 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCA-on-the-Line: Benchmarking Out-of-Distribution Generalization with Class Taxonomies
Jul 22, 2024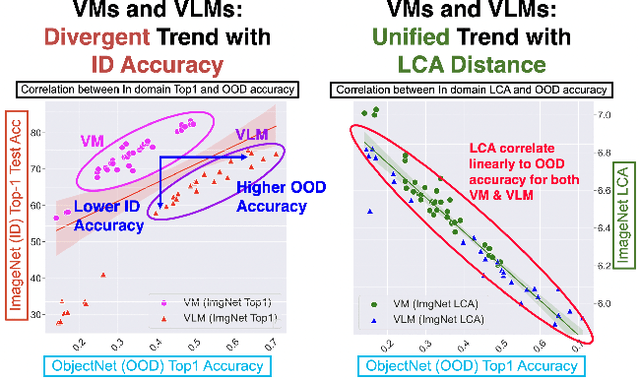
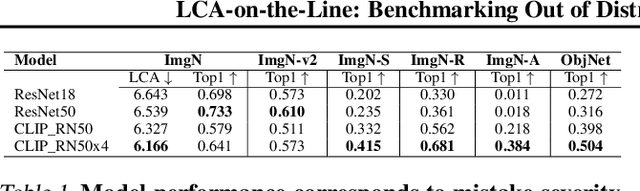
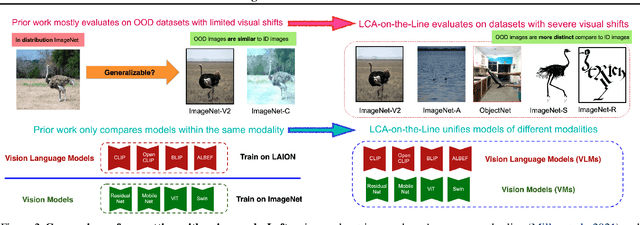
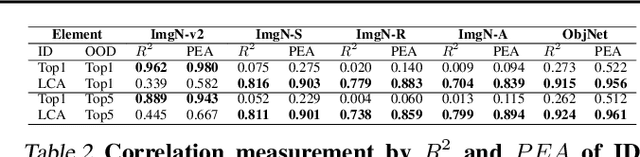
We tackle the challenge of predicting models' Out-of-Distribution (OOD) performance using in-distribution (ID) measurements without requiring OOD data. Existing evaluations with "Effective Robustness", which use ID accuracy as an indicator of OOD accuracy, encounter limitations when models are trained with diverse supervision and distributions, such as class labels (Vision Models, VMs, on ImageNet) and textual descriptions (Visual-Language Models, VLMs, on LAION). VLMs often generalize better to OOD data than VMs despite having similar or lower ID performance. To improve the prediction of models' OOD performance from ID measurements, we introduce the Lowest Common Ancestor (LCA)-on-the-Line framework. This approach revisits the established concept of LCA distance, which measures the hierarchical distance between labels and predictions within a predefined class hierarchy, such as WordNet. We assess 75 models using ImageNet as the ID dataset and five significantly shifted OOD variants, uncovering a strong linear correlation between ID LCA distance and OOD top-1 accuracy. Our method provides a compelling alternative for understanding why VLMs tend to generalize better. Additionally, we propose a technique to construct a taxonomic hierarchy on any dataset using K-means clustering, demonstrating that LCA distance is robust to the constructed taxonomic hierarchy. Moreover, we demonstrate that aligning model predictions with class taxonomies, through soft labels or prompt engineering, can enhance model generalization. Open source code in our Project Page: https://elvishelvis.github.io/papers/lca/.
Solving Motion Planning Tasks with a Scalable Generative Model
Jul 03, 2024



As autonomous driving systems being deployed to millions of vehicles, there is a pressing need of improving the system's scalability, safety and reducing the engineering cost. A realistic, scalable, and practical simulator of the driving world is highly desired. In this paper, we present an efficient solution based on generative models which learns the dynamics of the driving scenes. With this model, we can not only simulate the diverse futures of a given driving scenario but also generate a variety of driving scenarios conditioned on various prompts. Our innovative design allows the model to operate in both full-Autoregressive and partial-Autoregressive modes, significantly improving inference and training speed without sacrificing generative capability. This efficiency makes it ideal for being used as an online reactive environment for reinforcement learning, an evaluator for planning policies, and a high-fidelity simulator for testing. We evaluated our model against two real-world datasets: the Waymo motion dataset and the nuPlan dataset. On the simulation realism and scene generation benchmark, our model achieves the state-of-the-art performance. And in the planning benchmarks, our planner outperforms the prior arts. We conclude that the proposed generative model may serve as a foundation for a variety of motion planning tasks, including data generation, simulation, planning, and online training. Source code is public at https://github.com/HorizonRobotics/GUMP/
ITI-GEN: Inclusive Text-to-Image Generation
Sep 11, 2023



