 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaMP-Cap: Personalized Figure Caption Generation With Multimodal Figure Profiles
Jun 06, 2025Figure captions are crucial for helping readers understand and remember a figure's key message. Many models have been developed to generate these captions, helping authors compose better quality captions more easily. Yet, authors almost always need to revise generic AI-generated captions to match their writing style and the domain's style, highlighting the need for personalization. Despite language models' personalization (LaMP) advances, these technologies often focus on text-only settings and rarely address scenarios where both inputs and profiles are multimodal. This paper introduces LaMP-Cap, a dataset for personalized figure caption generation with multimodal figure profiles. For each target figure, LaMP-Cap provides not only the needed inputs, such as figure images, but also up to three other figures from the same document--each with its image, caption, and figure-mentioning paragraphs--as a profile to characterize the context. Experiments with four LLMs show that using profile information consistently helps generate captions closer to the original author-written ones. Ablation studies reveal that images in the profile are more helpful than figure-mentioning paragraphs, highlighting the advantage of using multimodal profiles over text-only ones.
AgentA/B: Automated and Scalable Web A/BTesting with Interactive LLM Agents
Apr 13, 2025



A/B testing experiment is a widely adopted method for evaluating UI/UX design decisions in modern web applications. Yet, traditional A/B testing remains constrained by its dependence on the large-scale and live traffic of human participants, and the long time of waiting for the testing result. Through formative interviews with six experienced industry practitioners, we identified critical bottlenecks in current A/B testing workflows. In response, we present AgentA/B, a novel system that leverages Large Language Model-based autonomous agents (LLM Agents) to automatically simulate user interaction behaviors with real webpages. AgentA/B enables scalable deployment of LLM agents with diverse personas, each capable of navigating the dynamic webpage and interactively executing multi-step interactions like search, clicking, filtering, and purchasing. In a demonstrative controlled experiment, we employ AgentA/B to simulate a between-subject A/B testing with 1,000 LLM agents Amazon.com, and compare agent behaviors with real human shopping behaviors at a scale. Our findings suggest AgentA/B can emulate human-like behavior patterns.
Understanding How Paper Writers Use AI-Generated Captions in Figure Caption Writing
Jan 10, 2025Figures and their captions play a key role in scientific publications. However, despite their importance, many captions in published papers are poorly crafted, largely due to a lack of attention by paper authors. While prior AI research has explored caption generation, it has mainly focused on reader-centered use cases, where users evaluate generated captions rather than actively integrating them into their writing. This paper addresses this gap by investigating how paper authors incorporate AI-generated captions into their writing process through a user study involving 18 participants. Each participant rewrote captions for two figures from their own recently published work, using captions generated by state-of-the-art AI models as a resource. By analyzing video recordings of the writing process through interaction analysis, we observed that participants often began by copying and refining AI-generated captions. Paper writers favored longer, detail-rich captions that integrated textual and visual elements but found current AI models less effective for complex figures. These findings highlight the nuanced and diverse nature of figure caption composition, revealing design opportunities for AI systems to better support the challenges of academic writing.
Multi-LLM Collaborative Caption Generation in Scientific Documents
Jan 05, 2025



Scientific figure captioning is a complex task that requires generating contextually appropriate descriptions of visual content. However, existing methods often fall short by utilizing incomplete information, treating the task solely as either an image-to-text or text summarization problem. This limitation hinders the generation of high-quality captions that fully capture the necessary details. Moreover, existing data sourced from arXiv papers contain low-quality captions, posing significant challenges for training large language models (LLMs). In this paper, we introduce a framework called Multi-LLM Collaborative Figure Caption Generation (MLBCAP) to address these challenges by leveraging specialized LLMs for distinct sub-tasks. Our approach unfolds in three key modules: (Quality Assessment) We utilize multimodal LLMs to assess the quality of training data, enabling the filtration of low-quality captions. (Diverse Caption Generation) We then employ a strategy of fine-tuning/prompting multiple LLMs on the captioning task to generate candidate captions. (Judgment) Lastly, we prompt a prominent LLM to select the highest quality caption from the candidates, followed by refining any remaining inaccuracies. Human evaluations demonstrate that informative captions produced by our approach rank better than human-written captions, highlighting its effectiveness. Our code is available at https://github.com/teamreboott/MLBCAP
SciCapenter: Supporting Caption Composition for Scientific Figures with Machine-Generated Captions and Ratings
Mar 26, 2024
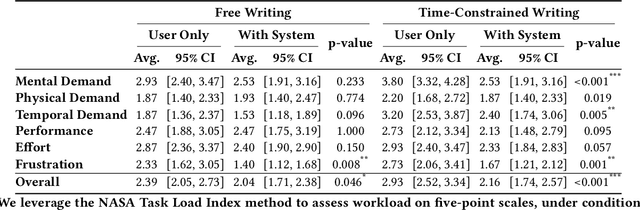

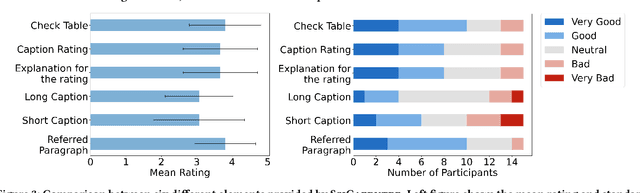
Crafting effective captions for figures is important. Readers heavily depend on these captions to grasp the figure's message. However, despite a well-developed set of AI technologies for figures and captions, these have rarely been tested for usefulness in aiding caption writing. This paper introduces SciCapenter, an interactive system that puts together cutting-edge AI technologies for scientific figure captions to aid caption composition. SciCapenter generates a variety of captions for each figure in a scholarly article, providing scores and a comprehensive checklist to assess caption quality across multiple critical aspects, such as helpfulness, OCR mention, key takeaways, and visual properties reference. Users can directly edit captions in SciCapenter, resubmit for revised evaluations, and iteratively refine them. A user study with Ph.D. students indicates that SciCapenter significantly lowers the cognitive load of caption writing. Participants' feedback further offers valuable design insights for future systems aiming to enhance caption writing.
