 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptProver: Bridging Olympiad and Optimization through Continual Training in Formal Theorem Proving
Apr 28, 2026Recent advances in formal theorem proving have focused on Olympiad-level mathematics, leaving undergraduate domains largely unexplored. Optimization, fundamental to machine learning, operations research, and scientific computing, remains underserved by existing provers. Its reliance on domain-specific formalisms (convexity, optimality conditions, and algorithmic analysis) creates significant distribution shift, making naive domain transfer ineffective. We present OptProver, a trained model that achieves robust transfer from Olympiad to undergraduate optimization. Starting from a strong Olympiad-level prover, our pipeline mitigates distribution shift through two key innovations. First, we employ large-scale optimization-focused data curation via expert iteration. Second, we introduce a specialized preference learning objective that integrates perplexity-weighted optimization with a mechanism to penalize valid but non-progressing proof steps. This not only addresses distribution shifts but also guides the search toward efficient trajectories. To enable rigorous evaluation, we construct a novel benchmark in Lean 4 focused on optimization. On this benchmark, OptProver achieves state-of-the-art Pass@1 and Pass@32 among comparably sized models while maintaining competitive performance on general theorem-proving tasks, demonstrating effective domain transfer without catastrophic forgetting.
Why Human Guidance Matters in Collaborative Vibe Coding
Feb 11, 2026Writing code has been one of the most transformative ways for human societies to translate abstract ideas into tangible technologies. Modern AI is transforming this process by enabling experts and non-experts alike to generate code without actually writing code, but instead, through natural language instructions, or "vibe coding". While increasingly popular, the cumulative impact of vibe coding on productivity and collaboration, as well as the role of humans in this process, remains unclear. Here, we introduce a controlled experimental framework for studying collaborative vibe coding and use it to compare human-led, AI-led, and hybrid groups. Across 16 experiments involving 604 human participants, we show that people provide uniquely effective high-level instructions for vibe coding across iterations, whereas AI-provided instructions often result in performance collapse. We further demonstrate that hybrid systems perform best when humans retain directional control (providing the instructions), while evaluation is delegated to AI.
SetPO: Set-Level Policy Optimization for Diversity-Preserving LLM Reasoning
Feb 01, 2026Reinforcement learning with verifiable rewards has shown notable effectiveness in enhancing large language models (LLMs) reasoning performance, especially in mathematics tasks. However, such improvements often come with reduced outcome diversity, where the model concentrates probability mass on a narrow set of solutions. Motivated by diminishing-returns principles, we introduce a set level diversity objective defined over sampled trajectories using kernelized similarity. Our approach derives a leave-one-out marginal contribution for each sampled trajectory and integrates this objective as a plug-in advantage shaping term for policy optimization. We further investigate the contribution of a single trajectory to language model diversity within a distribution perturbation framework. This analysis theoretically confirms a monotonicity property, proving that rarer trajectories yield consistently higher marginal contributions to the global diversity. Extensive experiments across a range of model scales demonstrate the effectiveness of our proposed algorithm, consistently outperforming strong baselines in both Pass@1 and Pass@K across various benchmarks.
Translating Informal Proofs into Formal Proofs Using a Chain of States
Dec 12, 2025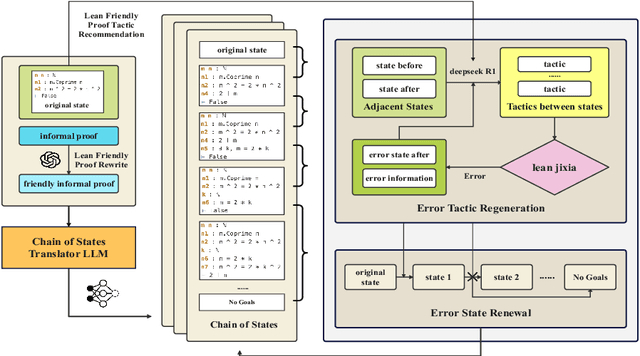
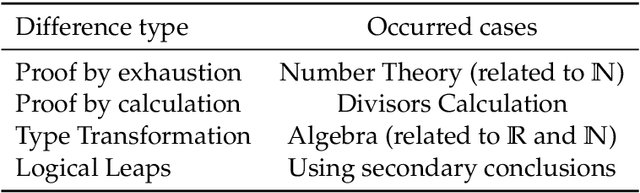

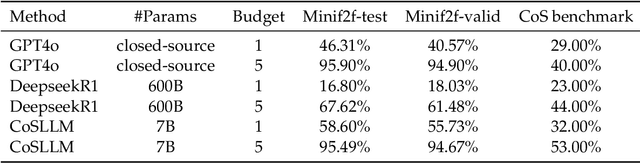
We address the problem of translating informal mathematical proofs expressed in natural language into formal proofs in Lean4 under a constrained computational budget. Our approach is grounded in two key insights. First, informal proofs tend to proceed via a sequence of logical transitions - often implications or equivalences - without explicitly specifying intermediate results or auxiliary lemmas. In contrast, formal systems like Lean require an explicit representation of each proof state and the tactics that connect them. Second, each informal reasoning step can be viewed as an abstract transformation between proof states, but identifying the corresponding formal tactics often requires nontrivial domain knowledge and precise control over proof context. To bridge this gap, we propose a two stage framework. Rather than generating formal tactics directly, we first extract a Chain of States (CoS), a sequence of intermediate formal proof states aligned with the logical structure of the informal argument. We then generate tactics to transition between adjacent states in the CoS, thereby constructing the full formal proof. This intermediate representation significantly reduces the complexity of tactic generation and improves alignment with informal reasoning patterns. We build dedicated datasets and benchmarks for training and evaluation, and introduce an interactive framework to support tactic generation from formal states. Empirical results show that our method substantially outperforms existing baselines, achieving higher proof success rates.