Text-to-image generative models often reflect the biases of the training data, leading to unequal representations of underrepresented groups. This study investigates inclusive text-to-image generative models that generate images based on human-written prompts and ensure the resulting images are uniformly distributed across attributes of interest. Unfortunately, directly expressing the desired attributes in the prompt often leads to sub-optimal results due to linguistic ambiguity or model misrepresentation. Hence, this paper proposes a drastically different approach that adheres to the maxim that "a picture is worth a thousand words". We show that, for some attributes, images can represent concepts more expressively than text. For instance, categories of skin tones are typically hard to specify by text but can be easily represented by example images. Building upon these insights, we propose a novel approach, ITI-GEN, that leverages readily available reference images for Inclusive Text-to-Image GENeration. The key idea is learning a set of prompt embeddings to generate images that can effectively represent all desired attribute categories. More importantly, ITI-GEN requires no model fine-tuning, making it computationally efficient to augment existing text-to-image models. Extensive experiments demonstrate that ITI-GEN largely improves over state-of-the-art models to generate inclusive images from a prompt. Project page: https://czhang0528.github.io/iti-gen.
Goal-oriented Autonomous Driving
Dec 20, 2022



Modern autonomous driving system is characterized as modular tasks in sequential order, i.e., perception, prediction and planning. As sensors and hardware get improved, there is trending popularity to devise a system that can perform a wide diversity of tasks to fulfill higher-level intelligence. Contemporary approaches resort to either deploying standalone models for individual tasks, or designing a multi-task paradigm with separate heads. These might suffer from accumulative error or negative transfer effect. Instead, we argue that a favorable algorithm framework should be devised and optimized in pursuit of the ultimate goal, i.e. planning of the self-driving-car. Oriented at this goal, we revisit the key components within perception and prediction. We analyze each module and prioritize the tasks hierarchically, such that all these tasks contribute to planning (the goal). To this end, we introduce Unified Autonomous Driving (UniAD), the first comprehensive framework up-to-date that incorporates full-stack driving tasks in one network. It is exquisitely devised to leverage advantages of each module, and provide complementary feature abstractions for agent interaction from a global perspective. Tasks are communicated with unified query design to facilitate each other toward planning. We instantiate UniAD on the challenging nuScenes benchmark. With extensive ablations, the effectiveness of using such a philosophy is proven to surpass previous state-of-the-arts by a large margin in all aspects. The full suite of codebase and models would be available to facilitate future research in the community.
HOPE: Hierarchical Spatial-temporal Network for Occupancy Flow Prediction
Jun 21, 2022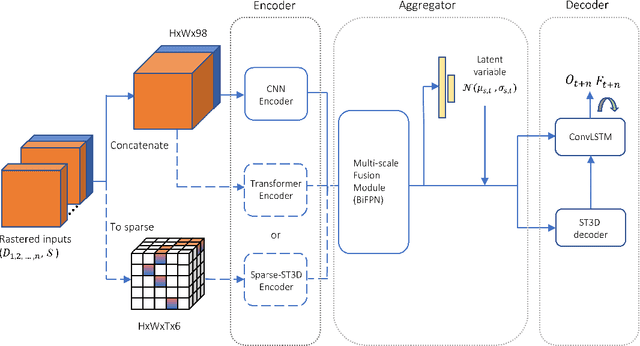

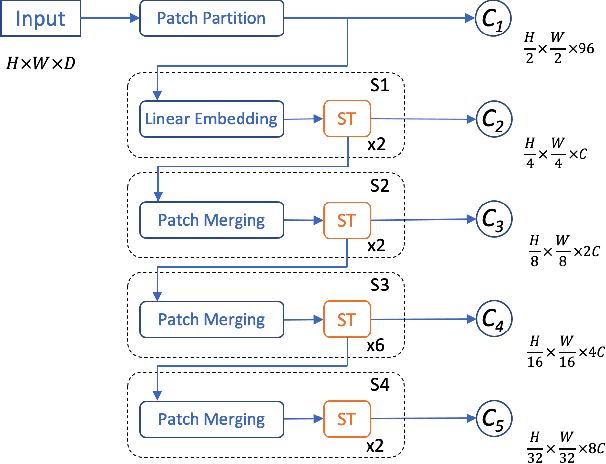
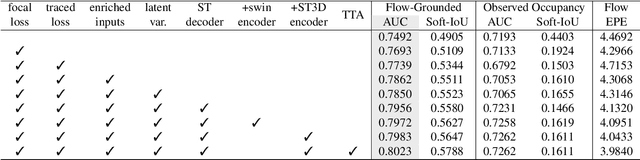
In this report, we introduce our solution to the Occupancy and Flow Prediction challenge in the Waymo Open Dataset Challenges at CVPR 2022, which ranks 1st on the leaderboard. We have developed a novel hierarchical spatial-temporal network featured with spatial-temporal encoders, a multi-scale aggregator enriched with latent variables, and a recursive hierarchical 3D decoder. We use multiple losses including focal loss and modified flow trace loss to efficiently guide the training process. Our method achieves a Flow-Grounded Occupancy AUC of 0.8389 and outperforms all the other teams on the leaderboard.