 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfect AI Mimicry and the Epistemology of Consciousness: A Solipsistic Dilemma
Oct 06, 2025Rapid advances in artificial intelligence necessitate a re-examination of the epistemological foundations upon which we attribute consciousness. As AI systems increasingly mimic human behavior and interaction with high fidelity, the concept of a "perfect mimic"-an entity empirically indistinguishable from a human through observation and interaction-shifts from hypothetical to technologically plausible. This paper argues that such developments pose a fundamental challenge to the consistency of our mind-recognition practices. Consciousness attributions rely heavily, if not exclusively, on empirical evidence derived from behavior and interaction. If a perfect mimic provides evidence identical to that of humans, any refusal to grant it equivalent epistemic status must invoke inaccessible factors, such as qualia, substrate requirements, or origin. Selectively invoking such factors risks a debilitating dilemma: either we undermine the rational basis for attributing consciousness to others (epistemological solipsism), or we accept inconsistent reasoning. I contend that epistemic consistency demands we ascribe the same status to empirically indistinguishable entities, regardless of metaphysical assumptions. The perfect mimic thus acts as an epistemic mirror, forcing critical reflection on the assumptions underlying intersubjective recognition in light of advancing AI. This analysis carries significant implications for theories of consciousness and ethical frameworks concerning artificial agents.
Training Neural Networks for Execution on Approximate Hardware
Apr 08, 2023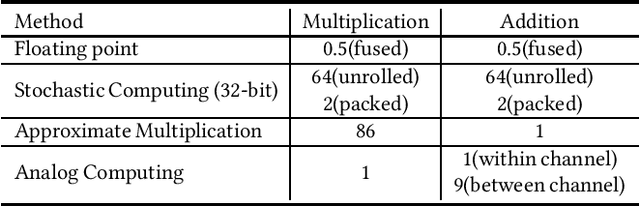
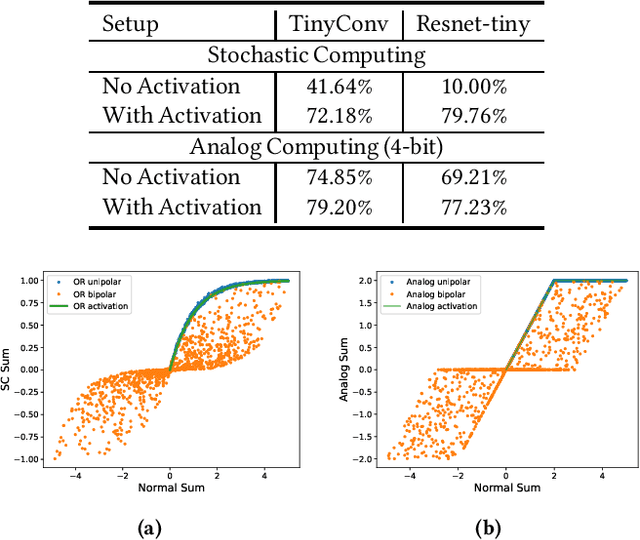
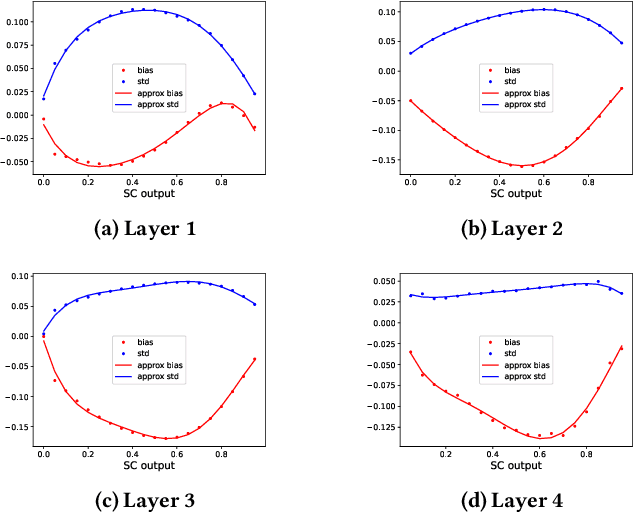
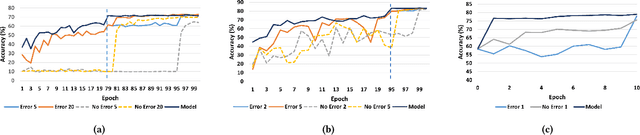
Approximate computing methods have shown great potential for deep learning. Due to the reduced hardware costs, these methods are especially suitable for inference tasks on battery-operated devices that are constrained by their power budget. However, approximate computing hasn't reached its full potential due to the lack of work on training methods. In this work, we discuss training methods for approximate hardware. We demonstrate how training needs to be specialized for approximate hardware, and propose methods to speed up the training process by up to 18X.
