 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sequential Recommendation for Long Term User Interest Via Personalization
Jan 07, 2026Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at \href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}.
Towards An Efficient LLM Training Paradigm for CTR Prediction
Mar 02, 2025Large Language Models (LLMs) have demonstrated tremendous potential as the next-generation ranking-based recommendation system. Many recent works have shown that LLMs can significantly outperform conventional click-through-rate (CTR) prediction approaches. Despite such promising results, the computational inefficiency inherent in the current training paradigm makes it particularly challenging to train LLMs for ranking-based recommendation tasks on large datasets. To train LLMs for CTR prediction, most existing studies adopt the prevalent ''sliding-window'' paradigm. Given a sequence of $m$ user interactions, a unique training prompt is constructed for each interaction by designating it as the prediction target along with its preceding $n$ interactions serving as context. In turn, the sliding-window paradigm results in an overall complexity of $O(mn^2)$ that scales linearly with the length of user interactions. Consequently, a direct adoption to train LLMs with such strategy can result in prohibitively high training costs as the length of interactions grows. To alleviate the computational inefficiency, we propose a novel training paradigm, namely Dynamic Target Isolation (DTI), that structurally parallelizes the training of $k$ (where $k >> 1$) target interactions. Furthermore, we identify two major bottlenecks - hidden-state leakage and positional bias overfitting - that limit DTI to only scale up to a small value of $k$ (e.g., 5) then propose a computationally light solution to effectively tackle each. Through extensive experiments on three widely adopted public CTR datasets, we empirically show that DTI reduces training time by an average of $\textbf{92%}$ (e.g., from $70.5$ hrs to $5.31$ hrs), without compromising CTR prediction performance.
Graph-based Extractive Explainer for Recommendations
Feb 20, 2022
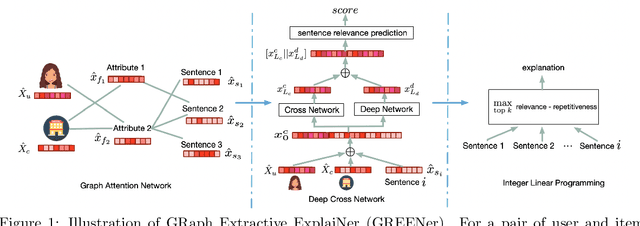

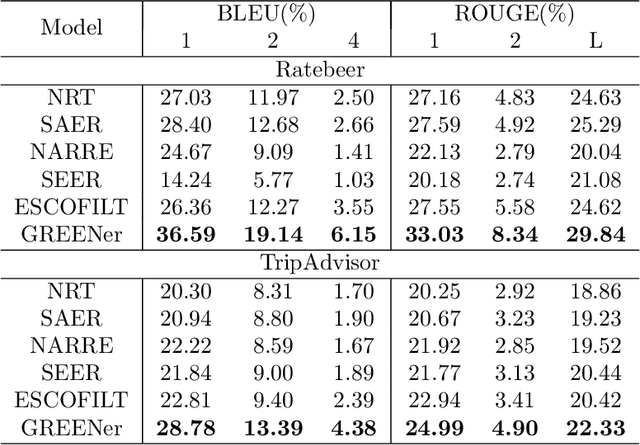
Explanations in a recommender system assist users in making informed decisions among a set of recommended items. Great research attention has been devoted to generating natural language explanations to depict how the recommendations are generated and why the users should pay attention to them. However, due to different limitations of those solutions, e.g., template-based or generation-based, it is hard to make the explanations easily perceivable, reliable and personalized at the same time. In this work, we develop a graph attentive neural network model that seamlessly integrates user, item, attributes, and sentences for extraction-based explanation. The attributes of items are selected as the intermediary to facilitate message passing for user-item specific evaluation of sentence relevance. And to balance individual sentence relevance, overall attribute coverage, and content redundancy, we solve an integer linear programming problem to make the final selection of sentences. Extensive empirical evaluations against a set of state-of-the-art baseline methods on two benchmark review datasets demonstrated the generation quality of the proposed solution.
Comparative Explanations of Recommendations
Nov 01, 2021

