 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQoS-Efficient Serving of Multiple Mixture-of-Expert LLMs Using Partial Runtime Reconfiguration
May 10, 2025The deployment of mixture-of-experts (MoE) large language models (LLMs) presents significant challenges due to their high memory demands. These challenges become even more pronounced in multi-tenant environments, where shared resources must accommodate multiple models, limiting the effectiveness of conventional virtualization techniques. This paper addresses the problem of efficiently serving multiple fine-tuned MoE-LLMs on a single-GPU. We propose a serving system that employs \textit{similarity-based expert consolidation} to reduce the overall memory footprint by sharing similar experts across models. To ensure output quality, we introduce \textit{runtime partial reconfiguration}, dynamically replacing non-expert layers when processing requests from different models. As a result, our approach achieves a competitive output quality while maintaining throughput comparable to serving a single model while incurring a negligible increase in time-to-first-token (TTFT). Experiments on a server with a single NVIDIA A100 GPU (80GB) using Mixtral-8x7B models demonstrate an 85\% average reduction in turnaround time compared to NVIDIA's multi-instance GPU (MIG). Furthermore, experiments on Google's Switch Transformer Base-8 model with up to four variants demonstrate the scalability and resilience of our approach in maintaining output quality compared to other model merging baselines, highlighting its effectiveness.
Mixture of Experts with Mixture of Precisions for Tuning Quality of Service
Jul 19, 2024The increasing demand for deploying large Mixture-of-Experts (MoE) models in resource-constrained environments necessitates efficient approaches to address their high memory and computational requirements challenges. Moreover, given that tasks come in different user-defined constraints and the available resources change over time in multi-tenant environments, it is necessary to design an approach which provides a flexible configuration space. This paper presents an adaptive serving approach for the efficient deployment of MoE models, capitalizing on partial quantization of the experts. By dynamically determining the number of quantized experts and their distribution across CPU and GPU, our approach explores the Pareto frontier and offers a fine-grained range of configurations for tuning throughput and model quality. Our evaluation on an NVIDIA A100 GPU using a Mixtral 8x7B MoE model for three language modelling benchmarks demonstrates that the throughput of token generation can be adjusted from 0.63 to 13.00 token per second. This enhancement comes with a marginal perplexity increase of 2.62 to 2.80, 6.48 to 7.24, and 3.24 to 3.53 for WikiText2, PTB, and C4 datasets respectively under maximum quantization. These results highlight the practical applicability of our approach in dynamic and accuracy-sensitive applications where both memory usage and output quality are important.
A Winograd-based Integrated Photonics Accelerator for Convolutional Neural Networks
Jun 25, 2019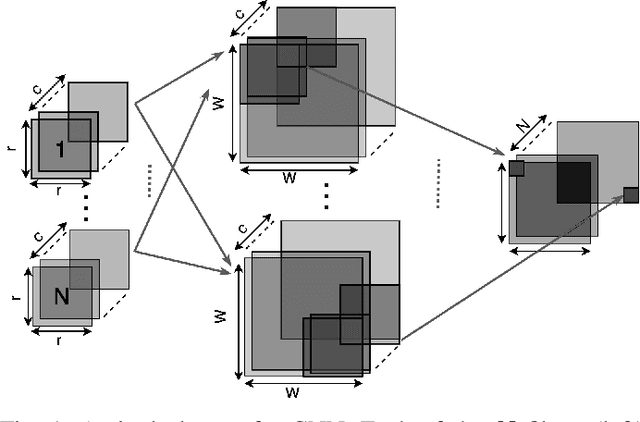
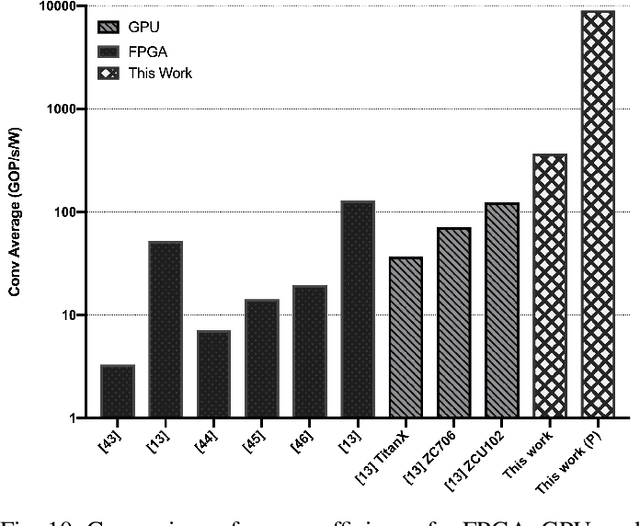
Neural Networks (NNs) have become the mainstream technology in the artificial intelligence (AI) renaissance over the past decade. Among different types of neural networks, convolutional neural networks (CNNs) have been widely adopted as they have achieved leading results in many fields such as computer vision and speech recognition. This success in part is due to the widespread availability of capable underlying hardware platforms. Applications have always been a driving factor for design of such hardware architectures. Hardware specialization can expose us to novel architectural solutions, which can outperform general purpose computers for tasks at hand. Although different applications demand for different performance measures, they all share speed and energy efficiency as high priorities. Meanwhile, photonics processing has seen a resurgence due to its inherited high speed and low power nature. Here, we investigate the potential of using photonics in CNNs by proposing a CNN accelerator design based on Winograd filtering algorithm. Our evaluation results show that while a photonic accelerator can compete with current-state-of-the-art electronic platforms in terms of both speed and power, it has the potential to improve the energy efficiency by up to three orders of magnitude.