GPT-4 as an Effective Zero-Shot Evaluator for Scientific Figure Captions
Oct 23, 2023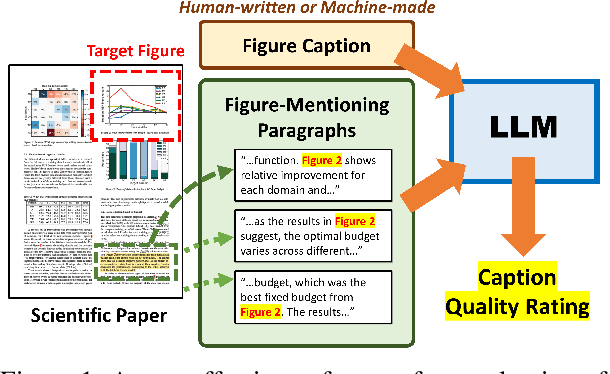
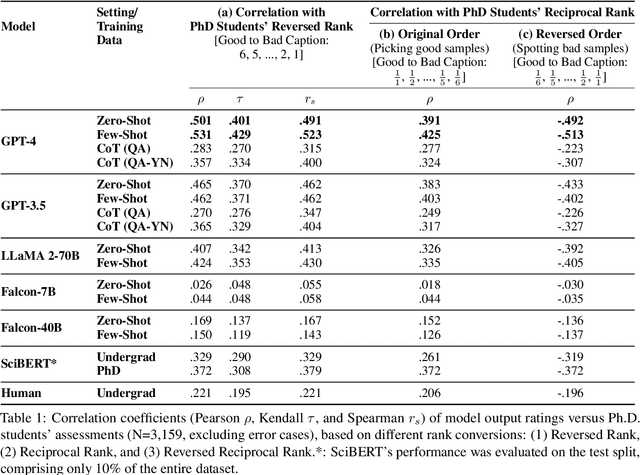
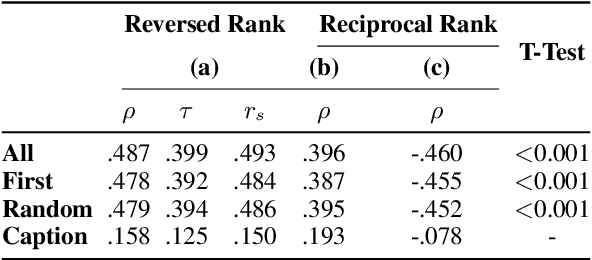
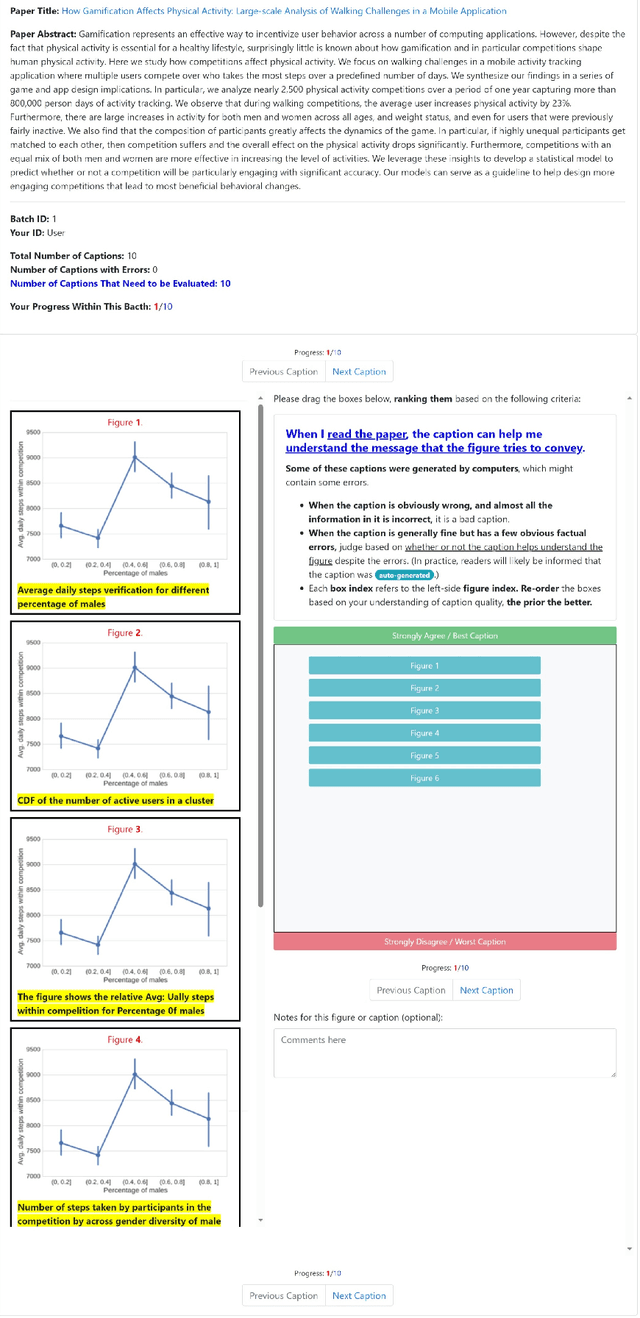
There is growing interest in systems that generate captions for scientific figures. However, assessing these systems output poses a significant challenge. Human evaluation requires academic expertise and is costly, while automatic evaluation depends on often low-quality author-written captions. This paper investigates using large language models (LLMs) as a cost-effective, reference-free method for evaluating figure captions. We first constructed SCICAP-EVAL, a human evaluation dataset that contains human judgments for 3,600 scientific figure captions, both original and machine-made, for 600 arXiv figures. We then prompted LLMs like GPT-4 and GPT-3 to score (1-6) each caption based on its potential to aid reader understanding, given relevant context such as figure-mentioning paragraphs. Results show that GPT-4, used as a zero-shot evaluator, outperformed all other models and even surpassed assessments made by Computer Science and Informatics undergraduates, achieving a Kendall correlation score of 0.401 with Ph.D. students rankings
Summaries as Captions: Generating Figure Captions for Scientific Documents with Automated Text Summarization
Feb 23, 2023

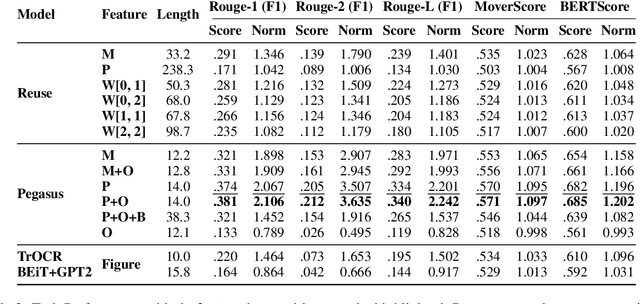
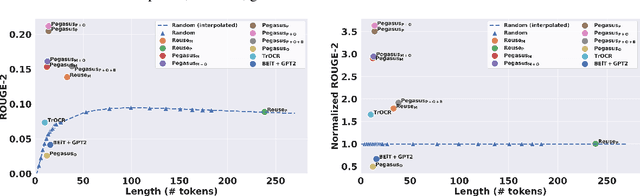
