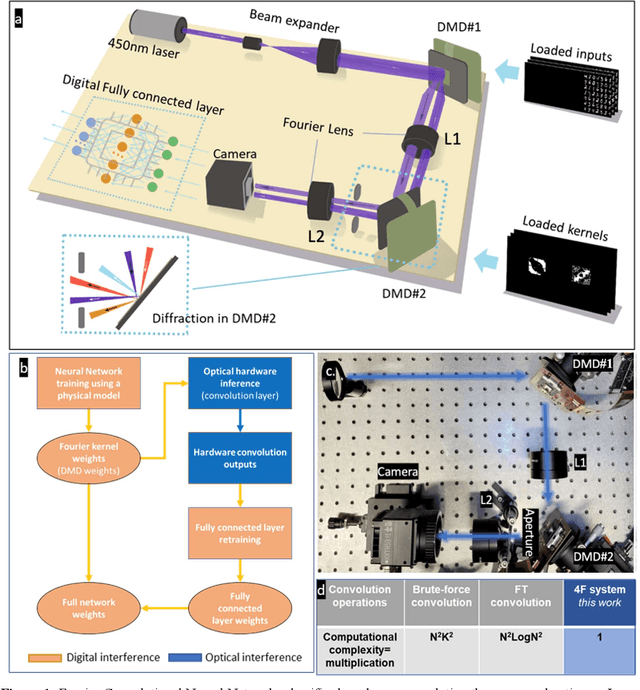

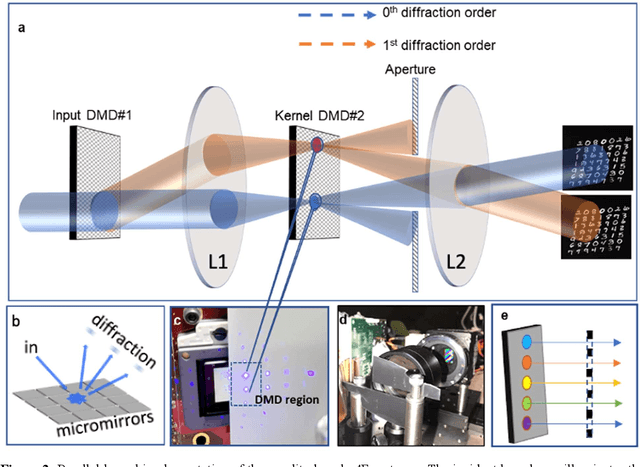
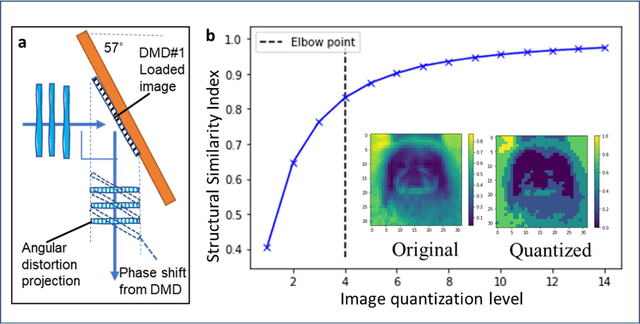
Decision-making by artificial neural networks with minimal latency is paramount for numerous applications such as navigation, tracking, and real-time machine action systems. This requires the machine learning hardware to handle multidimensional data with a high throughput. Processing convolution operations being the major computational tool for data classification tasks, unfortunately, follows a challenging run-time complexity scaling law. However, implementing the convolution theorem homomorphically in a Fourier-optic display-light-processor enables a non-iterative O(1) runtime complexity for data inputs beyond 1,000 x 1,000 large matrices. Following this approach, here we demonstrate data streaming multi-kernel image batch-processing with a Fourier Convolutional Neural Network (FCNN) accelerator. We show image batch processing of large-scale matrices as passive 2-million dot-product multiplications performed by digital light-processing modules in the Fourier domain. In addition, we parallelize this optical FCNN system further by utilizing multiple spatio-parallel diffraction orders, thus achieving a 98-times throughput improvement over state-of-art FCNN accelerators. The comprehensive discussion of the practical challenges related to working on the edge of the system's capabilities highlights issues of crosstalk in the Fourier domain and resolution scaling laws. Accelerating convolutions by utilizing the massive parallelism in display technology brings forth a non-van Neuman-based machine learning acceleration.