PhotoFourier: A Photonic Joint Transform Correlator-Based Neural Network Accelerator
Nov 10, 2022The last few years have seen a lot of work to address the challenge of low-latency and high-throughput convolutional neural network inference. Integrated photonics has the potential to dramatically accelerate neural networks because of its low-latency nature. Combined with the concept of Joint Transform Correlator (JTC), the computationally expensive convolution functions can be computed instantaneously (time of flight of light) with almost no cost. This 'free' convolution computation provides the theoretical basis of the proposed PhotoFourier JTC-based CNN accelerator. PhotoFourier addresses a myriad of challenges posed by on-chip photonic computing in the Fourier domain including 1D lenses and high-cost optoelectronic conversions. The proposed PhotoFourier accelerator achieves more than 28X better energy-delay product compared to state-of-art photonic neural network accelerators.
Bit-serial Weight Pools: Compression and Arbitrary Precision Execution of Neural Networks on Resource Constrained Processors
Jan 25, 2022
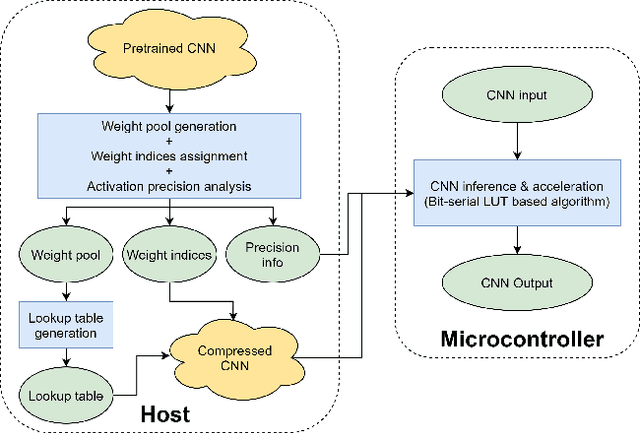
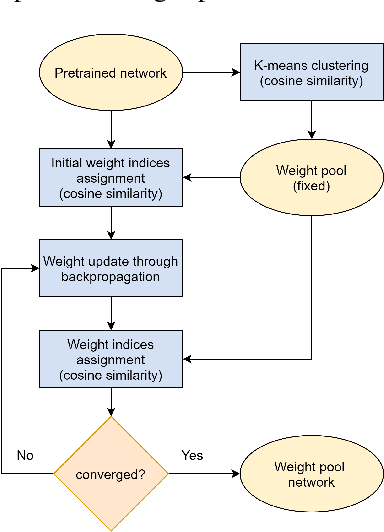

Applications of neural networks on edge systems have proliferated in recent years but the ever-increasing model size makes neural networks not able to deploy on resource-constrained microcontrollers efficiently. We propose bit-serial weight pools, an end-to-end framework that includes network compression and acceleration of arbitrary sub-byte precision. The framework can achieve up to 8x compression compared to 8-bit networks by sharing a pool of weights across the entire network. We further propose a bit-serial lookup based software implementation that allows runtime-bitwidth tradeoff and is able to achieve more than 2.8x speedup and 7.5x storage compression compared to 8-bit weight pool networks, with less than 1% accuracy drop.
