 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynSUP: Dynamic Gaussian Splatting from An Unposed Image Pair
Dec 01, 2024
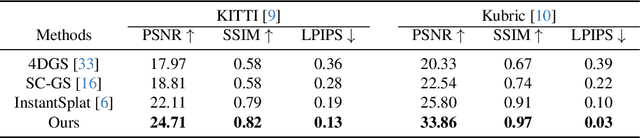
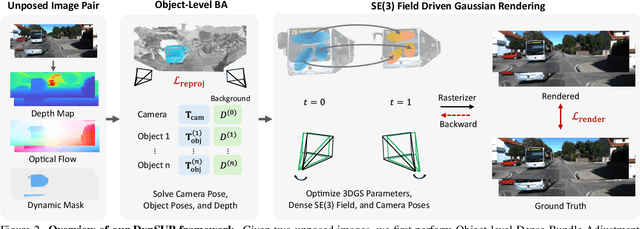
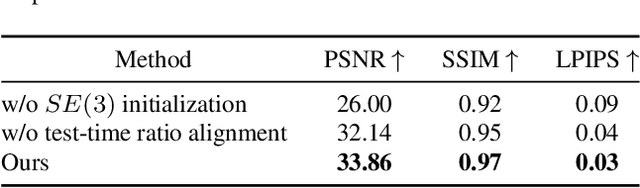
Recent advances in 3D Gaussian Splatting have shown promising results. Existing methods typically assume static scenes and/or multiple images with prior poses. Dynamics, sparse views, and unknown poses significantly increase the problem complexity due to insufficient geometric constraints. To overcome this challenge, we propose a method that can use only two images without prior poses to fit Gaussians in dynamic environments. To achieve this, we introduce two technical contributions. First, we propose an object-level two-view bundle adjustment. This strategy decomposes dynamic scenes into piece-wise rigid components, and jointly estimates the camera pose and motions of dynamic objects. Second, we design an SE(3) field-driven Gaussian training method. It enables fine-grained motion modeling through learnable per-Gaussian transformations. Our method leads to high-fidelity novel view synthesis of dynamic scenes while accurately preserving temporal consistency and object motion. Experiments on both synthetic and real-world datasets demonstrate that our method significantly outperforms state-of-the-art approaches designed for the cases of static environments, multiple images, and/or known poses. Our project page is available at https://colin-de.github.io/DynSUP/.
VAD: Vectorized Scene Representation for Efficient Autonomous Driving
Mar 21, 2023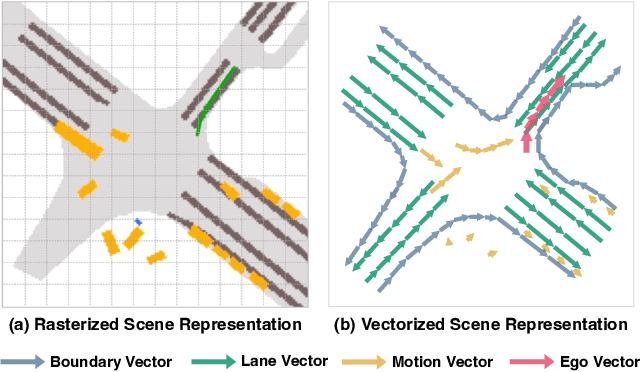
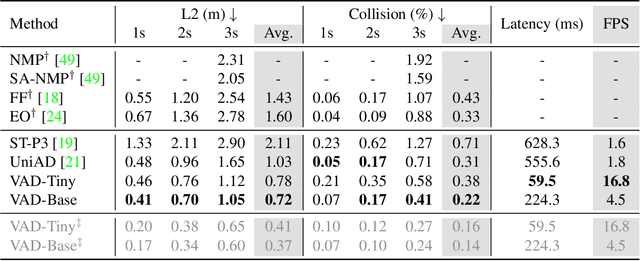
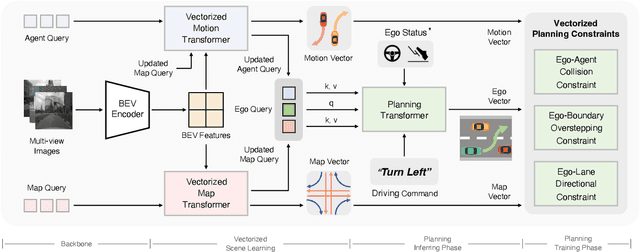
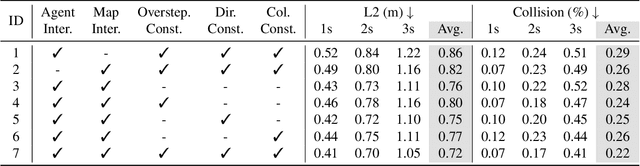
Autonomous driving requires a comprehensive understanding of the surrounding environment for reliable trajectory planning. Previous works rely on dense rasterized scene representation (e.g., agent occupancy and semantic map) to perform planning, which is computationally intensive and misses the instance-level structure information. In this paper, we propose VAD, an end-to-end vectorized paradigm for autonomous driving, which models the driving scene as fully vectorized representation. The proposed vectorized