 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning
Feb 18, 2025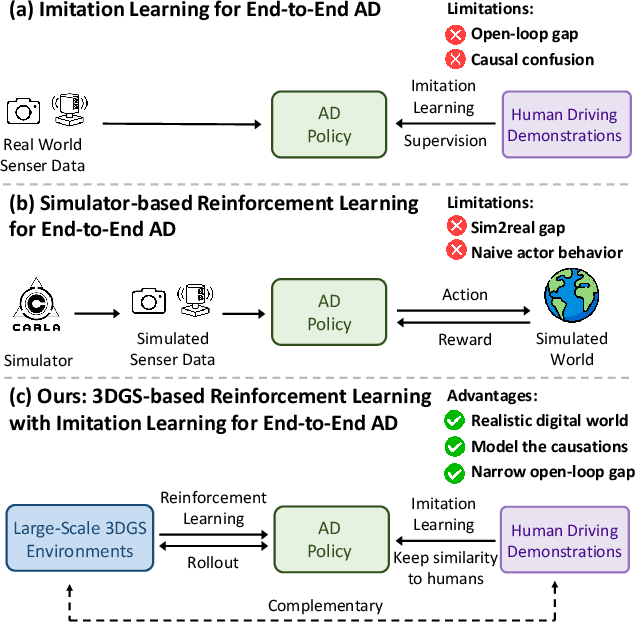
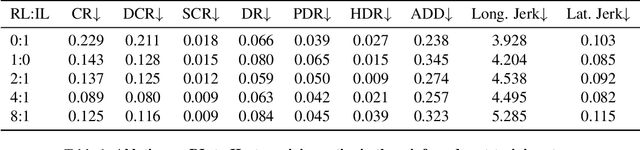
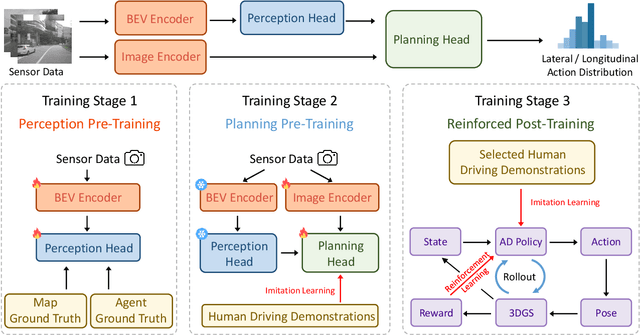
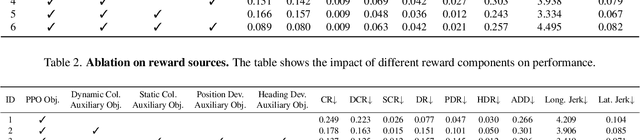
Existing end-to-end autonomous driving (AD) algorithms typically follow the Imitation Learning (IL) paradigm, which faces challenges such as causal confusion and the open-loop gap. In this work, we establish a 3DGS-based closed-loop Reinforcement Learning (RL) training paradigm. By leveraging 3DGS techniques, we construct a photorealistic digital replica of the real physical world, enabling the AD policy to extensively explore the state space and learn to handle out-of-distribution scenarios through large-scale trial and error. To enhance safety, we design specialized rewards that guide the policy to effectively respond to safety-critical events and understand real-world causal relationships. For better alignment with human driving behavior, IL is incorporated into RL training as a regularization term. We introduce a closed-loop evaluation benchmark consisting of diverse, previously unseen 3DGS environments. Compared to IL-based methods, RAD achieves stronger performance in most closed-loop metrics, especially 3x lower collision rate. Abundant closed-loop results are presented at https://hgao-cv.github.io/RAD.
DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving
Nov 22, 2024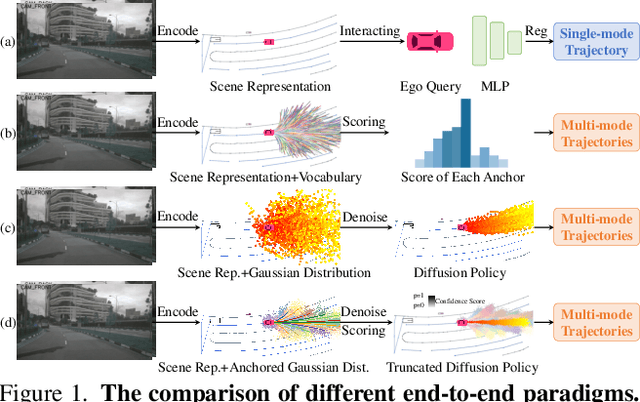

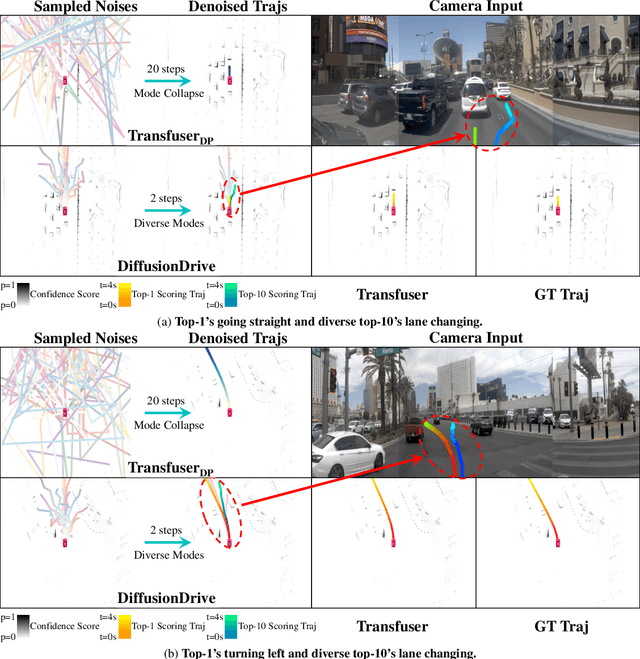

Recently, the diffusion model has emerged as a powerful generative technique for robotic policy learning, capable of modeling multi-mode action distributions. Leveraging its capability for end-to-end autonomous driving is a promising direction. However, the numerous denoising steps in the robotic diffusion policy and the more dynamic, open-world nature of traffic scenes pose substantial challenges for generating diverse driving actions at a real-time speed. To address these challenges, we propose a novel truncated diffusion policy that incorporates prior multi-mode anchors and truncates the diffusion schedule, enabling the model to learn denoising from anchored Gaussian distribution to the multi-mode driving action distribution. Additionally, we design an efficient cascade diffusion decoder for enhanced interaction with conditional scene context. The proposed model, DiffusionDrive, demonstrates 10$\times$ reduction in denoising steps compared to vanilla diffusion policy, delivering superior diversity and quality in just 2 steps. On the planning-oriented NAVSIM dataset, with the aligned ResNet-34 backbone, DiffusionDrive achieves 88.1 PDMS without bells and whistles, setting a new record, while running at a real-time speed of 45 FPS on an NVIDIA 4090. Qualitative results on challenging scenarios further confirm that DiffusionDrive can robustly generate diverse plausible driving actions. Code and model will be available at https://github.com/hustvl/DiffusionDrive.
