 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiniteVL: Synergizing Linear and Sparse Attention for Highly-Efficient, Unlimited-Input Vision-Language Models
Dec 09, 2025Window attention and linear attention represent two principal strategies for mitigating the quadratic complexity and ever-growing KV cache in Vision-Language Models (VLMs). However, we observe that window-based VLMs suffer performance degradation when sequence length exceeds the window size, while linear attention underperforms on information-intensive tasks such as OCR and document understanding. To overcome these limitations, we propose InfiniteVL, a linear-complexity VLM architecture that synergizes sliding window attention (SWA) with Gated DeltaNet. For achieving competitive multimodal performance under constrained resources, we design a three-stage training strategy comprising distillation pretraining, instruction tuning, and long-sequence SFT. Remarkably, using less than 2\% of the training data required by leading VLMs, InfiniteVL not only substantially outperforms previous linear-complexity VLMs but also matches the performance of leading Transformer-based VLMs, while demonstrating effective long-term memory retention. Compared to similar-sized Transformer-based VLMs accelerated by FlashAttention-2, InfiniteVL achieves over 3.6\times inference speedup while maintaining constant latency and memory footprint. In streaming video understanding scenarios, it sustains a stable 24 FPS real-time prefill speed while preserving long-term memory cache. Code and models are available at https://github.com/hustvl/InfiniteVL.
DiffusionDriveV2: Reinforcement Learning-Constrained Truncated Diffusion Modeling in End-to-End Autonomous Driving
Dec 08, 2025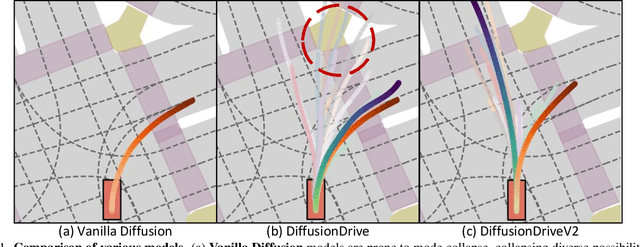
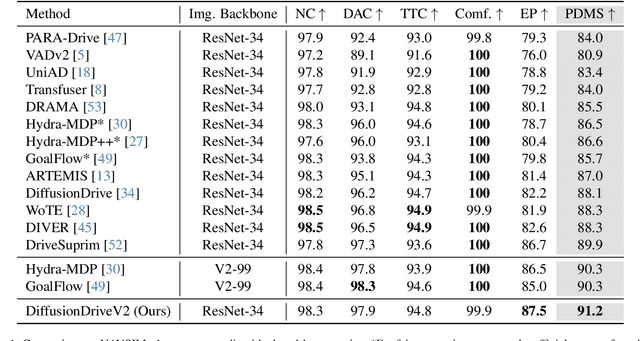
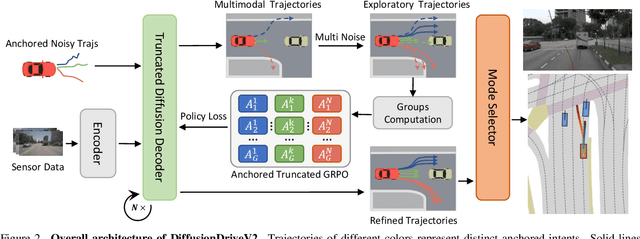
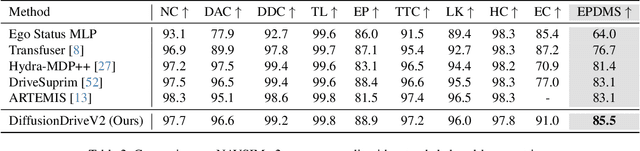
Generative diffusion models for end-to-end autonomous driving often suffer from mode collapse, tending to generate conservative and homogeneous behaviors. While DiffusionDrive employs predefined anchors representing different driving intentions to partition the action space and generate diverse trajectories, its reliance on imitation learning lacks sufficient constraints, resulting in a dilemma between diversity and consistent high quality. In this work, we propose DiffusionDriveV2, which leverages reinforcement learning to both constrain low-quality modes and explore for superior trajectories. This significantly enhances the overall output quality while preserving the inherent multimodality of its core Gaussian Mixture Model. First, we use scale-adaptive multiplicative noise, ideal for trajectory planning, to