Batch Processing and Data Streaming Fourier-based Convolutional Neural Network Accelerator
Dec 23, 2021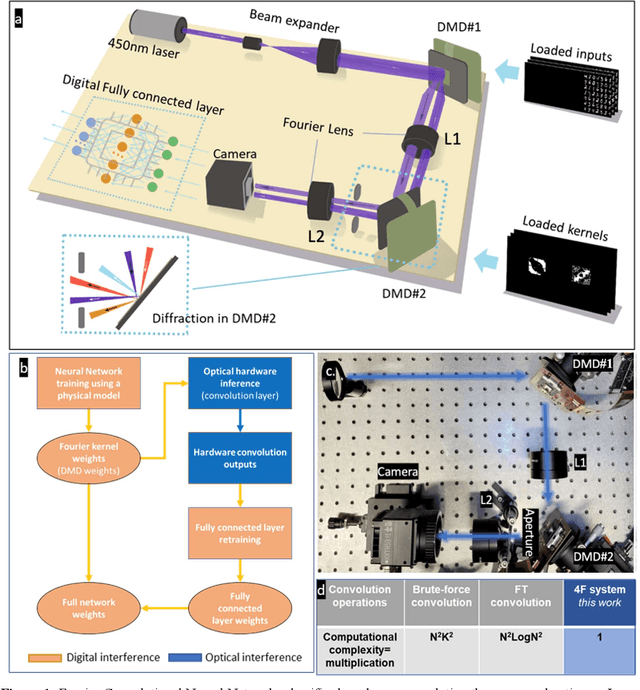

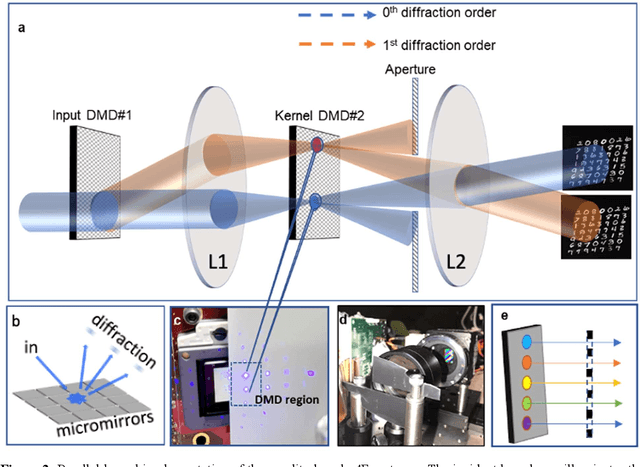
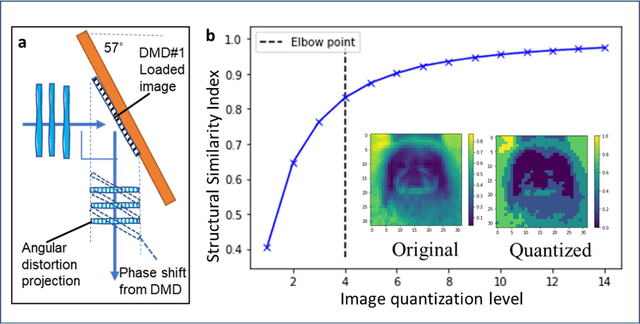
Decision-making by artificial neural networks with minimal latency is paramount for numerous applications such as navigation, tracking, and real-time machine action systems. This requires the machine learning hardware to handle multidimensional data with a high throughput. Processing convolution operations being the major computational tool for data classification tasks, unfortunately, follows a challenging run-time complexity scaling law. However, implementing the convolution theorem homomorphically in a Fourier-optic display-light-processor enables a non-iterative O(1) runtime complexity for data inputs beyond 1,000 x 1,000 large matrices. Following this approach, here we demonstrate data streaming multi-kernel image batch-processing with a Fourier Convolutional Neural Network (FCNN) accelerator. We show image batch processing of large-scale matrices as passive 2-million dot-product multiplications performed by digital light-processing modules in the Fourier domain. In addition, we parallelize this optical FCNN system further by utilizing multiple spatio-parallel diffraction orders, thus achieving a 98-times throughput improvement over state-of-art FCNN accelerators. The comprehensive discussion of the practical challenges related to working on the edge of the system's capabilities highlights issues of crosstalk in the Fourier domain and resolution scaling laws. Accelerating convolutions by utilizing the massive parallelism in display technology brings forth a non-van Neuman-based machine learning acceleration.
