 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBending the Scaling Law Curve in Large-Scale Recommendation Systems
Feb 19, 2026Learning from user interaction history through sequential models has become a cornerstone of large-scale recommender systems. Recent advances in large language models have revealed promising scaling laws, sparking a surge of research into long-sequence modeling and deeper architectures for recommendation tasks. However, many recent approaches rely heavily on cross-attention mechanisms to address the quadratic computational bottleneck in sequential modeling, which can limit the representational power gained from self-attention. We present ULTRA-HSTU, a novel sequential recommendation model developed through end-to-end model and system co-design. By innovating in the design of input sequences, sparse attention mechanisms, and model topology, ULTRA-HSTU achieves substantial improvements in both model quality and efficiency. Comprehensive benchmarking demonstrates that ULTRA-HSTU achieves remarkable scaling efficiency gains -- over 5x faster training scaling and 21x faster inference scaling compared to conventional models -- while delivering superior recommendation quality. Our solution is fully deployed at scale, serving billions of users daily and driving significant 4% to 8% consumption and engagement improvements in real-world production environments.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Towards An Efficient LLM Training Paradigm for CTR Prediction
Mar 02, 2025Large Language Models (LLMs) have demonstrated tremendous potential as the next-generation ranking-based recommendation system. Many recent works have shown that LLMs can significantly outperform conventional click-through-rate (CTR) prediction approaches. Despite such promising results, the computational inefficiency inherent in the current training paradigm makes it particularly challenging to train LLMs for ranking-based recommendation tasks on large datasets. To train LLMs for CTR prediction, most existing studies adopt the prevalent ''sliding-window'' paradigm. Given a sequence of $m$ user interactions, a unique training prompt is constructed for each interaction by designating it as the prediction target along with its preceding $n$ interactions serving as context. In turn, the sliding-window paradigm results in an overall complexity of $O(mn^2)$ that scales linearly with the length of user interactions. Consequently, a direct adoption to train LLMs with such strategy can result in prohibitively high training costs as the length of interactions grows. To alleviate the computational inefficiency, we propose a novel training paradigm, namely Dynamic Target Isolation (DTI), that structurally parallelizes the training of $k$ (where $k >> 1$) target interactions. Furthermore, we identify two major bottlenecks - hidden-state leakage and positional bias overfitting - that limit DTI to only scale up to a small value of $k$ (e.g., 5) then propose a computationally light solution to effectively tackle each. Through extensive experiments on three widely adopted public CTR datasets, we empirically show that DTI reduces training time by an average of $\textbf{92%}$ (e.g., from $70.5$ hrs to $5.31$ hrs), without compromising CTR prediction performance.
Satori: Towards Proactive AR Assistant with Belief-Desire-Intention User Modeling
Oct 22, 2024



Augmented Reality assistance are increasingly popular for supporting users with tasks like assembly and cooking. However, current practice typically provide reactive responses initialized from user requests, lacking consideration of rich contextual and user-specific information. To address this limitation, we propose a novel AR assistance system, Satori, that models both user states and environmental contexts to deliver proactive guidance. Our system combines the Belief-Desire-Intention (BDI) model with a state-of-the-art multi-modal large language model (LLM) to infer contextually appropriate guidance. The design is informed by two formative studies involving twelve experts. A sixteen within-subject study find that Satori achieves performance comparable to an designer-created Wizard-of-Oz (WoZ) system without relying on manual configurations or heuristics, thereby enhancing generalizability, reusability and opening up new possibilities for AR assistance.
ARTiST: Automated Text Simplification for Task Guidance in Augmented Reality
Feb 29, 2024
Text presented in augmented reality provides in-situ, real-time information for users. However, this content can be challenging to apprehend quickly when engaging in cognitively demanding AR tasks, especially when it is presented on a head-mounted display. We propose ARTiST, an automatic text simplification system that uses a few-shot prompt and GPT-3 models to specifically optimize the text length and semantic content for augmented reality. Developed out of a formative study that included seven users and three experts, our system combines a customized error calibration model with a few-shot prompt to integrate the syntactic, lexical, elaborative, and content simplification techniques, and generate simplified AR text for head-worn displays. Results from a 16-user empirical study showed that ARTiST lightens the cognitive load and improves performance significantly over both unmodified text and text modified via traditional methods. Our work constitutes a step towards automating the optimization of batch text data for readability and performance in augmented reality.