Monolithic Silicon Photonic Architecture for Training Deep Neural Networks with Direct Feedback Alignment
Nov 12, 2021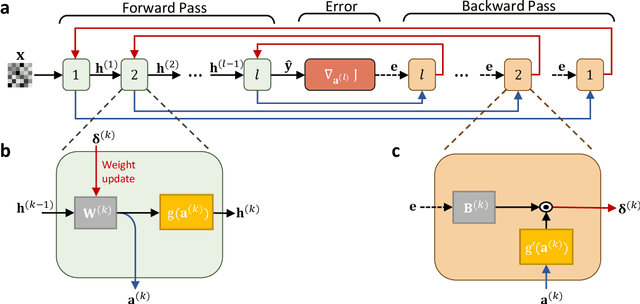
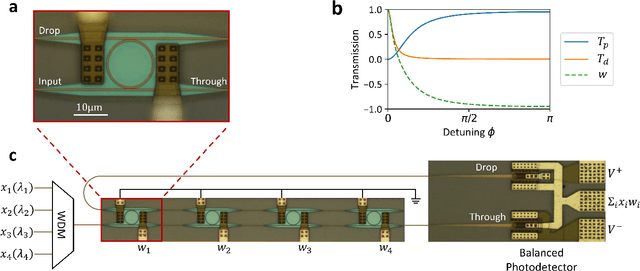
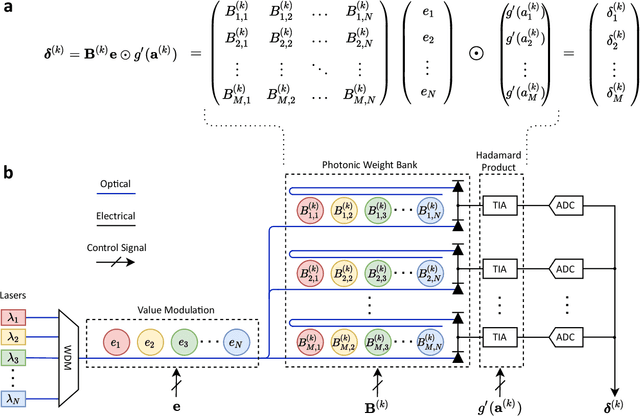
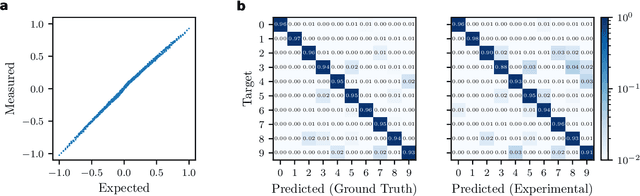
The field of artificial intelligence (AI) has witnessed tremendous growth in recent years, however some of the most pressing challenges for the continued development of AI systems are the fundamental bandwidth, energy efficiency, and speed limitations faced by electronic computer architectures. There has been growing interest in using photonic processors for performing neural network inference operations, however these networks are currently trained using standard digital electronics. Here, we propose on-chip training of neural networks enabled by a CMOS-compatible silicon photonic architecture to harness the potential for massively parallel, efficient, and fast data operations. Our scheme employs the direct feedback alignment training algorithm, which trains neural networks using error feedback rather than error backpropagation, and can operate at speeds of trillions of multiply-accumulate (MAC) operations per second while consuming less than one picojoule per MAC operation. The photonic architecture exploits parallelized matrix-vector multiplications using arrays of microring resonators for processing multi-channel analog signals along single waveguide buses to calculate the gradient vector of each neural network layer in situ, which is the most computationally expensive operation performed during the backward pass. We also experimentally demonstrate training a deep neural network with the MNIST dataset using on-chip MAC operation results. Our novel approach for efficient, ultra-fast neural network training showcases photonics as a promising platform for executing AI applications.