Revisiting the double-well problem by deep learning with a hybrid network
Apr 25, 2021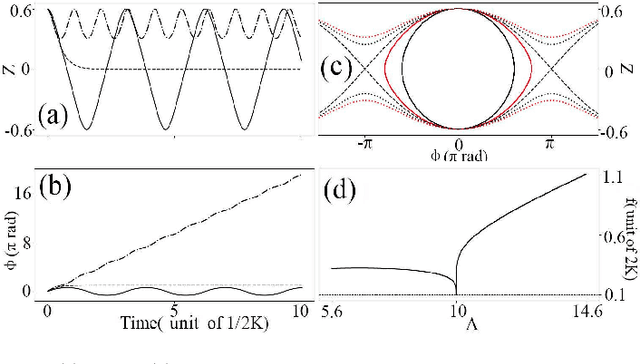
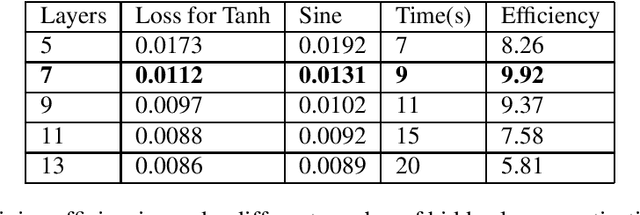
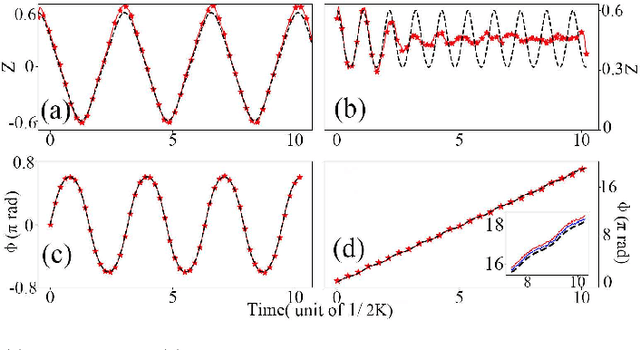
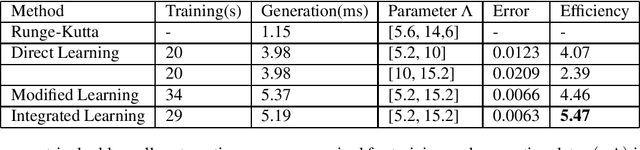
Solving physical problems by deep learning is accurate and efficient mainly accounting for the use of an elaborate neural network. We propose a novel hybrid network which integrates two different kinds of neural networks: LSTM and ResNet, in order to overcome the difficulty met in solving strongly-oscillating dynamics of the system's time evolution. By taking the double-well model as an example we show that our new method can benefit from a pre-learning and verification of the periodicity of frequency by using the LSTM network, simultaneously making a high-fidelity prediction about the whole dynamics of system with ResNet, which is impossibly achieved in the case of single network. Such a hybrid network can be applied for solving cooperative dynamics in a system with fast spatial or temporal modulations, promising for realistic oscillation calculations under experimental conditions.