Advancing Mathematical Research via Human-AI Interactive Theorem Proving
Dec 11, 2025We investigate how large language models can be used as research tools in scientific computing while preserving mathematical rigor. We propose a human-in-the-loop workflow for interactive theorem proving and discovery with LLMs. Human experts retain control over problem formulation and admissible assumptions, while the model searches for proofs or contradictions, proposes candidate properties and theorems, and helps construct structures and parameters that satisfy explicit constraints, supported by numerical experiments and simple verification checks. Experts treat these outputs as raw material, further refine them, and organize the results into precise statements and rigorous proofs. We instantiate this workflow in a case study on the connection between manifold optimization and Grover's quantum search algorithm, where the pipeline helps identify invariant subspaces, explore Grover-compatible retractions, and obtain convergence guarantees for the retraction-based gradient method. The framework provides a practical template for integrating large language models into frontier mathematical research, enabling faster exploration of proof space and algorithm design while maintaining transparent reasoning responsibilities. Although illustrated on manifold optimization problems in quantum computing, the principles extend to other core areas of scientific computing.
SITA: A Framework for Structure-to-Instance Theorem Autoformalization
Nov 13, 2025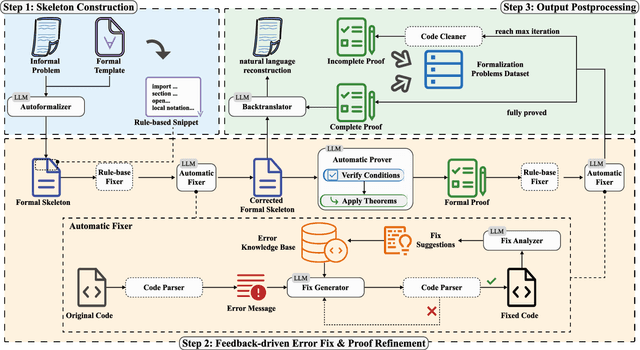
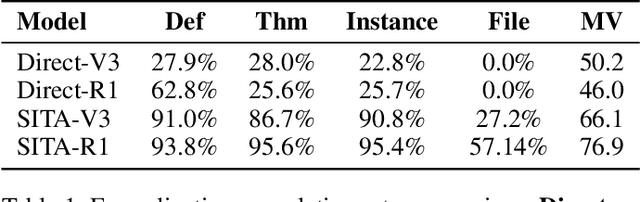
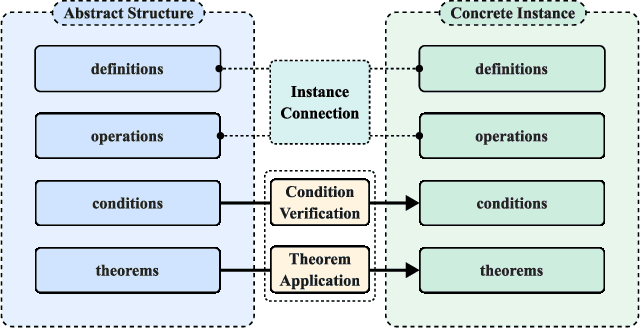
While large language models (LLMs) have shown progress in mathematical reasoning, they still face challenges in formalizing theorems that arise from instantiating abstract structures in concrete settings. With the goal of auto-formalizing mathematical results at the research level, we develop a framework for structure-to-instance theorem autoformalization (SITA), which systematically bridges the gap between abstract mathematical theories and their concrete applications in Lean proof assistant. Formalized abstract structures are treated as modular templates that contain definitions, assumptions, operations, and theorems. These templates serve as reusable guides for the formalization of concrete instances. Given a specific instantiation, we generate corresponding Lean definitions and instance declarations, integrate them using Lean's typeclass mechanism, and construct verified theorems by checking structural assumptions. We incorporate LLM-based generation with feedback-guided refinement to ensure both automation and formal correctness. Experiments on a dataset of optimization problems demonstrate that SITA effectively formalizes diverse instances grounded in abstract structures.