PCNNA: A Photonic Convolutional Neural Network Accelerator
Jul 23, 2018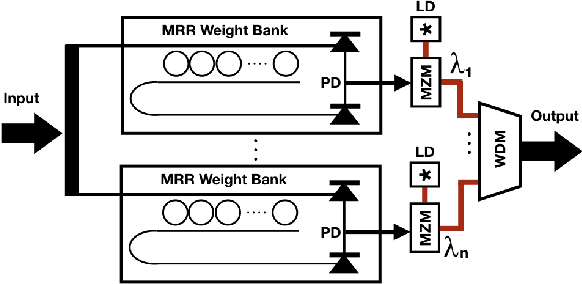
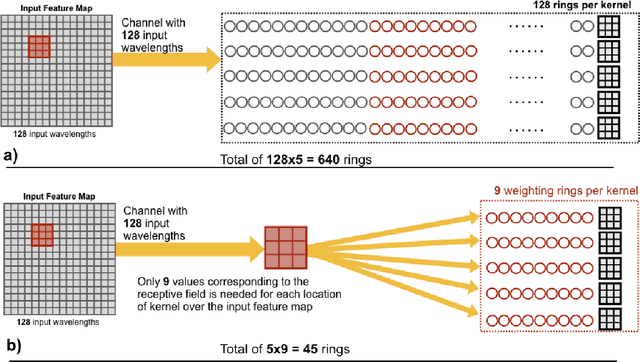
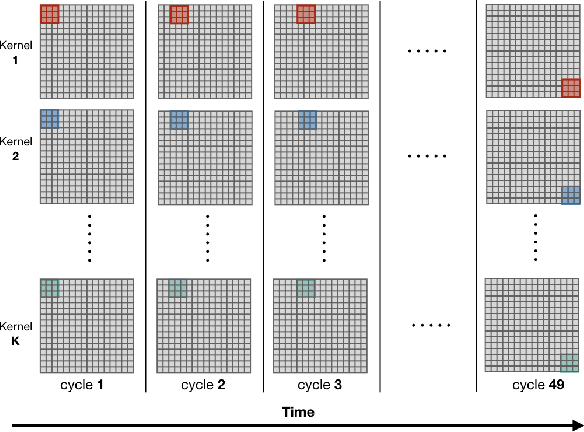
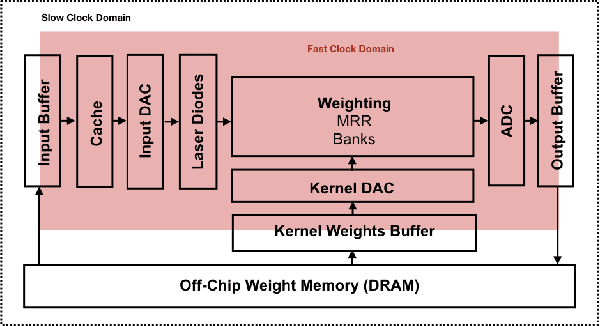
Convolutional Neural Networks (CNN) have been the centerpiece of many applications including but not limited to computer vision, speech processing, and Natural Language Processing (NLP). However, the computationally expensive convolution operations impose many challenges to the performance and scalability of CNNs. In parallel, photonic systems, which are traditionally employed for data communication, have enjoyed recent popularity for data processing due to their high bandwidth, low power consumption, and reconfigurability. Here we propose a Photonic Convolutional Neural Network Accelerator (PCNNA) as a proof of concept design to speedup the convolution operation for CNNs. Our design is based on the recently introduced silicon photonic microring weight banks, which use broadcast-and-weight protocol to perform Multiply And Accumulate (MAC) operation and move data through layers of a neural network. Here, we aim to exploit the synergy between the inherent parallelism of photonics in the form of Wavelength Division Multiplexing (WDM) and sparsity of connections between input feature maps and kernels in CNNs. While our full system design offers up to more than 3 orders of magnitude speedup in execution time, its optical core potentially offers more than 5 order of magnitude speedup compared to state-of-the-art electronic counterparts.