Differentiable Architecture Search with Ensemble Gumbel-Softmax
May 06, 2019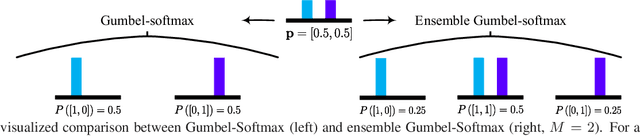
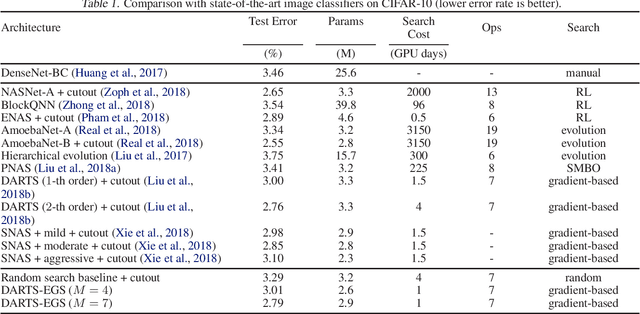
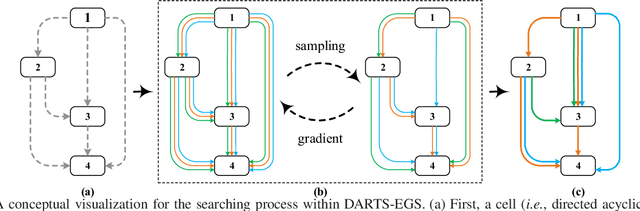
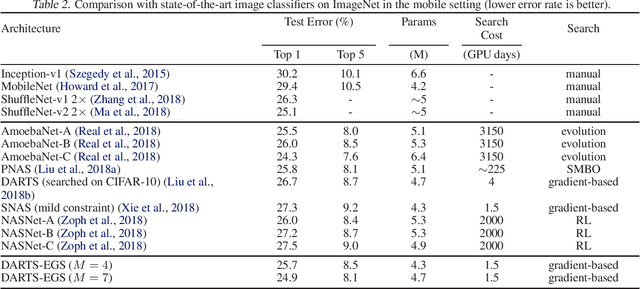
For network architecture search (NAS), it is crucial but challenging to simultaneously guarantee both effectiveness and efficiency. Towards achieving this goal, we develop a differentiable NAS solution, where the search space includes arbitrary feed-forward network consisting of the predefined number of connections. Benefiting from a proposed ensemble Gumbel-Softmax estimator, our method optimizes both the architecture of a deep network and its parameters in the same round of backward propagation, yielding an end-to-end mechanism of searching network architectures. Extensive experiments on a variety of popular datasets strongly evidence that our method is capable of discovering high-performance architectures, while guaranteeing the requisite efficiency during searching.
EAT-NAS: Elastic Architecture Transfer for Accelerating Large-scale Neural Architecture Search
Jan 17, 2019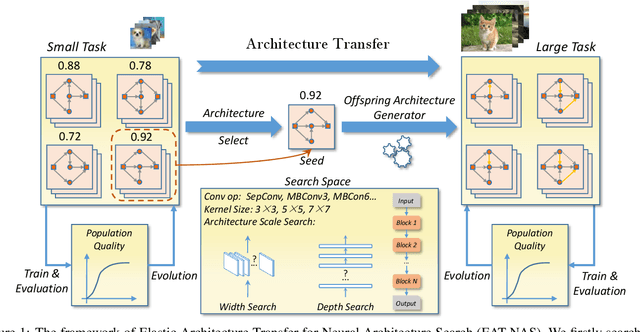
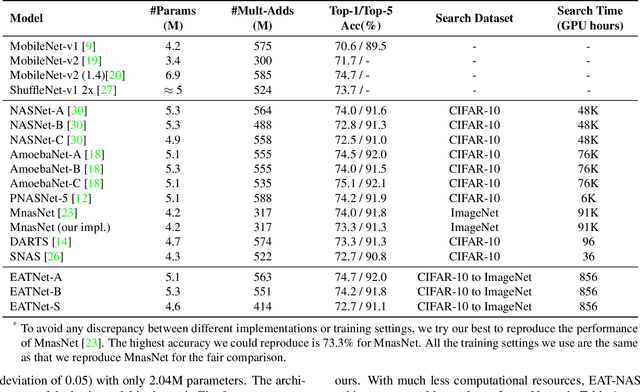
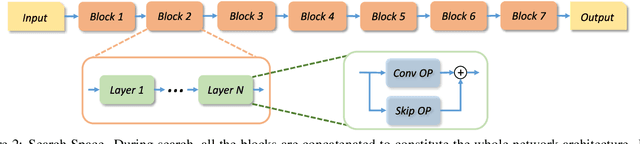
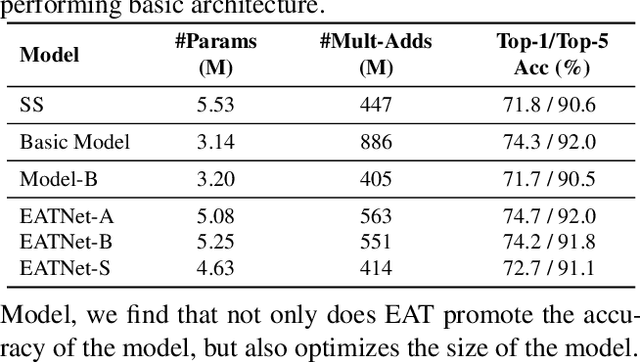
Neural architecture search (NAS) methods have been proposed to release human experts from tedious architecture engineering. However, most current methods are constrained in small-scale search due to the issue of computational resources. Meanwhile, directly applying architectures searched on small datasets to large-scale tasks often bears no performance guarantee. This limitation impedes the wide use of NAS on large-scale tasks. To overcome this obstacle, we propose an elastic architecture transfer mechanism for accelerating large-scale neural architecture search (EAT-NAS). In our implementations, architectures are first searched on a small dataset (the width and depth of architectures are taken