paradigm has two significant advantages. On one hand, VAD exploits the vectorized agent motion and map elements as explicit instance-level planning constraints which effectively improves planning safety. On the other hand, VAD runs much faster than previous end-to-end planning methods by getting rid of computation-intensive rasterized representation and hand-designed post-processing steps. VAD achieves state-of-the-art end-to-end planning performance on the nuScenes dataset, outperforming the previous best method by a large margin (reducing the average collision rate by 48.4%). Besides, VAD greatly improves the inference speed (up to 9.3x), which is critical for the real-world deployment of an autonomous driving system. Code and models will be released for facilitating future research.
Optimized Hybrid Focal Margin Loss for Crack Segmentation
Feb 09, 2023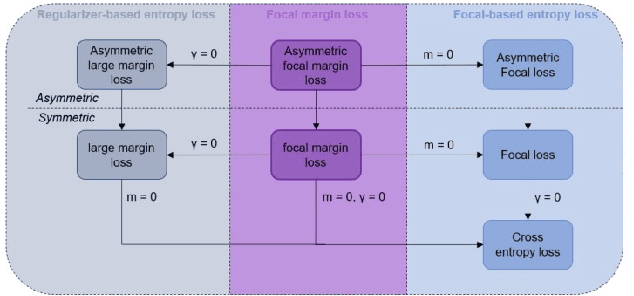
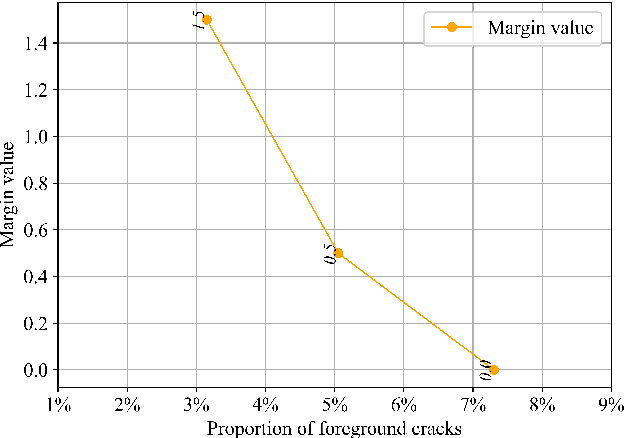

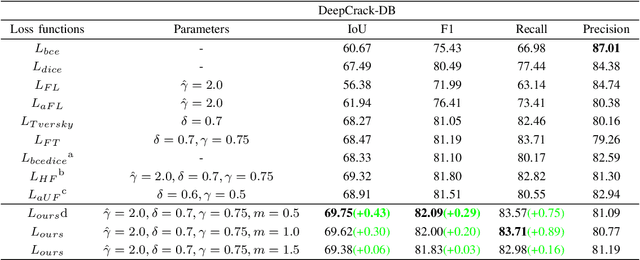
Many loss functions have been derived from cross-entropy loss functions such as large-margin softmax loss and focal loss. The large-margin softmax loss makes the classification more rigorous and prevents overfitting. The focal loss alleviates class imbalance in object detection by down-weighting the loss of well-classified examples. Recent research has shown that these two loss functions derived from cross entropy have valuable applications in the field of image segmentation. However, to the best of our knowledge, there is no unified formulation that combines these two loss functions so that they can not only be transformed mutually, but can also be used to simultaneously address class imbalance and overfitting. To this end, we subdivide the entropy-based loss into the regularizer-based entropy loss and the focal-based entropy loss, and propose a novel optimized hybrid focal loss to handle extreme class imbalance and prevent overfitting for crack segmentation. We have evaluated our proposal in comparison with three crack segmentation datasets (DeepCrack-DB, CRACK500 and our private PanelCrack dataset). Our experiments demonstrate that the focal margin component can significantly increase the IoU of cracks by 0.43 on DeepCrack-DB and 0.44 on our PanelCrack dataset, respectively.