Satori: Towards Proactive AR Assistant with Belief-Desire-Intention User Modeling
Oct 22, 2024



Augmented Reality assistance are increasingly popular for supporting users with tasks like assembly and cooking. However, current practice typically provide reactive responses initialized from user requests, lacking consideration of rich contextual and user-specific information. To address this limitation, we propose a novel AR assistance system, Satori, that models both user states and environmental contexts to deliver proactive guidance. Our system combines the Belief-Desire-Intention (BDI) model with a state-of-the-art multi-modal large language model (LLM) to infer contextually appropriate guidance. The design is informed by two formative studies involving twelve experts. A sixteen within-subject study find that Satori achieves performance comparable to an designer-created Wizard-of-Oz (WoZ) system without relying on manual configurations or heuristics, thereby enhancing generalizability, reusability and opening up new possibilities for AR assistance.
Embedding Decomposition for Artifacts Removal in EEG Signals
Dec 02, 2021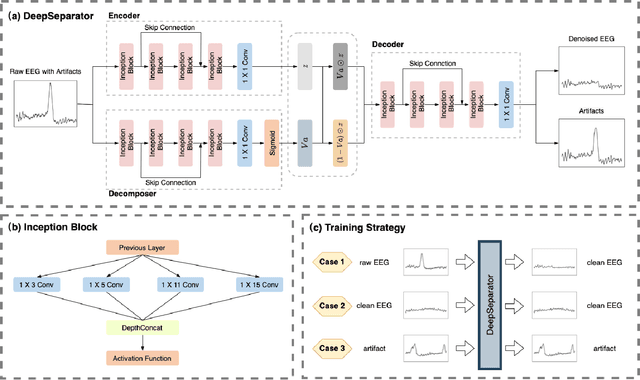
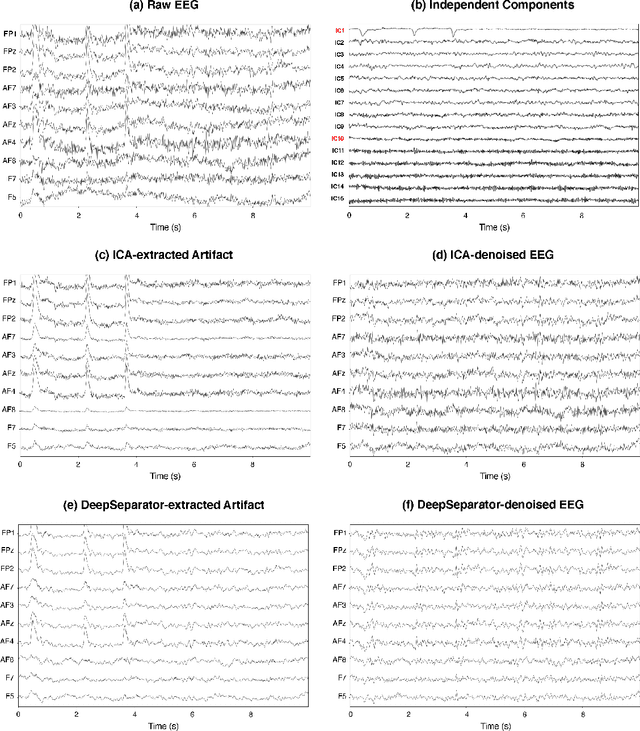
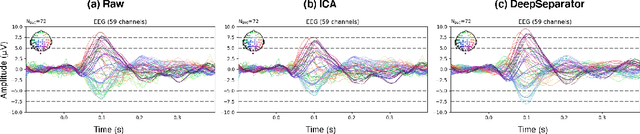
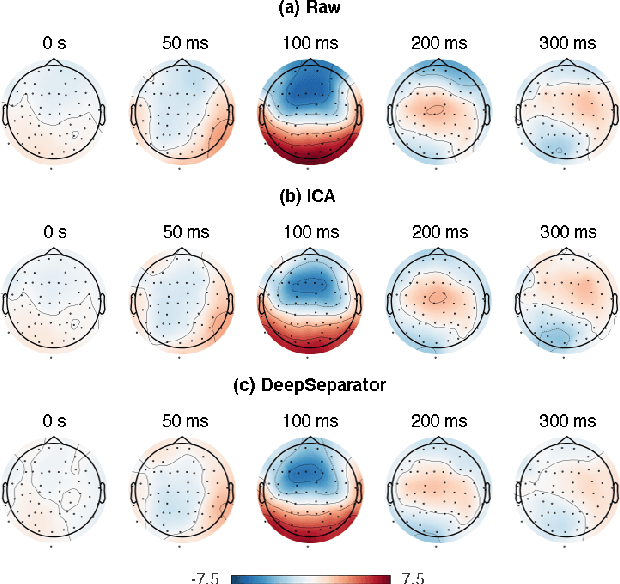
Electroencephalogram (EEG) recordings are often contaminated with artifacts. Various methods have been developed to eliminate or weaken the influence of artifacts. However, most of them rely on prior experience for analysis. Here, we propose an deep learning framework to separate neural signal and artifacts in the embedding space and reconstruct the denoised signal, which is called DeepSeparator. DeepSeparator employs an encoder to extract and amplify the features in the raw EEG, a module called decomposer to extract the trend, detect and suppress artifact and a decoder to reconstruct the denoised signal. Besides, DeepSeparator can extract the artifact, which largely increases the model interpretability. The proposed method is tested with