into consideration as well), e.g., CIFAR-10, and the best is chosen as the basic architecture. Then the whole architecture is transferred with elasticity. We accelerate the search process on a large-scale dataset, e.g., the whole ImageNet dataset, with the help of the basic architecture. What we propose is not only a NAS method but a mechanism for architecture-level transfer. In our experiments, we obtain two final models EATNet-A and EATNet-B that achieve competitive accuracies, 73.8% and 73.7% on ImageNet, respectively, which also surpass the models searched from scratch on ImageNet under the same settings. For computational cost, EAT-NAS takes only less than 5 days on 8 TITAN X GPUs, which is significantly less than the computational consumption of the state-of-the-art large-scale NAS methods.
Joint Neural Architecture Search and Quantization
Nov 23, 2018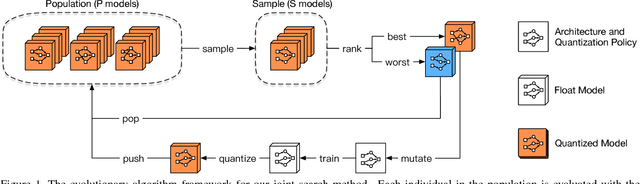
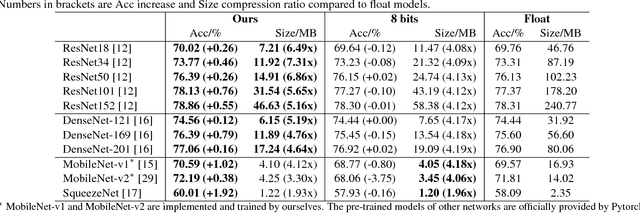
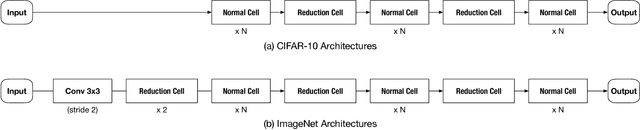
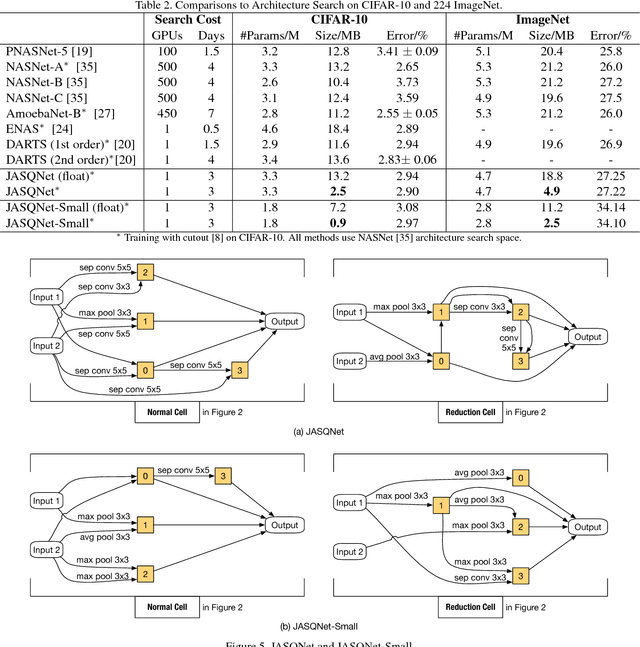
Designing neural architectures is a fundamental step in deep learning applications. As a partner technique, model compression on neural networks has been widely investigated to gear the needs that the deep learning algorithms could be run with the limited computation resources on mobile devices. Currently, both the tasks of architecture design and model compression require expertise tricks and tedious trials. In this paper, we integrate these two tasks into one unified framework, which enables the joint architecture search with quantization (compression) policies for neural networks. This method is named JASQ. Here our goal is to automatically find a compact neural network model with high performance that is suitable for mobile devices. Technically, a multi-objective evolutionary search algorithm is introduced to search the models under the balance between model size and performance accuracy. In experiments, we find that our approach outperforms the methods that search only for architectures or only for quantization policies. 