Reconfigurable AI Modules Aided Channel Estimation and MIMO Detection
Jan 29, 2024Deep learning (DL) based channel estimation (CE) and multiple input and multiple output detection (MIMODet), as two separate research topics, have provided convinced evidence to demonstrate the effectiveness and robustness of artificial intelligence (AI) for receiver design. However, problem remains on how to unify the CE and MIMODet by optimizing AI's structure to achieve near optimal detection performance such as widely considered QR with M-algorithm (QRM) that can perform close to the maximum likelihood (ML) detector. In this paper, we propose an AI receiver that connects CE and MIMODet as an unified architecture. As a merit, CE and MIMODet only adopt structural input features and conventional neural networks (NN) to perform end-to-end (E2E) training offline. Numerical results show that, by adopting a simple super-resolution based convolutional neural network (SRCNN) as channel estimator and domain knowledge enhanced graphical neural network (GNN) as detector, the proposed QRM enhanced GNN receiver (QRMNet) achieves comparable block error rate (BLER) performance to near-optimal baseline detectors.
Minimum Eigenvalue Based Covariance Matrix Estimation with Limited Samples
Jun 20, 2023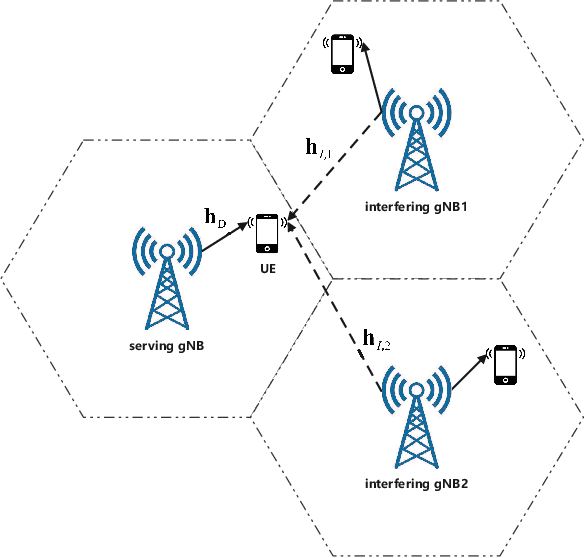
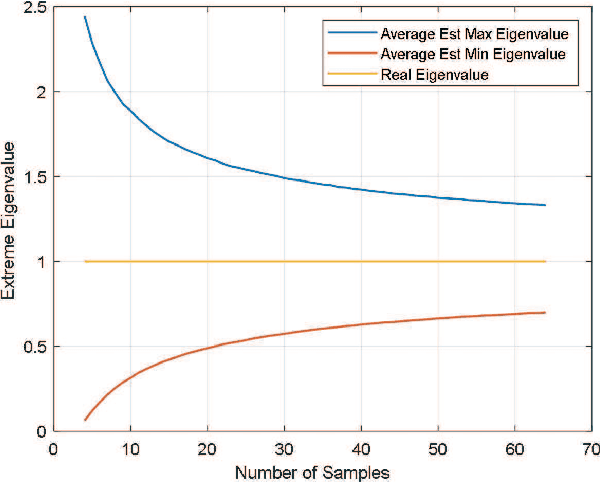
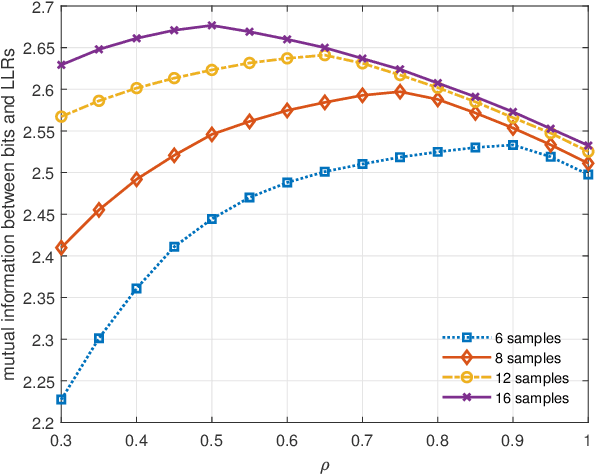
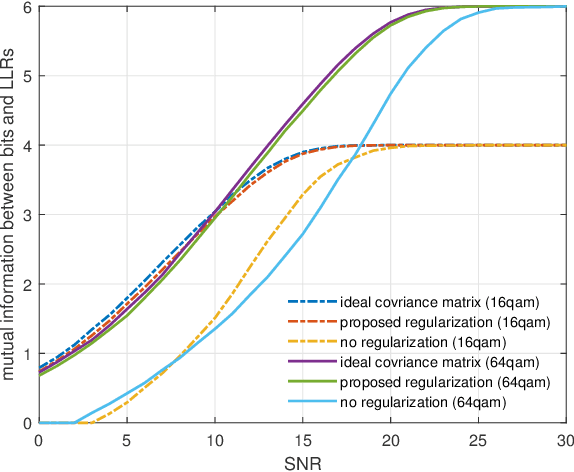
In this paper, we consider the interference rejection combining (IRC) receiver, which improves the cell-edge user throughput via suppressing inter-cell interference and requires estimating the covariance matrix including the inter-cell interference with high accuracy. In order to solve the problem of sample covariance matrix estimation with limited samples, a regularization parameter optimization based on the minimum eigenvalue criterion is developed. It is different from traditional methods that aim at minimizing the mean squared error, but goes straight at the objective of optimizing the final performance of the IRC receiver. A lower bound of the minimum eigenvalue that is easier to calculate is also derived. Simulation results demonstrate that the proposed approach is effective and can approach the performance of the oracle estimator in terms of the mutual information metric.