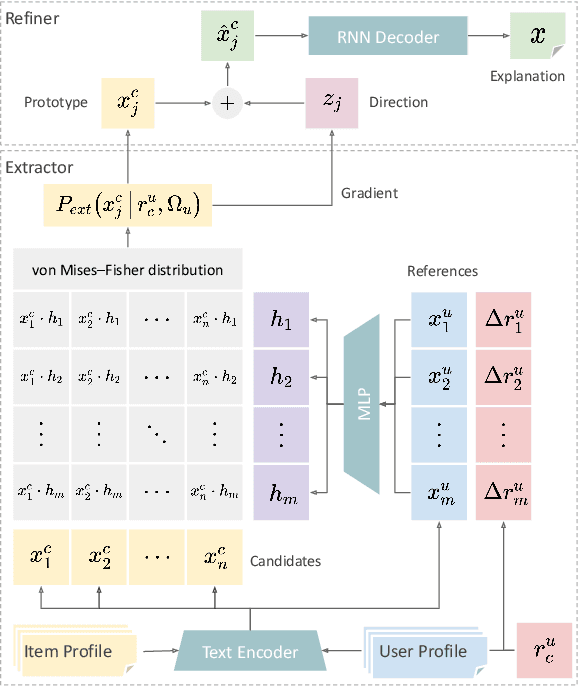
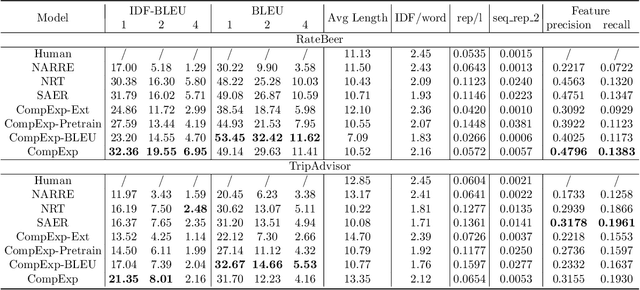
As recommendation is essentially a comparative (or ranking) process, a good explanation should illustrate to users why an item is believed to be better than another, i.e., comparative explanations about the recommended items. Ideally, after reading the explanations, a user should reach the same ranking of items as the system's. Unfortunately, little research attention has yet been paid on such comparative explanations. In this work, we develop an extract-and-refine architecture to explain the relative comparisons among a set of ranked items from a recommender system. For each recommended item, we first extract one sentence from its associated reviews that best suits the desired comparison against a set of reference items. Then this extracted sentence is further articulated with respect to the target user through a generative model to better explain why the item is recommended. We design a new explanation quality metric based on BLEU to guide the end-to-end training of the extraction and refinement components, which avoids generation of generic content. Extensive offline evaluations on two large recommendation benchmark datasets and serious user studies against an array of state-of-the-art explainable recommendation algorithms demonstrate the necessity of comparative explanations and the effectiveness of our solution.
Reversible Action Design for Combinatorial Optimization with Reinforcement Learning
Feb 14, 2021


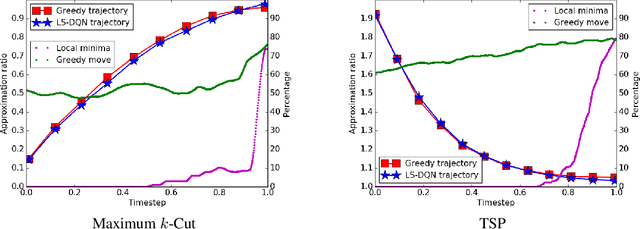
Combinatorial optimization problem (COP) over graphs is a fundamental challenge in optimization. Reinforcement learning (RL) has recently emerged as a new framework to tackle these problems and has demonstrated promising results. However, most RL solutions employ a greedy manner to construct the solution incrementally, thus inevitably pose unnecessary dependency on action sequences and need a lot of problem-specific designs. We propose a general RL framework that not only exhibits state-of-the-art empirical performance but also generalizes to a variety class of COPs. Specifically, we define state as a solution to a problem instance and action as a perturbation to this solution. We utilize graph neural networks (GNN) to extract latent representations for given problem instances for state-action encoding, and then apply deep Q-learning to obtain a policy that gradually refines the solution by flipping or swapping vertex labels. Experiments are conducted on Maximum $k$-Cut and Traveling Salesman Problem and performance improvement is achieved against a set of learning-based and heuristic baselines.
Déjà vu: A Contextualized Temporal Attention Mechanism for Sequential Recommendation
Jan 29, 2020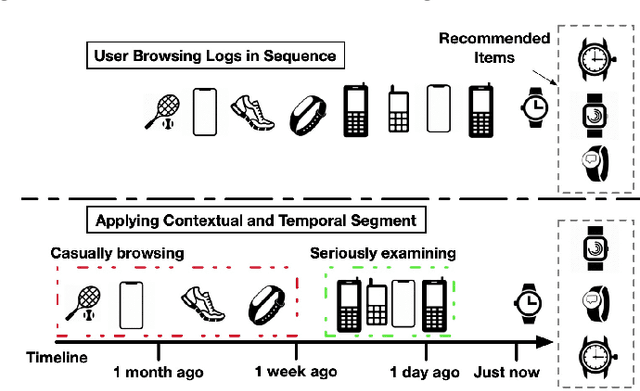
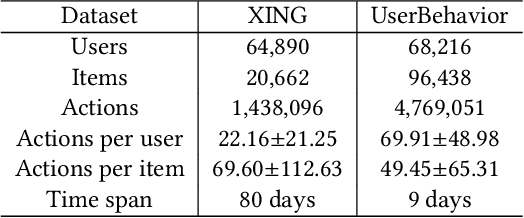
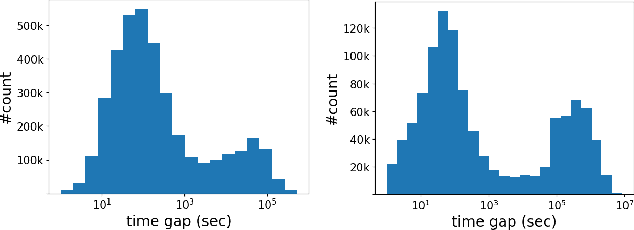

Predicting users' preferences based on their sequential behaviors in history is challenging and crucial for modern recommender systems. Most existing sequential recommendation algorithms focus on transitional structure among the sequential actions, but largely ignore the temporal and context information, when modeling the influence of a historical event to current prediction. In this paper, we argue that the influence from the past events on a user's current action should vary over the course of time and under different context. Thus, we propose a Contextualized Temporal Attention Mechanism that learns to weigh historical actions' influence on not only what action it is, but also when and how the action took place. More specifically, to dynamically calibrate the relative input dependence from the self-attention mechanism, we deploy multiple parameterized kernel functions to learn various temporal dynamics, and then use the context information to determine which of these reweighing kernels to follow for each input. In empirical evaluations on two large public recommendation datasets, our model consistently outperformed an extensive set of state-of-the-art sequential recommendation methods.