promote broad exploration. Second, we employ intra-anchor GRPO to manage advantage estimation among samples generated from a single anchor, and inter-anchor truncated GRPO to incorporate a global perspective across different anchors, preventing improper advantage comparisons between distinct intentions (e.g., turning vs. going straight), which can lead to further mode collapse. DiffusionDriveV2 achieves 91.2 PDMS on the NAVSIM v1 dataset and 85.5 EPDMS on the NAVSIM v2 dataset in closed-loop evaluation with an aligned ResNet-34 backbone, setting a new record. Further experiments validate that our approach resolves the dilemma between diversity and consistent high quality for truncated diffusion models, achieving the best trade-off. Code and model will be available at https://github.com/hustvl/DiffusionDriveV2
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
AlphaDrive: Unleashing the Power of VLMs in Autonomous Driving via Reinforcement Learning and Reasoning
Mar 10, 2025OpenAI o1 and DeepSeek R1 achieve or even surpass human expert-level performance in complex domains like mathematics and science, with reinforcement learning (RL) and reasoning playing a crucial role. In autonomous driving, recent end-to-end models have greatly improved planning performance but still struggle with long-tailed problems due to limited common sense and reasoning abilities. Some studies integrate vision-language models (VLMs) into autonomous driving, but they typically rely on pre-trained models with simple supervised fine-tuning (SFT) on driving data, without further exploration of training strategies or optimizations specifically tailored for planning. In this paper, we propose AlphaDrive, a RL and reasoning framework for VLMs in autonomous driving. AlphaDrive introduces four GRPO-based RL rewards tailored for planning and employs a two-stage planning reasoning training strategy that combines SFT with RL. As a result, AlphaDrive significantly improves both planning performance and training efficiency compared to using only SFT or without reasoning. Moreover, we are also excited to discover that, following RL training, AlphaDrive exhibits some emergent multimodal planning capabilities, which is critical for improving driving safety and efficiency. To the best of our knowledge, AlphaDrive is the first to integrate GRPO-based RL with planning reasoning into autonomous driving. Code will be released to facilitate future research.
RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning
Feb 18, 2025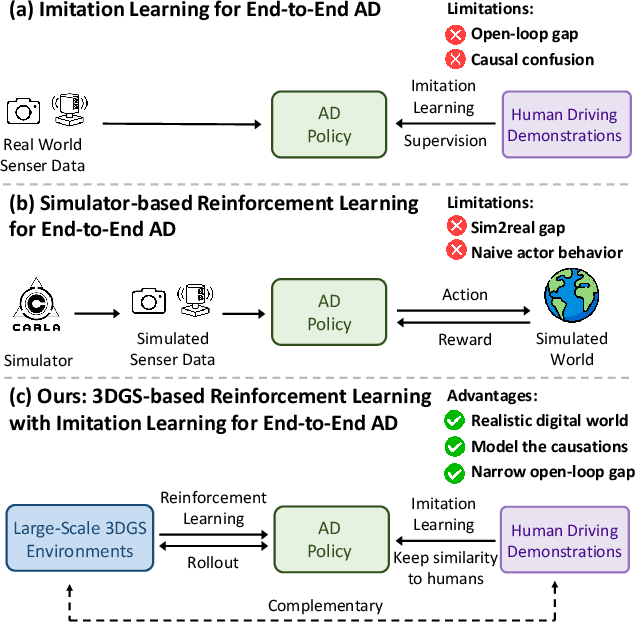
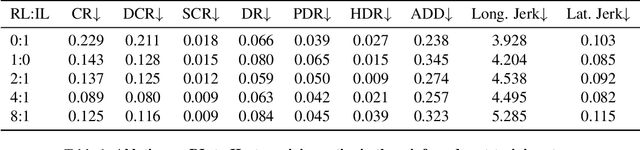
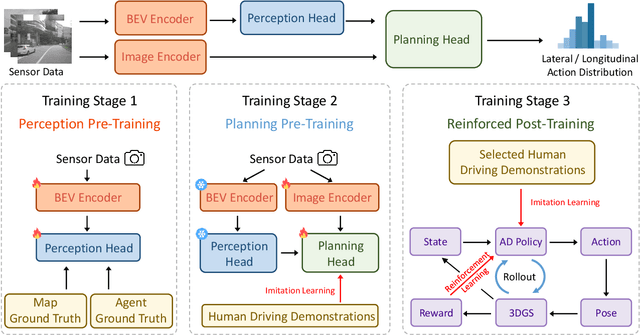
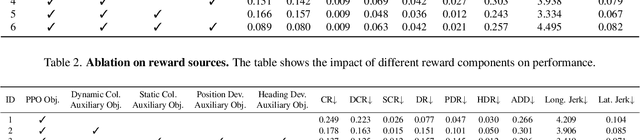