Photonic tensor cores for machine learning
Feb 01, 2020



With an ongoing trend in computing hardware towards increased heterogeneity, domain-specific co-processors are emerging as alternatives to centralized paradigms. The tensor core unit (TPU) has shown to outperform graphic process units by almost 3-orders of magnitude enabled by higher signal throughout and energy efficiency. In this context, photons bear a number of synergistic physical properties while phase-change materials allow for local nonvolatile mnemonic functionality in these emerging distributed non van-Neumann architectures. While several photonic neural network designs have been explored, a photonic TPU to perform matrix vector multiplication and summation is yet outstanding. Here we introduced an integrated photonics-based TPU by strategically utilizing a) photonic parallelism via wavelength division multiplexing, b) high 2 Peta-operations-per second throughputs enabled by 10s of picosecond-short delays from optoelectronics and compact photonic integrated circuitry, and c) zero power-consuming novel photonic multi-state memories based on phase-change materials featuring vanishing losses in the amorphous state. Combining these physical synergies of material, function, and system, we show that the performance of this 8-bit photonic TPU can be 2-3 orders higher compared to an electrical TPU whilst featuring similar chip areas. This work shows that photonic specialized processors have the potential to augment electronic systems and may perform exceptionally well in network-edge devices in the looming 5G networks and beyond.
A Winograd-based Integrated Photonics Accelerator for Convolutional Neural Networks
Jun 25, 2019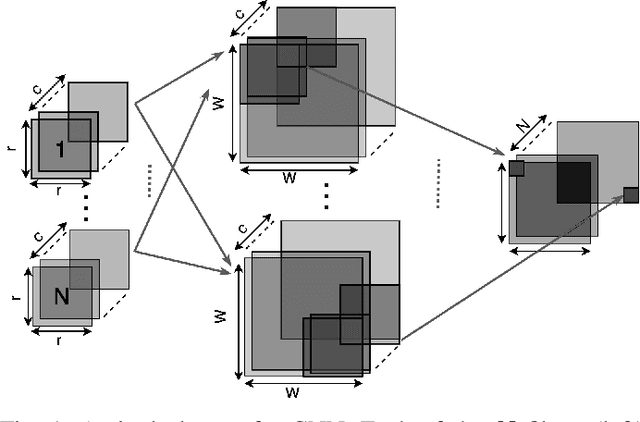
Neural Networks (NNs) have become the mainstream technology in the artificial intelligence (AI) renaissance over the past decade. Among different types of neural networks, convolutional neural networks (CNNs) have been widely adopted as they have achieved leading results in many fields such as computer vision and speech recognition. This success in part is due to the widespread availability of capable underlying hardware platforms. Applications have always been a driving factor for design of such hardware architectures. Hardware specialization can expose us to novel architectural solutions, which can outperform general purpose computers for tasks at hand. Although different applications demand for different performance measures, they all share speed and energy efficiency as high priorities. Meanwhile, photonics processing has seen a resurgence due to its inherited high speed and low power nature. Here, we investigate the potential of using photonics in CNNs by proposing a CNN accelerator design based on Winograd filtering algorithm. Our evaluation results show that while a photonic accelerator can compete with current-state-of-the-art electronic platforms in terms of both speed and power, it has the potential to improve the energy efficiency by up to three orders of magnitude.