Perceive, Interact, Predict: Learning Dynamic and Static Clues for End-to-End Motion Prediction
Dec 05, 2022



Motion prediction is highly relevant to the perception of dynamic objects and static map elements in the scenarios of autonomous driving. In this work, we propose PIP, the first end-to-end Transformer-based framework which jointly and interactively performs online mapping, object detection and motion prediction. PIP leverages map queries, agent queries and mode queries to encode the instance-wise information of map elements, agents and motion intentions, respectively. Based on the unified query representation, a differentiable multi-task interaction scheme is proposed to exploit the correlation between perception and prediction. Even without human-annotated HD map or agent's historical tracking trajectory as guidance information, PIP realizes end-to-end multi-agent motion prediction and achieves better performance than tracking-based and HD-map-based methods. PIP provides comprehensive high-level information of the driving scene (vectorized static map and dynamic objects with motion information), and contributes to the downstream planning and control. Code and models will be released for facilitating further research.
HOPE: Hierarchical Spatial-temporal Network for Occupancy Flow Prediction
Jun 21, 2022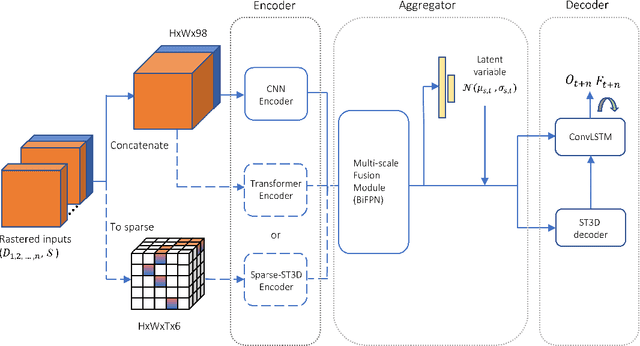

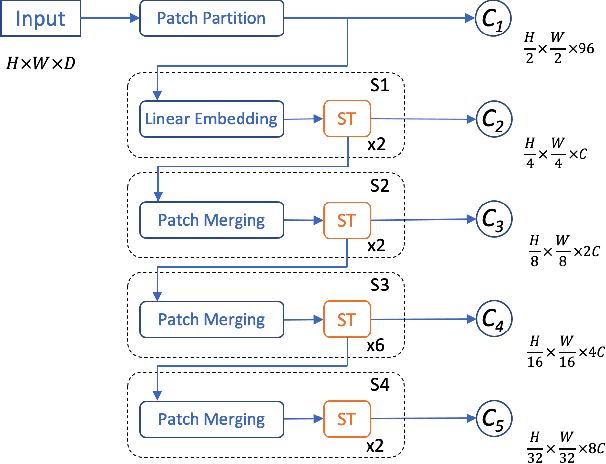
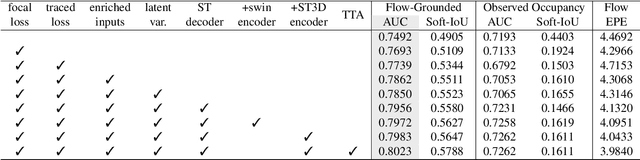
In this report, we introduce our solution to the Occupancy and Flow Prediction challenge in the Waymo Open Dataset Challenges at CVPR 2022, which ranks 1st on the leaderboard. We have developed a novel hierarchical spatial-temporal network featured with spatial-temporal encoders, a multi-scale aggregator enriched with latent variables, and a recursive hierarchical 3D decoder. We use multiple losses including focal loss and modified flow trace loss to efficiently guide the training process. Our method achieves a Flow-Grounded Occupancy AUC of 0.8389 and outperforms all the other teams on the leaderboard.