Effective figure captions are crucial for clear comprehension of scientific figures, yet poor caption writing remains a common issue in scientific articles. Our study of arXiv cs.CL papers found that 53.88% of captions were rated as unhelpful or worse by domain experts, showing the need for better caption generation. Previous efforts in figure caption generation treated it as a vision task, aimed at creating a model to understand visual content and complex contextual information. Our findings, however, demonstrate that over 75% of figure captions' tokens align with corresponding figure-mentioning paragraphs, indicating great potential for language technology to solve this task. In this paper, we present a novel approach for generating figure captions in scientific documents using text summarization techniques. Our approach extracts sentences referencing the target figure, then summarizes them into a concise caption. In the experiments on real-world arXiv papers (81.2% were published at academic conferences), our method, using only text data, outperformed previous approaches in both automatic and human evaluations. We further conducted data-driven investigations into the two core challenges: (i) low-quality author-written captions and (ii) the absence of a standard for good captions. We found that our models could generate improved captions for figures with original captions rated as unhelpful, and the model trained on captions with more than 30 tokens produced higher-quality captions. We also found that good captions often include the high-level takeaway of the figure. Our work proves the effectiveness of text summarization in generating figure captions for scholarly articles, outperforming prior vision-based approaches. Our findings have practical implications for future figure captioning systems, improving scientific communication clarity.