Existing end-to-end autonomous driving (AD) algorithms typically follow the Imitation Learning (IL) paradigm, which faces challenges such as causal confusion and the open-loop gap. In this work, we establish a 3DGS-based closed-loop Reinforcement Learning (RL) training paradigm. By leveraging 3DGS techniques, we construct a photorealistic digital replica of the real physical world, enabling the AD policy to extensively explore the state space and learn to handle out-of-distribution scenarios through large-scale trial and error. To enhance safety, we design specialized rewards that guide the policy to effectively respond to safety-critical events and understand real-world causal relationships. For better alignment with human driving behavior, IL is incorporated into RL training as a regularization term. We introduce a closed-loop evaluation benchmark consisting of diverse, previously unseen 3DGS environments. Compared to IL-based methods, RAD achieves stronger performance in most closed-loop metrics, especially 3x lower collision rate. Abundant closed-loop results are presented at https://hgao-cv.github.io/RAD.
DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving
Nov 22, 2024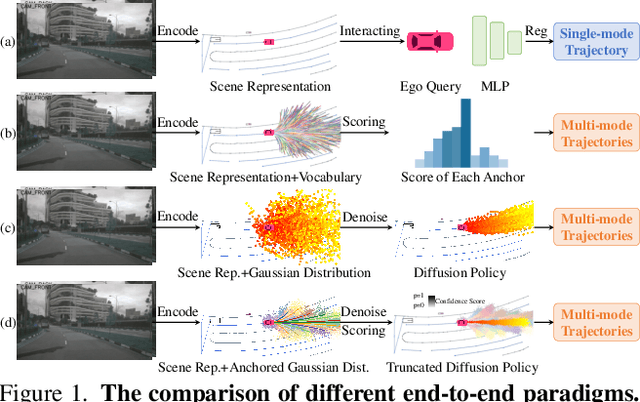

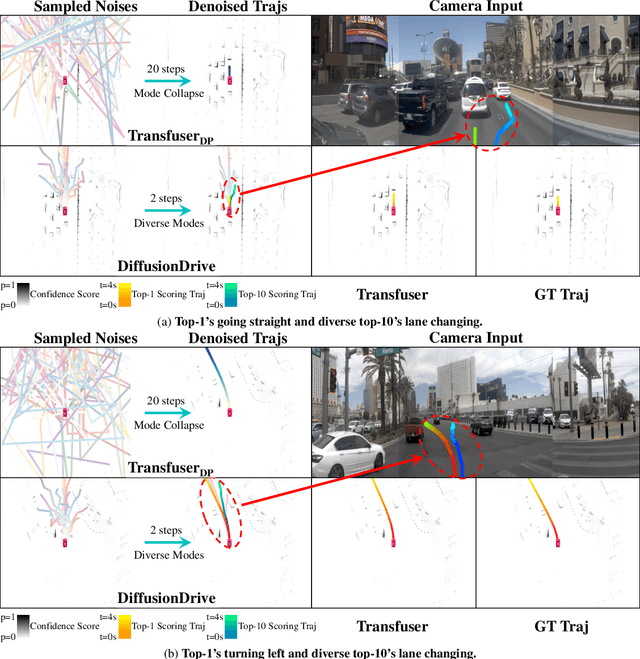

Recently, the diffusion model has emerged as a powerful generative technique for robotic policy learning, capable of modeling multi-mode action distributions. Leveraging its capability for end-to-end autonomous driving is a promising direction. However, the numerous denoising steps in the robotic diffusion policy and the more dynamic, open-world nature of traffic scenes pose substantial challenges for generating diverse driving actions at a real-time speed. To address these challenges, we propose a novel truncated diffusion policy that incorporates prior multi-mode anchors and truncates the diffusion schedule, enabling the model to learn denoising from anchored Gaussian distribution to the multi-mode driving action distribution. Additionally, we design an efficient cascade diffusion decoder for enhanced interaction with conditional scene context. The proposed model, DiffusionDrive, demonstrates 10$\times$ reduction in denoising steps compared to vanilla diffusion policy, delivering superior diversity and quality in just 2 steps. On the planning-oriented NAVSIM dataset, with the aligned ResNet-34 backbone, DiffusionDrive achieves 88.1 PDMS without bells and whistles, setting a new record, while running at a real-time speed of 45 FPS on an NVIDIA 4090. Qualitative results on challenging scenarios further confirm that DiffusionDrive can robustly generate diverse plausible driving actions. Code and model will be available at https://github.com/hustvl/DiffusionDrive.
Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
Oct 29, 2024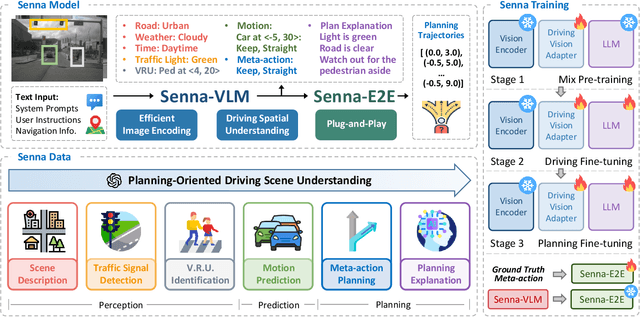
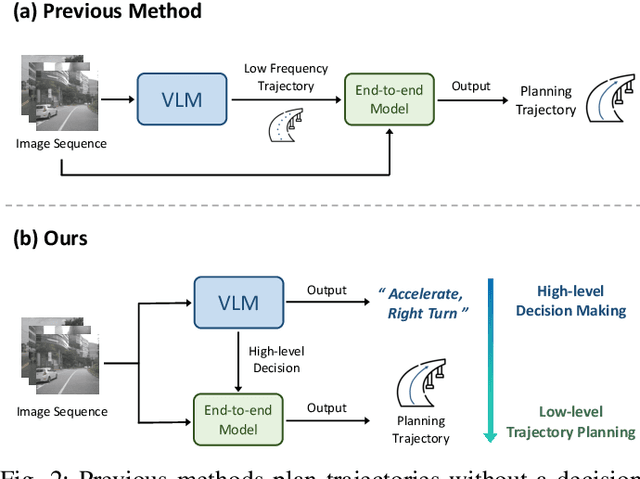
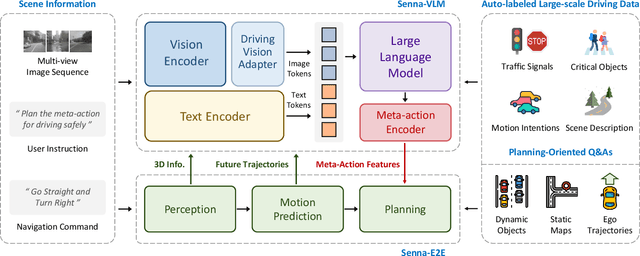

End-to-end autonomous driving demonstrates strong planning capabilities with large-scale data but still struggles in complex, rare scenarios due to limited commonsense. In contrast, Large Vision-Language Models (LVLMs) excel in scene understanding and reasoning. The path forward lies in merging the strengths of both approaches. Previous methods using LVLMs to predict trajectories or control signals yield suboptimal results, as LVLMs are not well-suited for precise numerical predictions. This paper presents Senna, an autonomous driving system combining an LVLM (Senna-VLM) with an end-to-end model (Senna-E2E). Senna decouples high-level planning from low-level trajectory prediction. Senna-VLM generates planning decisions in natural language, while Senna-E2E predicts precise trajectories. Senna-VLM utilizes a multi-image encoding approach and multi-view prompts for efficient scene understanding. Besides, we introduce planning-oriented QAs alongside a three-stage training strategy, which enhances Senna-VLM's planning performance while preserving commonsense. Extensive experiments on two datasets show that Senna achieves state-of-the-art planning performance. Notably, with pre-training on a large-scale dataset DriveX and fine-tuning on nuScenes, Senna significantly reduces average planning error by 27.12% and collision rate by 33.33% over model without pre-training. We believe Senna's cross-scenario generalization and transferability are essential for achieving fully autonomous driving. Code and models will be released at https://github.com/hustvl/Senna.