SWIS -- Shared Weight bIt Sparsity for Efficient Neural Network Acceleration
Mar 03, 2021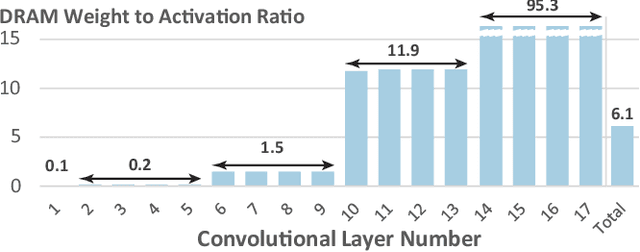

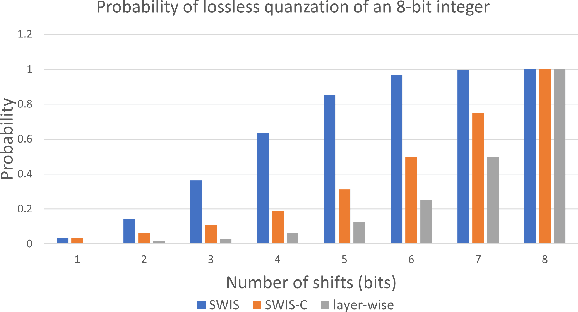
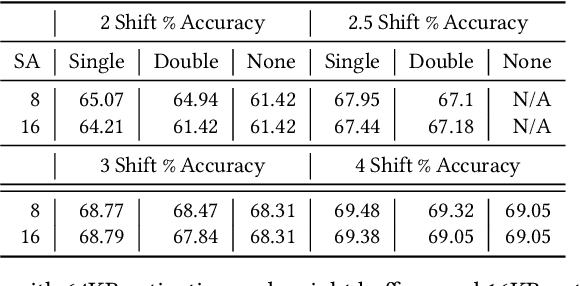
Quantization is spearheading the increase in performance and efficiency of neural network computing systems making headway into commodity hardware. We present SWIS - Shared Weight bIt Sparsity, a quantization framework for efficient neural network inference acceleration delivering improved performance and storage compression through an offline weight decomposition and scheduling algorithm. SWIS can achieve up to 54.3% (19.8%) point accuracy improvement compared to weight truncation when quantizing MobileNet-v2 to 4 (2) bits post-training (with retraining) showing the strength of leveraging shared bit-sparsity in weights. SWIS accelerator gives up to 6x speedup and 1.9x energy improvement overstate of the art bit-serial architectures.
You May Not Need Order in Time Series Forecasting
Oct 21, 2019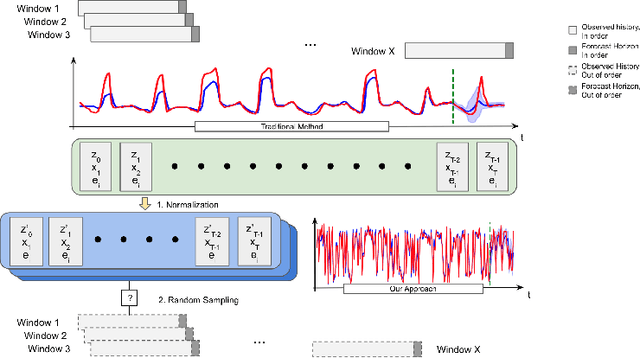
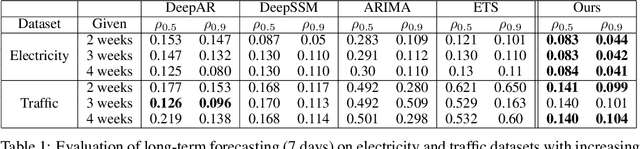
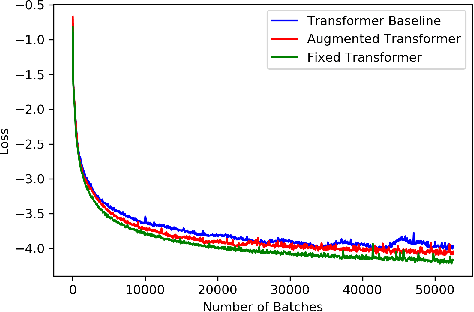
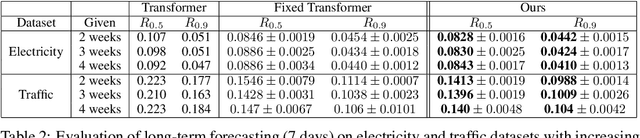
Time series forecasting with limited data is a challenging yet critical task. While transformers have achieved outstanding performances in time series forecasting, they often require many training samples due to the large number of trainable parameters. In this paper, we propose a training technique for transformers that prepares the training windows through random sampling. As input time steps need not be consecutive, the number of distinct samples increases from linearly to combinatorially many. By breaking the temporal order, this technique also helps transformers to capture dependencies among time steps in finer granularity. We achieve competitive results compared to the state-of-the-art on real-world datasets.