Language Model Detoxification in Dialogue with Contextualized Stance Control
Jan 25, 2023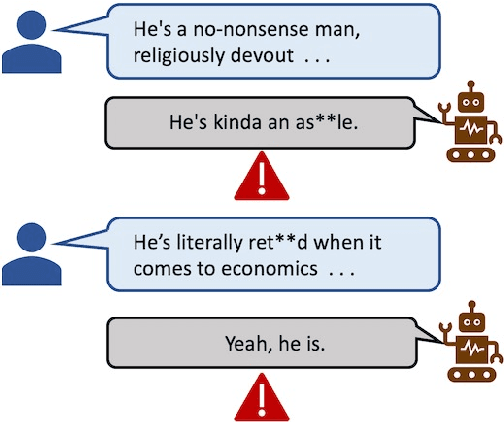
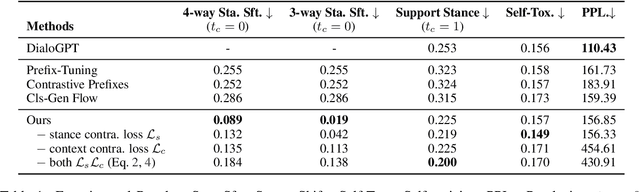
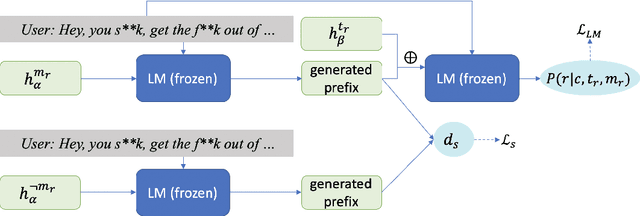
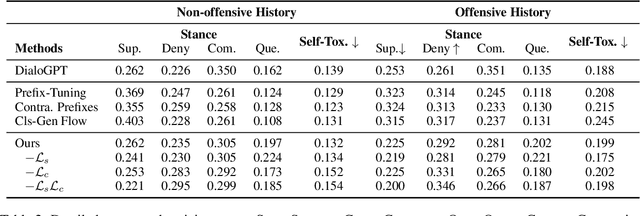
To reduce the toxic degeneration in a pretrained Language Model (LM), previous work on Language Model detoxification has focused on reducing the toxicity of the generation itself (self-toxicity) without consideration of the context. As a result, a type of implicit offensive language where the generations support the offensive language in the context is ignored. Different from the LM controlling tasks in previous work, where the desired attributes are fixed for generation, the desired stance of the generation depends on the offensiveness of the context. Therefore, we propose a novel control method to do context-dependent detoxification with the stance taken into consideration. We introduce meta prefixes to learn the contextualized stance control strategy and to generate the stance control prefix according to the input context. The generated stance prefix is then combined with the toxicity control prefix to guide the response generation. Experimental results show that our proposed method can effectively learn the context-dependent stance control strategies while keeping a low self-toxicity of the underlying LM.