Rethinking Soft Labels for Knowledge Distillation: A Bias-Variance Tradeoff Perspective
Feb 01, 2021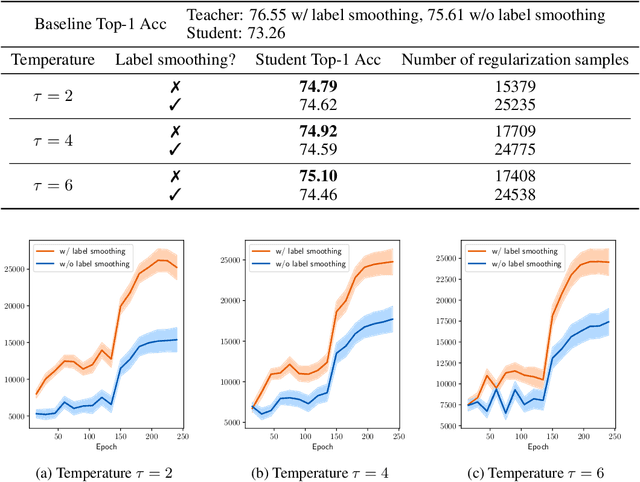
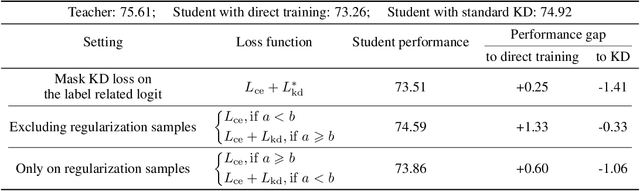

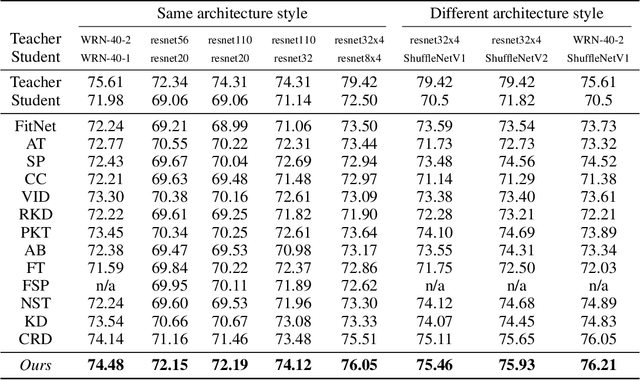
Knowledge distillation is an effective approach to leverage a well-trained network or an ensemble of them, named as the teacher, to guide the training of a student network. The outputs from the teacher network are used as soft labels for supervising the training of a new network. Recent studies \citep{muller2019does,yuan2020revisiting} revealed an intriguing property of the soft labels that making labels soft serves as a good regularization to the student network. From the perspective of statistical learning, regularization aims to reduce the variance, however how bias and variance change is not clear for training with soft labels. In this paper, we investigate the bias-variance tradeoff brought by distillation with soft labels. Specifically, we observe that during training the bias-variance tradeoff varies sample-wisely. Further, under the same distillation temperature setting, we observe that the distillation performance is negatively associated with the number of some specific samples, which are named as regularization samples since these samples lead to bias increasing and variance decreasing. Nevertheless, we empirically find that completely filtering out regularization samples also deteriorates distillation performance. Our discoveries inspired us to propose the novel weighted soft labels to help the network adaptively handle the sample-wise bias-variance tradeoff. Experiments on standard evaluation benchmarks validate the effectiveness of our method. Our code is available at \url{https://github.com/bellymonster/Weighted-Soft-Label-Distillation}.