 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Dialogue Simulation with In-Context Learning
Paper and Code
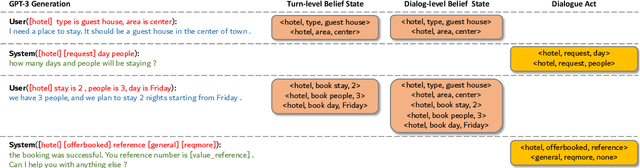
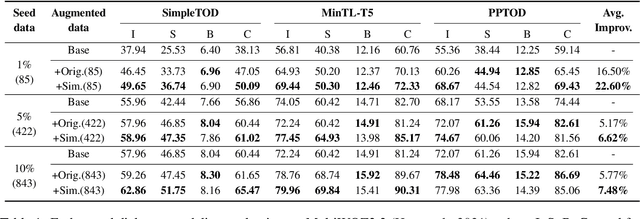

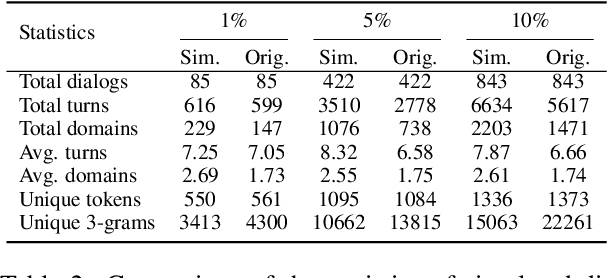
Building dialogue systems requires a large corpus of annotated dialogues. Such datasets are usually created via crowdsourcing, which is expensive and time-consuming. In this paper, we propose a novel method for dialogue simulation based on language model in-context learning, dubbed as \textsc{Dialogic}. Seeded with a few annotated dialogues, \textsc{Dialogic} automatically selects in-context examples for demonstration and prompts GPT-3 to generate new dialogues and their annotations in a controllable way. Leveraging the strong in-context learning ability of GPT-3, our method can be used to rapidly expand a small set of dialogue data without requiring \textit{human involvement} or \textit{parameter update}, and is thus much more cost-efficient and time-saving than crowdsourcing. Experimental results on the MultiWOZ dataset demonstrate that training a model on the simulated dialogues leads to even better performance than using the same amount of human-generated dialogues in the low-resource settings, with as few as 85 dialogues as the seed data. Human evaluation results also show that our simulated dialogues has high language fluency and annotation accuracy. The code and data are available at \href{https://github.com/Leezekun/dialogic}{https://github.com/Leezekun/dialogic}.