 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024
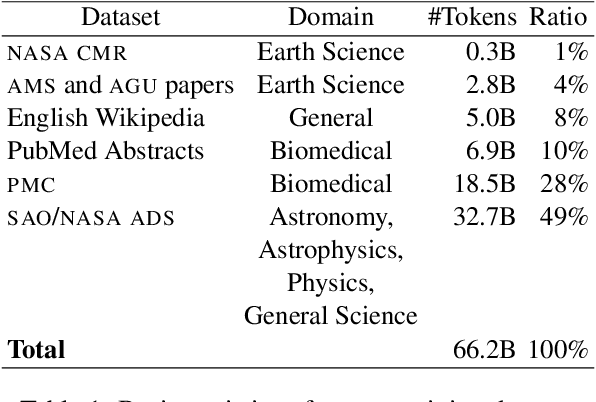
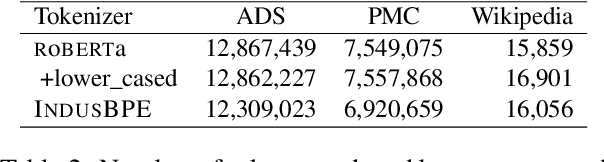

Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
A Winograd-based Integrated Photonics Accelerator for Convolutional Neural Networks
Jun 25, 2019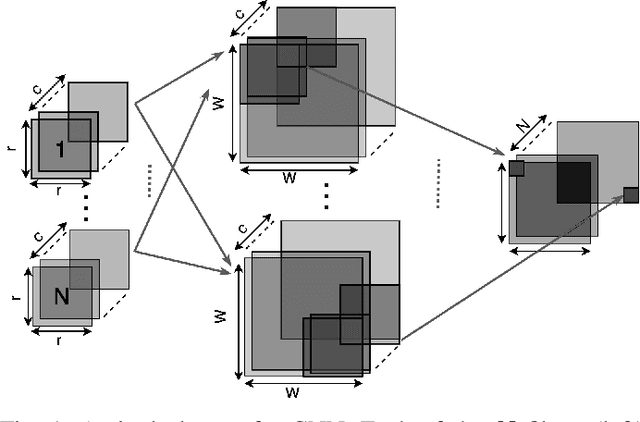
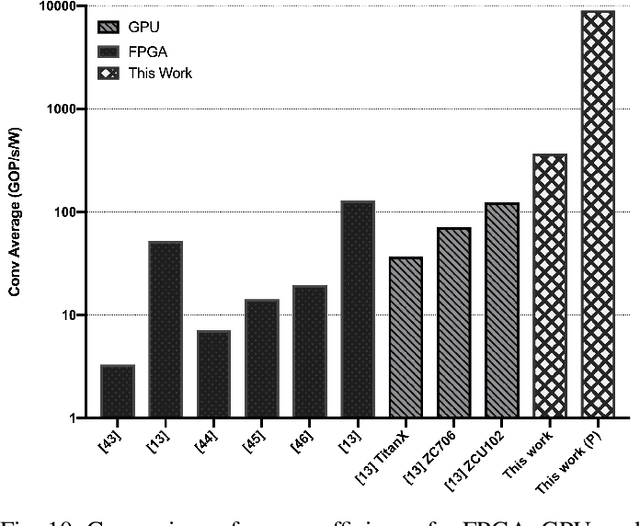
Neural Networks (NNs) have become the mainstream technology in the artificial intelligence (AI) renaissance over the past decade. Among different types of neural networks, convolutional neural networks (CNNs) have been widely adopted as they have achieved leading results in many fields such as computer vision and speech recognition. This success in part is due to the widespread availability of capable underlying hardware platforms. Applications have always been a driving factor for design of such hardware architectures. Hardware specialization can expose us to novel architectural solutions, which can outperform general purpose computers for tasks at hand. Although different applications demand for different performance measures, they all share speed and energy efficiency as high priorities. Meanwhile, photonics processing has seen a resurgence due to its inherited high speed and low power nature. Here, we investigate the potential of using photonics in CNNs by proposing a CNN accelerator design based on Winograd filtering algorithm. Our evaluation results show that while a photonic accelerator can compete with current-state-of-the-art electronic platforms in terms of both speed and power, it has the potential to improve the energy efficiency by up to three orders of magnitude.