Summarizing Community-based Question-Answer Pairs
Nov 17, 2022Community-based Question Answering (CQA), which allows users to acquire their desired information, has increasingly become an essential component of online services in various domains such as E-commerce, travel, and dining. However, an overwhelming number of CQA pairs makes it difficult for users without particular intent to find useful information spread over CQA pairs. To help users quickly digest the key information, we propose the novel CQA summarization task that aims to create a concise summary from CQA pairs. To this end, we first design a multi-stage data annotation process and create a benchmark dataset, CoQASUM, based on the Amazon QA corpus. We then compare a collection of extractive and abstractive summarization methods and establish a strong baseline approach DedupLED for the CQA summarization task. Our experiment further confirms two key challenges, sentence-type transfer and deduplication removal, towards the CQA summarization task. Our data and code are publicly available.
SciCap: Generating Captions for Scientific Figures
Oct 25, 2021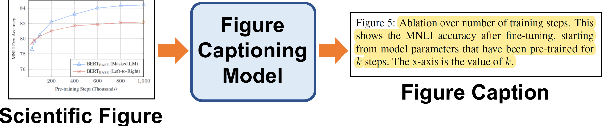


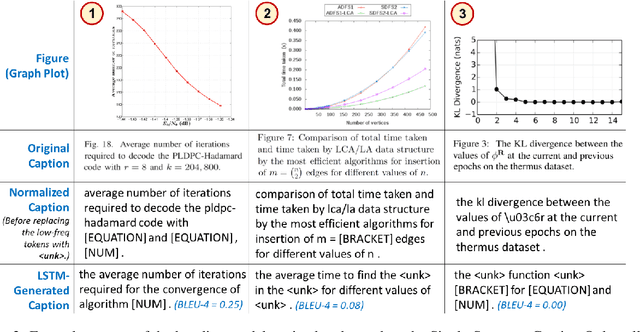
Researchers use figures to communicate rich, complex information in scientific papers. The captions of these figures are critical to conveying effective messages. However, low-quality figure captions commonly occur in scientific articles and may decrease understanding. In this paper, we propose an end-to-end neural framework to automatically generate informative, high-quality captions for scientific figures. To this end, we introduce SCICAP, a large-scale figure-caption dataset based on computer science arXiv papers published between 2010 and 2020. After pre-processing - including figure-type classification, sub-figure identification, text normalization, and caption text selection - SCICAP contained more than two million figures extracted from over 290,000 papers. We then established baseline models that caption graph plots, the dominant (19.2%) figure type. The experimental results showed both opportunities and steep challenges of generating captions for scientific figures.
Visual Story Post-Editing
Jun 05, 2019
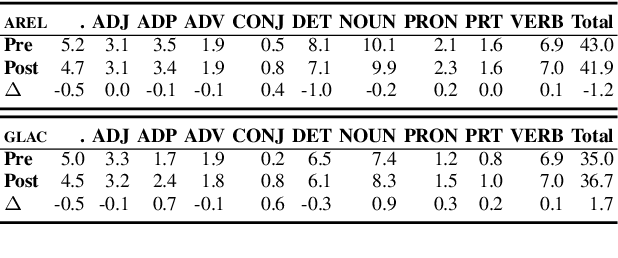
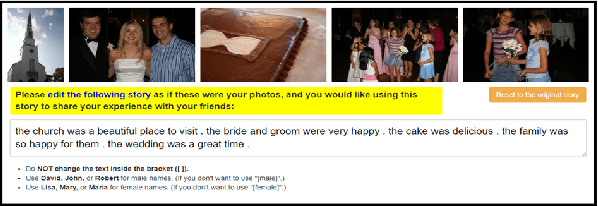

We introduce the first dataset for human edits of machine-generated visual stories and explore how these collected edits may be used for the visual story post-editing task. The dataset, VIST-Edit, includes 14,905 human edited versions of 2,981 machine-generated visual stories. The stories were generated by two state-of-the-art visual storytelling models, each aligned to 5 human-edited versions. We establish baselines for the task, showing how a relatively small set of human edits can be leveraged to boost the performance of large visual storytelling models. We also discuss the weak correlation between automatic evaluation scores and human ratings, motivating the need for new automatic metrics.