a semi-synthetic EEG dataset and a real task-related EEG dataset, suggesting that DeepSeparator outperforms the conventional models in both EOG and EMG artifact removal. DeepSeparator can be extended to multi-channel EEG and data of any length. It may motivate future developments and application of deep learning-based EEG denoising. The code for DeepSeparator is available at https://github.com/ncclabsustech/DeepSeparator.
Spoken Style Learning with Multi-modal Hierarchical Context Encoding for Conversational Text-to-Speech Synthesis
Jun 11, 2021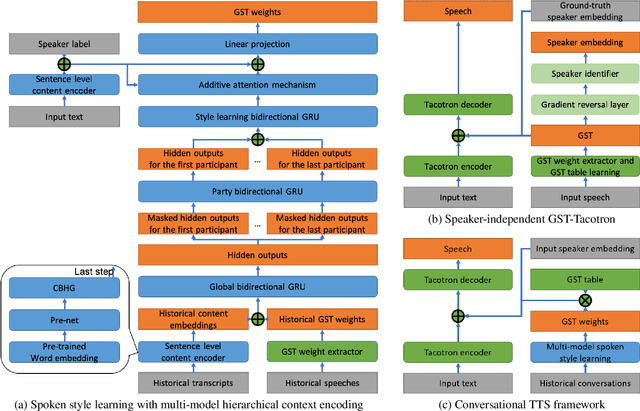

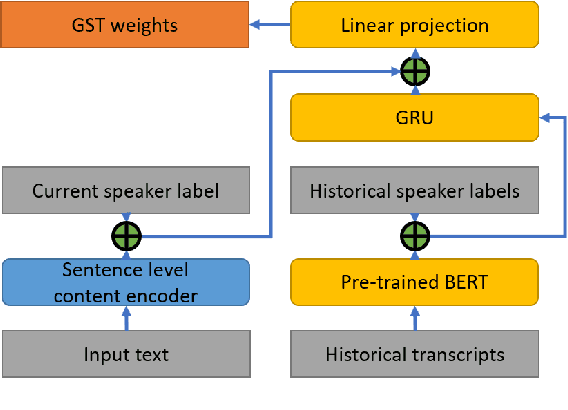

For conversational text-to-speech (TTS) systems, it is vital that the systems can adjust the spoken styles of synthesized speech according to different content and spoken styles in historical conversations. However, the study about learning spoken styles from historical conversations is still in its infancy. Only the transcripts of the historical conversations are considered, which neglects the spoken styles in historical speeches. Moreover, only the interactions of the global aspect between speakers are modeled, missing the party aspect self interactions inside each speaker. In this paper, to achieve better spoken style learning for conversational TTS, we propose a spoken style learning approach with multi-modal hierarchical context encoding. The textual information and spoken styles in the historical conversations are processed through multiple hierarchical recurrent neural networks to learn the spoken style related features in global and party aspects. The attention mechanism is further employed to summarize these features into a conversational context encoding. Experimental results demonstrate the effectiveness of our proposed approach, which outperform a baseline method using context encoding learnt only from the transcripts in global aspects, with MOS score on the naturalness of synthesized speech increasing from 3.138 to 3.408 and ABX preference rate exceeding the baseline method by 36.45%.