ARTiST: Automated Text Simplification for Task Guidance in Augmented Reality
Feb 29, 2024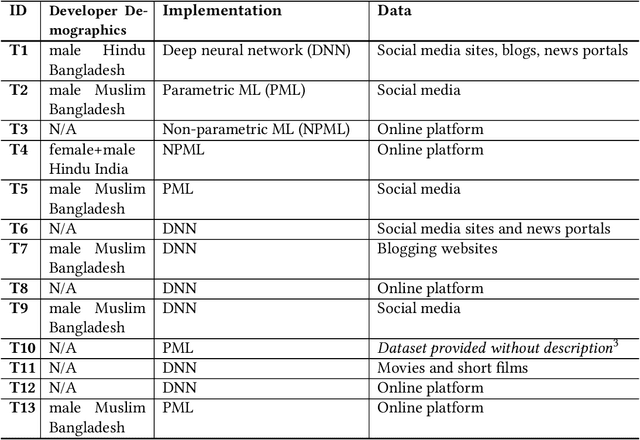
Text presented in augmented reality provides in-situ, real-time information for users. However, this content can be challenging to apprehend quickly when engaging in cognitively demanding AR tasks, especially when it is presented on a head-mounted display. We propose ARTiST, an automatic text simplification system that uses a few-shot prompt and GPT-3 models to specifically optimize the text length and semantic content for augmented reality. Developed out of a formative study that included seven users and three experts, our system combines a customized error calibration model with a few-shot prompt to integrate the syntactic, lexical, elaborative, and content simplification techniques, and generate simplified AR text for head-worn displays. Results from a 16-user empirical study showed that ARTiST lightens the cognitive load and improves performance significantly over both unmodified text and text modified via traditional methods. Our work constitutes a step towards automating the optimization of batch text data for readability and performance in augmented reality.
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Feb 20, 2024



Learning a human-like driving policy from large-scale driving demonstrations is promising, but the uncertainty and non-deterministic nature of planning make it challenging. In this work, to cope with the uncertainty problem, we propose VADv2, an end-to-end driving model based on probabilistic planning. VADv2 takes multi-view image sequences as input in a streaming manner, transforms sensor data into environmental token embeddings, outputs the probabilistic distribution of action, and samples one action to control the vehicle. Only with camera sensors, VADv2 achieves state-of-the-art closed-loop performance on the CARLA Town05 benchmark, significantly outperforming all existing methods. It runs stably in a fully end-to-end manner, even without the rule-based wrapper. Closed-loop demos are presented at https://hgao-cv.github.io/VADv2.
MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction
Aug 10, 2023



High-definition (HD) map provides abundant and precise static environmental information of the driving scene, serving as a fundamental and indispensable component for planning in autonomous driving system. In this paper, we present \textbf{Map} \textbf{TR}ansformer, an end-to-end framework for online vectorized HD map construction. We propose a unified permutation-equivalent modeling approach, \ie, modeling map element as a point set with a group of equivalent permutations, which accurately describes the shape of map element and stabilizes the learning process. We design a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. To speed up convergence, we further introduce auxiliary one-to-many matching and dense supervision. The proposed method well copes with various map elements with arbitrary shapes. It runs at real-time inference speed and achieves state-of-the-art performance on both nuScenes and Argoverse2 datasets. Abundant qualitative results show stable and robust map construction quality in complex and various driving scenes. Code and more demos are available at \url{https://github.com/hustvl/MapTR} for facilitating further studies and applications.