1) Specifically, given existing networks, our approach can provide them with learning-based quantization policies, and outperforms their 2 bits, 4 bits, 8 bits, and 16 bits counterparts. It can yield higher accuracies than the float models, for example, over 1.02% higher accuracy on MobileNet-v1. 2) What is more, under the balance between model size and performance accuracy, two models are obtained with joint search of architectures and quantization policies: a high-accuracy model and a small model, JASQNet and JASQNet-Small that achieves 2.97% error rate with 0.9 MB on CIFAR-10.
You Only Search Once: Single Shot Neural Architecture Search via Direct Sparse Optimization
Nov 05, 2018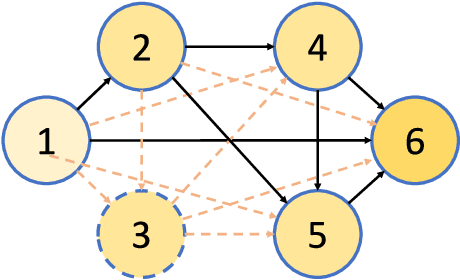
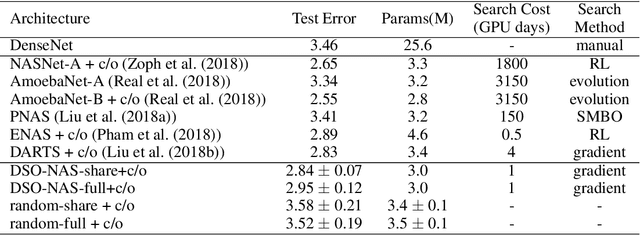
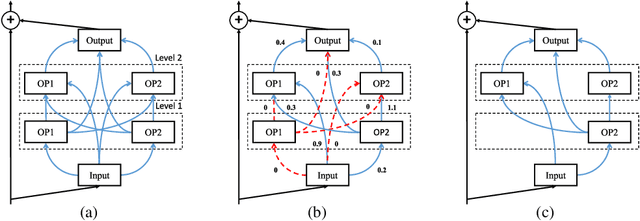
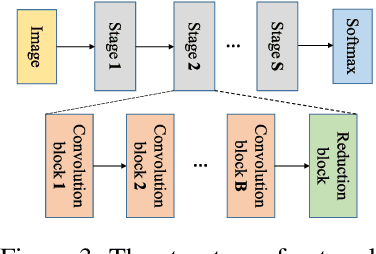
Recently Neural Architecture Search (NAS) has aroused great interest in both academia and industry, however it remains challenging because of its huge and non-continuous search space. Instead of applying evolutionary algorithm or reinforcement learning as previous works, this paper proposes a Direct Sparse Optimization NAS (DSO-NAS) method. In DSO-NAS, we provide a novel model pruning view to NAS problem. In specific, we start from a completely connected block, and then introduce scaling factors to scale the information flow between operations. Next, we impose sparse regularizations to prune useless connections in the architecture. Lastly, we derive an efficient and theoretically sound optimization method to solve it. Our method enjoys both advantages of differentiability and efficiency, therefore can be directly applied to large datasets like ImageNet. Particularly, On CIFAR-10 dataset, DSO-NAS achieves an average test error 2.84\%, while on the ImageNet dataset DSO-NAS achieves 25.4\% test error under 600M FLOPs with 8 GPUs in 18 hours.