Identifying Mirror Symmetry Density with Delay in Spiking Neural Networks
Aug 25, 2017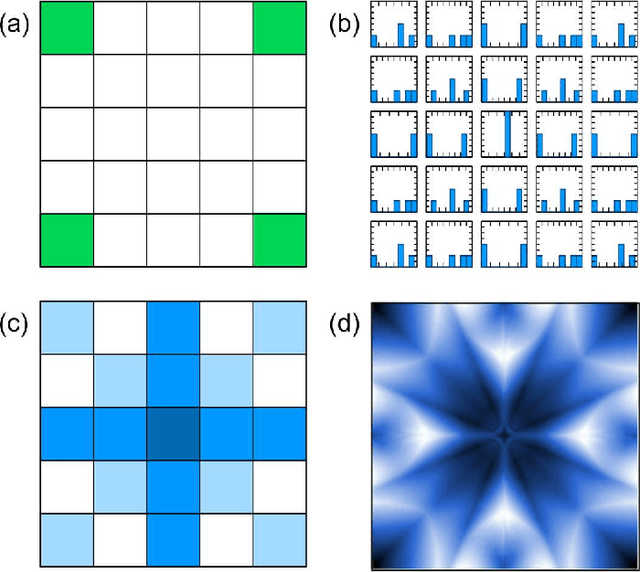
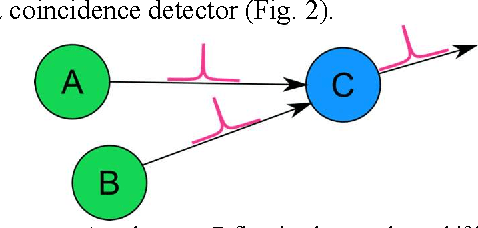
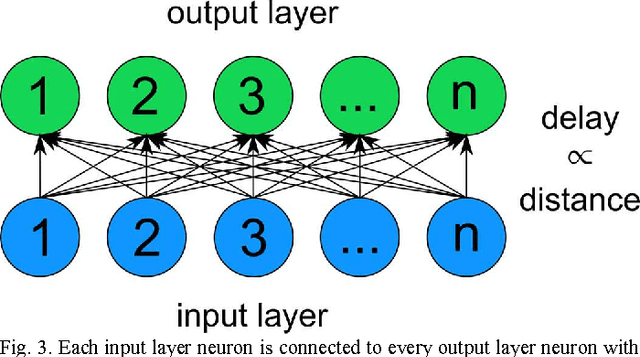
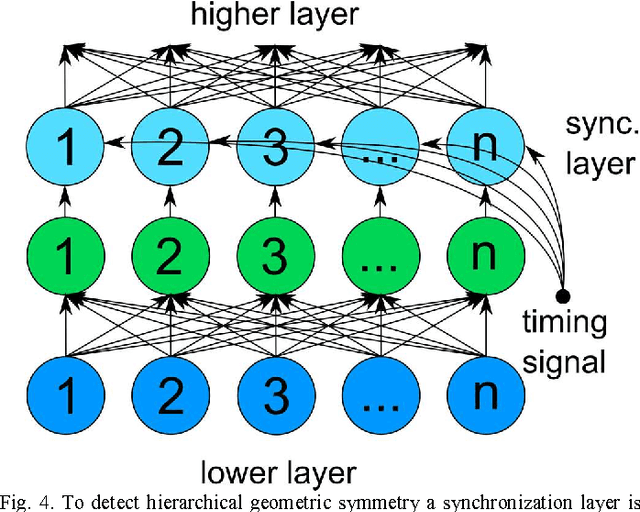
The ability to rapidly identify symmetry and anti-symmetry is an essential attribute of intelligence. Symmetry perception is a central process in human vision and may be key to human 3D visualization. While previous work in understanding neuron symmetry perception has concentrated on the neuron as an integrator, here we show how the coincidence detecting property of the spiking neuron can be used to reveal symmetry density in spatial data. We develop a method for synchronizing symmetry-identifying spiking artificial neural networks to enable layering and feedback in the network. We show a method for building a network capable of identifying symmetry density between sets of data and present a digital logic implementation demonstrating an 8x8 leaky-integrate-and-fire symmetry detector in a field programmable gate array. Our results show that the efficiencies of spiking neural networks can be harnessed to rapidly identify symmetry in spatial data with applications in image processing, 3D computer vision, and robotics.