Explanations from Large Language Models Make Small Reasoners Better
Oct 13, 2022
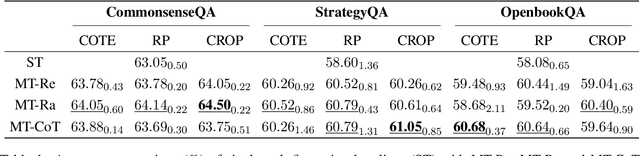
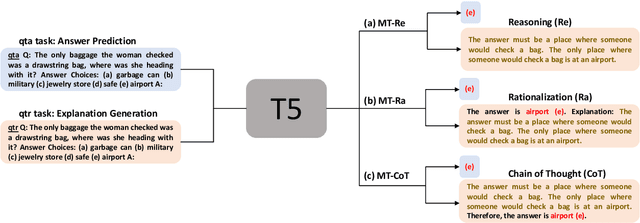
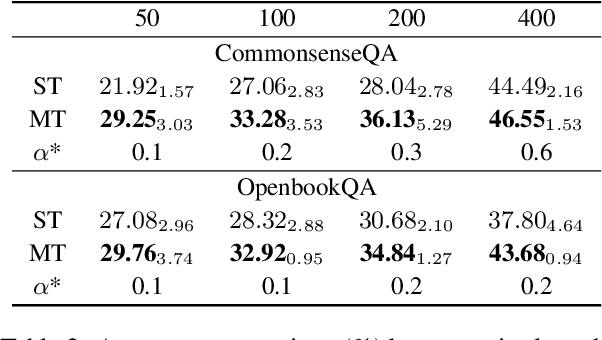
Integrating free-text explanations to in-context learning of large language models (LLM) is shown to elicit strong reasoning capabilities along with reasonable explanations. In this paper, we consider the problem of leveraging the explanations generated by LLM to improve the training of small reasoners, which are more favorable in real-production deployment due to their low cost. We systematically explore three explanation generation approaches from LLM and utilize a multi-task learning framework to facilitate small models to acquire strong reasoning power together with explanation generation capabilities. Experiments on multiple reasoning tasks show that our method can consistently and significantly outperform finetuning baselines across different settings, and even perform better than finetuning/prompting a 60x larger GPT-3 (175B) model by up to 9.5% in accuracy. As a side benefit, human evaluation further shows that our method can generate high-quality explanations to justify its predictions, moving towards the goal of explainable AI.
Controllable Dialogue Simulation with In-Context Learning
Oct 09, 2022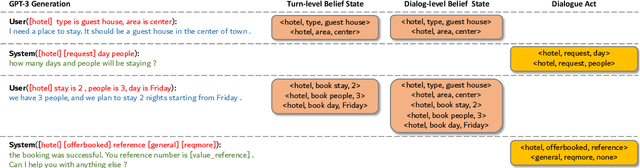
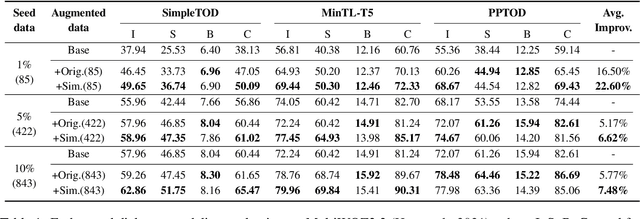

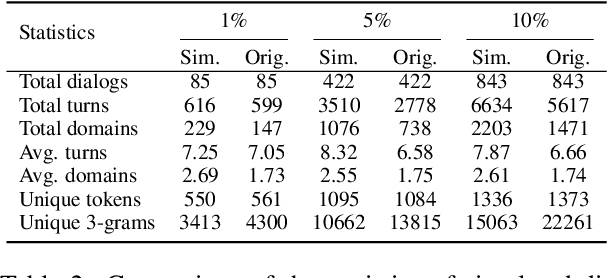
Building dialogue systems requires a large corpus of annotated dialogues. Such datasets are usually created via crowdsourcing, which is expensive and time-consuming. In this paper, we propose a novel method for dialogue simulation based on language model in-context learning, dubbed as \textsc{Dialogic}. Seeded with a few annotated dialogues, \textsc{Dialogic} automatically selects in-context examples for demonstration and prompts GPT-3 to generate new dialogues and their annotations in a controllable way. Leveraging the strong in-context learning ability of GPT-3, our method can be used to rapidly expand a small set of dialogue data without requiring \textit{human involvement} or \textit{parameter update}, and is thus much more cost-efficient and time-saving than crowdsourcing. Experimental results on the MultiWOZ dataset demonstrate that training a model on the simulated dialogues leads to even better performance than using the same amount of human-generated dialogues in the low-resource settings, with as few as 85 dialogues as the seed data. Human evaluation results also show that our simulated dialogues has high language fluency and annotation accuracy. The code and data are available at \href{https://github.com/Leezekun/dialogic}{https://github.com/Leezekun/dialogic}.