 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-LLM Collaborative Caption Generation in Scientific Documents
Jan 05, 2025



Scientific figure captioning is a complex task that requires generating contextually appropriate descriptions of visual content. However, existing methods often fall short by utilizing incomplete information, treating the task solely as either an image-to-text or text summarization problem. This limitation hinders the generation of high-quality captions that fully capture the necessary details. Moreover, existing data sourced from arXiv papers contain low-quality captions, posing significant challenges for training large language models (LLMs). In this paper, we introduce a framework called Multi-LLM Collaborative Figure Caption Generation (MLBCAP) to address these challenges by leveraging specialized LLMs for distinct sub-tasks. Our approach unfolds in three key modules: (Quality Assessment) We utilize multimodal LLMs to assess the quality of training data, enabling the filtration of low-quality captions. (Diverse Caption Generation) We then employ a strategy of fine-tuning/prompting multiple LLMs on the captioning task to generate candidate captions. (Judgment) Lastly, we prompt a prominent LLM to select the highest quality caption from the candidates, followed by refining any remaining inaccuracies. Human evaluations demonstrate that informative captions produced by our approach rank better than human-written captions, highlighting its effectiveness. Our code is available at https://github.com/teamreboott/MLBCAP
Self-accumulative Vision Transformer for Bone Age Assessment Using the Sauvegrain Method
Mar 30, 2023
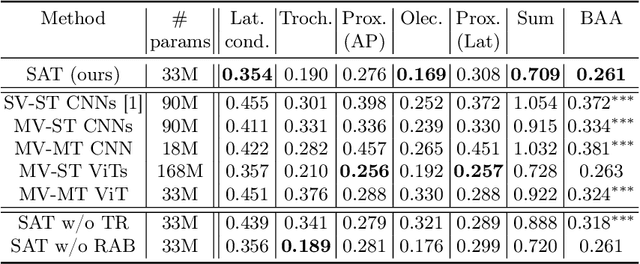
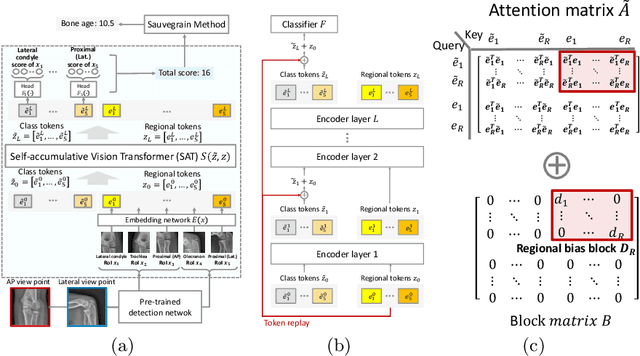
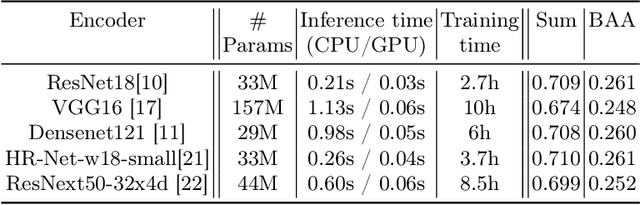
This study presents a novel approach to bone age assessment (BAA) using a multi-view, multi-task classification model based on the Sauvegrain method. A straightforward solution to automating the Sauvegrain method, which assesses a maturity score for each landmark in the elbow and predicts the bone age, is to train classifiers independently to score each region of interest (RoI), but this approach limits the accessible information to local morphologies and increases computational costs. As a result, this work proposes a self-accumulative vision transformer (SAT) that mitigates anisotropic behavior, which usually occurs in multi-view, multi-task problems and limits the effectiveness of a vision transformer, by applying token replay and regional attention bias. A number of experiments show that SAT successfully exploits the relationships between landmarks and learns global morphological features, resulting in a mean absolute error of BAA that is 0.11 lower than that of the previous work. Additionally, the proposed SAT has four times reduced parameters than an ensemble of individual classifiers of the previous work. Lastly, this work also provides informative implications for clinical practice, improving the accuracy and efficiency of BAA in diagnosing abnormal growth in adolescents.