PCNNA: A Photonic Convolutional Neural Network Accelerator
Jul 23, 2018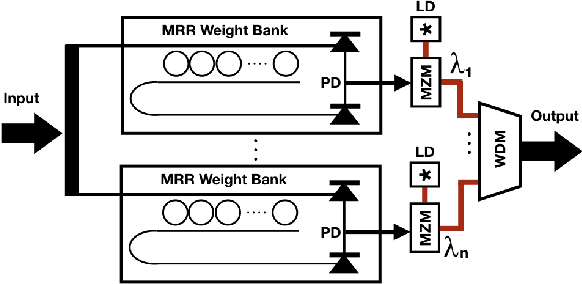
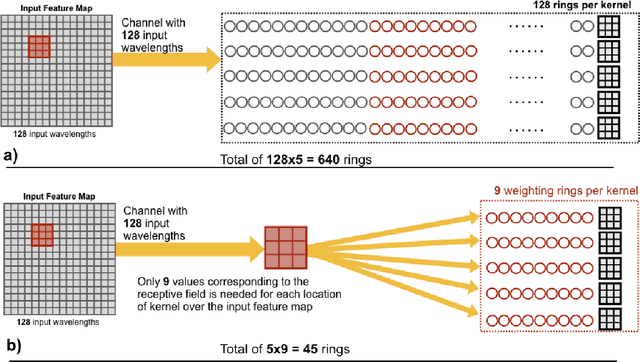
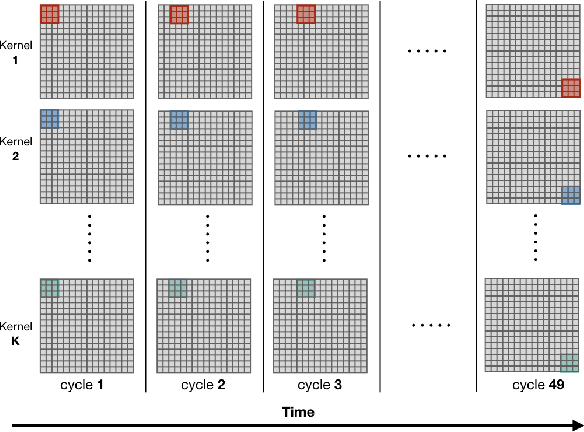
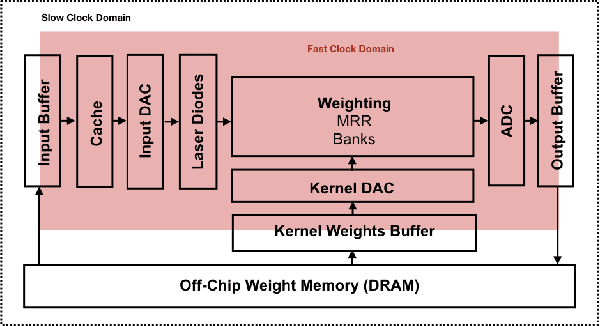
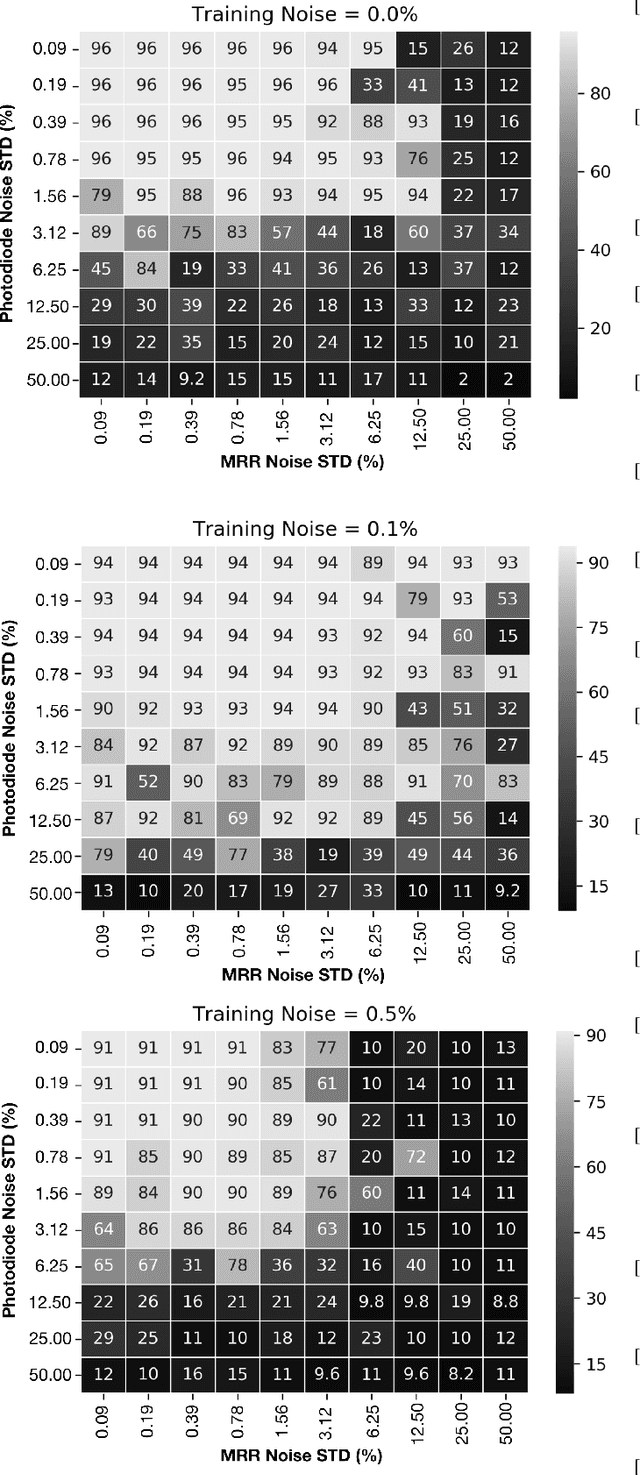
Convolutional Neural Networks (CNN) have been the centerpiece of many applications including but not limited to computer vision, speech processing, and Natural Language Processing (NLP). However, the computationally expensive convolution operations impose many challenges to the performance and scalability of CNNs. In parallel, photonic systems, which are traditionally employed for data communication, have enjoyed recent popularity for data processing due to their high bandwidth, low power consumption, and reconfigurability. Here we propose a Photonic Convolutional Neural Network Accelerator (PCNNA) as a proof of concept design to speedup the convolution operation for CNNs. Our design is based on the recently introduced silicon photonic microring weight banks, which use broadcast-and-weight protocol to perform Multiply And Accumulate (MAC) operation and move data through layers of a neural network. Here, we aim to exploit the synergy between the inherent parallelism of photonics in the form of Wavelength Division Multiplexing (WDM) and sparsity of connections between input feature maps and kernels in CNNs. While our full system design offers up to more than 3 orders of magnitude speedup in execution time, its optical core potentially offers more than 5 order of magnitude speedup compared to state-of-the-art electronic counterparts.