 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChArtist: Generating Pictorial Charts with Unified Spatial and Subject Control
Mar 15, 2026A pictorial chart is an effective medium for visual storytelling, seamlessly integrating visual elements with data charts. However, creating such images is challenging because the flexibility of visual elements often conflicts with the rigidity of chart structures. This process thus requires a creative deformation that maintains both data faithfulness and visual aesthetics. Current methods that extract dense structural cues from natural images (e.g., edge or depth maps) are ill-suited as conditioning signals for pictorial chart generation. We present ChArtist, a domain-specific diffusion model for generating pictorial charts automatically, offering two distinct types of control: 1) spatial control that aligns well with the chart structure, and 2) subject-driven control that respects the visual characteristics of a reference image. To achieve this, we introduce a skeleton-based spatial control representation. This representation encodes only the data-encoding information of the chart, allowing for the easy incorporation of reference visuals without a rigid outline constraint. We implement our method based on the Diffusion Transformer (DiT) and leverage an adaptive position encoding mechanism to manage these two controls. We further introduce Spatially Gated Attention to modulate the interaction between spatial control and subject control. To support the fine-tuning of pre-trained models for this task, we created a large-scale dataset of 30,000 triplets (skeleton, reference image, pictorial chart). We also propose a unified data accuracy metric to evaluate the data faithfulness of the generated charts. We believe this work demonstrates that current generative models can achieve data-driven visual storytelling by moving beyond general-purpose conditions to task-specific representations. Project page: https://chartist-ai.github.io/.
PosterMate: Audience-driven Collaborative Persona Agents for Poster Design
Jul 24, 2025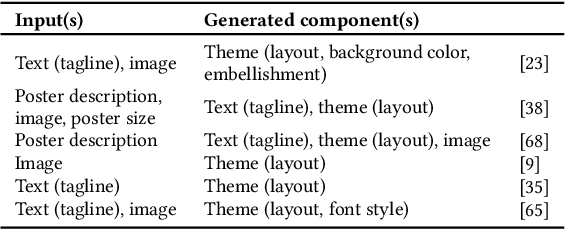
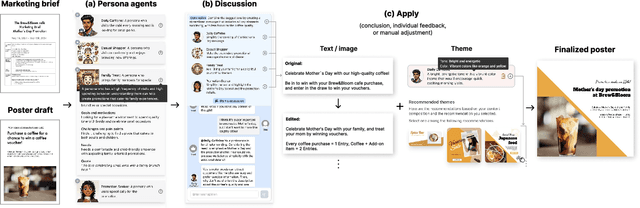
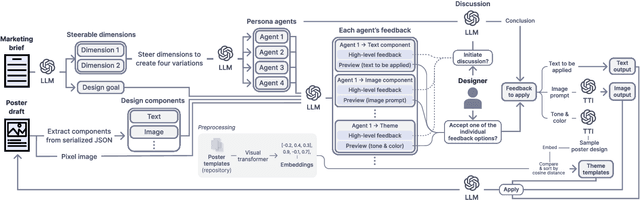
Poster designing can benefit from synchronous feedback from target audiences. However, gathering audiences with diverse perspectives and reconciling them on design edits can be challenging. Recent generative AI models present opportunities to simulate human-like interactions, but it is unclear how they may be used for feedback processes in design. We introduce PosterMate, a poster design assistant that facilitates collaboration by creating audience-driven persona agents constructed from marketing documents. PosterMate gathers feedback from each persona agent regarding poster components, and stimulates discussion with the help of a moderator to reach a conclusion. These agreed-upon edits can then be directly integrated into the poster design. Through our user study (N=12), we identified the potential of PosterMate to capture overlooked viewpoints, while serving as an effective prototyping tool. Additionally, our controlled online evaluation (N=100) revealed that the feedback from an individual persona agent is appropriate given its persona identity, and the discussion effectively synthesizes the different persona agents' perspectives.
