 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoken Style Learning with Multi-modal Hierarchical Context Encoding for Conversational Text-to-Speech Synthesis
Paper and Code
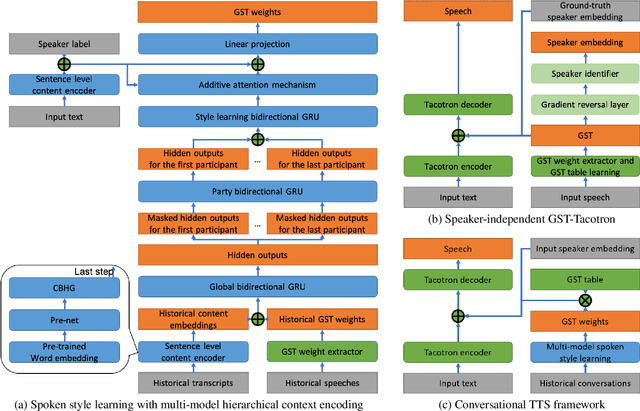

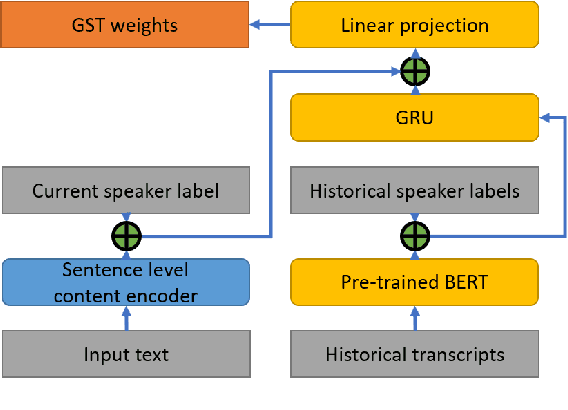

For conversational text-to-speech (TTS) systems, it is vital that the systems can adjust the spoken styles of synthesized speech according to different content and spoken styles in historical conversations. However, the study about learning spoken styles from historical conversations is still in its infancy. Only the transcripts of the historical conversations are considered, which neglects the spoken styles in historical speeches. Moreover, only the interactions of the global aspect between speakers are modeled, missing the party aspect self interactions inside each speaker. In this paper, to achieve better spoken style learning for conversational TTS, we propose a spoken style learning approach with multi-modal hierarchical context encoding. The textual information and spoken styles in the historical conversations are processed through multiple hierarchical recurrent neural networks to learn the spoken style related features in global and party aspects. The attention mechanism is further employed to summarize these features into a conversational context encoding. Experimental results demonstrate the effectiveness of our proposed approach, which outperform a baseline method using context encoding learnt only from the transcripts in global aspects, with MOS score on the naturalness of synthesized speech increasing from 3.138 to 3.408 and ABX preference rate exceeding the baseline method by 36.45%.