Satori: Towards Proactive AR Assistant with Belief-Desire-Intention User Modeling
Oct 22, 2024



Augmented Reality assistance are increasingly popular for supporting users with tasks like assembly and cooking. However, current practice typically provide reactive responses initialized from user requests, lacking consideration of rich contextual and user-specific information. To address this limitation, we propose a novel AR assistance system, Satori, that models both user states and environmental contexts to deliver proactive guidance. Our system combines the Belief-Desire-Intention (BDI) model with a state-of-the-art multi-modal large language model (LLM) to infer contextually appropriate guidance. The design is informed by two formative studies involving twelve experts. A sixteen within-subject study find that Satori achieves performance comparable to an designer-created Wizard-of-Oz (WoZ) system without relying on manual configurations or heuristics, thereby enhancing generalizability, reusability and opening up new possibilities for AR assistance.
MOUNTAINEER: Topology-Driven Visual Analytics for Comparing Local Explanations
Jun 21, 2024With the increasing use of black-box Machine Learning (ML) techniques in critical applications, there is a growing demand for methods that can provide transparency and accountability for model predictions. As a result, a large number of local explainability methods for black-box models have been developed and popularized. However, machine learning explanations are still hard to evaluate and compare due to the high dimensionality, heterogeneous representations, varying scales, and stochastic nature of some of these methods. Topological Data Analysis (TDA) can be an effective method in this domain since it can be used to transform attributions into uniform graph representations, providing a common ground for comparison across different explanation methods. We present a novel topology-driven visual analytics tool, Mountaineer, that allows ML practitioners to interactively analyze and compare these representations by linking the topological graphs back to the original data distribution, model predictions, and feature attributions. Mountaineer facilitates rapid and iterative exploration of ML explanations, enabling experts to gain deeper insights into the explanation techniques, understand the underlying data distributions, and thus reach well-founded conclusions about model behavior. Furthermore, we demonstrate the utility of Mountaineer through two case studies using real-world data. In the first, we show how Mountaineer enabled us to compare black-box ML explanations and discern regions of and causes of disagreements between different explanations. In the second, we demonstrate how the tool can be used to compare and understand ML models themselves. Finally, we conducted interviews with three industry experts to help us evaluate our work.
Summaries as Captions: Generating Figure Captions for Scientific Documents with Automated Text Summarization
Feb 23, 2023

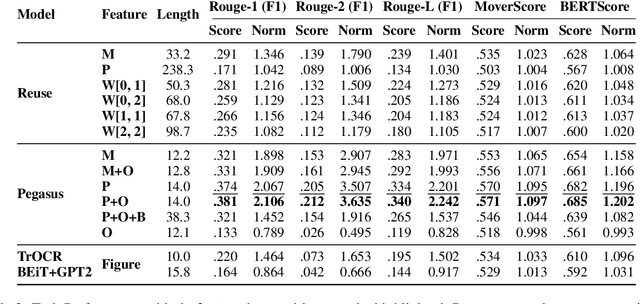
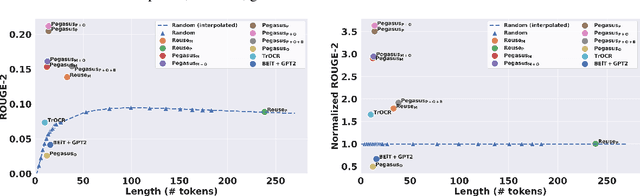
Effective figure captions are crucial for clear comprehension of scientific figures, yet poor caption writing remains a common issue in scientific articles. Our study of arXiv cs.CL papers found that 53.88% of captions were rated as unhelpful or worse by domain experts, showing the need for better caption generation. Previous efforts in figure caption generation treated it as a vision task, aimed at creating a model to understand visual content and complex contextual information. Our findings, however, demonstrate that over 75% of figure captions' tokens align with corresponding figure-mentioning paragraphs, indicating great potential for language technology to solve this task. In this paper, we present a novel approach for generating figure captions in scientific documents using text summarization techniques. Our approach extracts sentences referencing the target figure, then summarizes them into a concise caption. In the experiments on real-world arXiv papers (81.2% were published at academic conferences), our method, using only text data, outperformed previous approaches in both automatic and human evaluations. We further conducted data-driven investigations into the two core challenges: (i) low-quality author-written captions and (ii) the absence of a standard for good captions. We found that our models could generate improved captions for figures with original captions rated as unhelpful, and the model trained on captions with more than 30 tokens produced higher-quality captions. We also found that good captions often include the high-level takeaway of the figure. Our work proves the effectiveness of text summarization in generating figure captions for scholarly articles, outperforming prior vision-based approaches. Our findings have practical implications for future figure captioning systems, improving scientific communication clarity.