 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Driven Hardware-Software Co-Optimization of Machine Learning Pipelines
Oct 19, 2023



Researchers have long touted a vision of the future enabled by a proliferation of internet-of-things devices, including smart sensors, homes, and cities. Increasingly, embedding intelligence in such devices involves the use of deep neural networks. However, their storage and processing requirements make them prohibitive for cheap, off-the-shelf platforms. Overcoming those requirements is necessary for enabling widely-applicable smart devices. While many ways of making models smaller and more efficient have been developed, there is a lack of understanding of which ones are best suited for particular scenarios. More importantly for edge platforms, those choices cannot be analyzed in isolation from cost and user experience. In this work, we holistically explore how quantization, model scaling, and multi-modality interact with system components such as memory, sensors, and processors. We perform this hardware/software co-design from the cost, latency, and user-experience perspective, and develop a set of guidelines for optimal system design and model deployment for the most cost-constrained platforms. We demonstrate our approach using an end-to-end, on-device, biometric user authentication system using a $20 ESP-EYE board.
SWIS -- Shared Weight bIt Sparsity for Efficient Neural Network Acceleration
Mar 03, 2021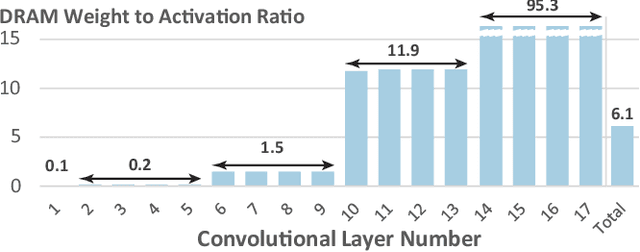

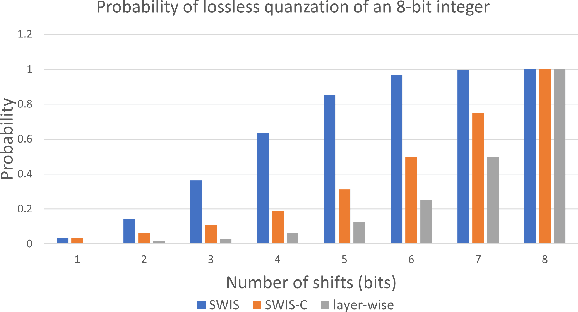
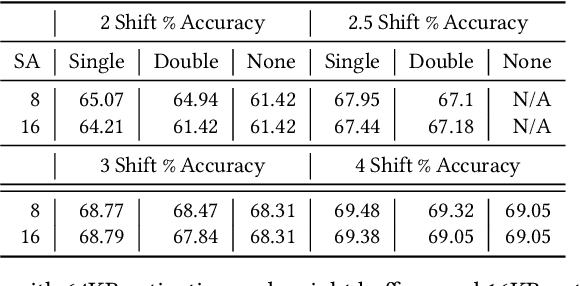
Quantization is spearheading the increase in performance and efficiency of neural network computing systems making headway into commodity hardware. We present SWIS - Shared Weight bIt Sparsity, a quantization framework for efficient neural network inference acceleration delivering improved performance and storage compression through an offline weight decomposition and scheduling algorithm. SWIS can achieve up to 54.3% (19.8%) point accuracy improvement compared to weight truncation when quantizing MobileNet-v2 to 4 (2) bits post-training (with retraining) showing the strength of leveraging shared bit-sparsity in weights. SWIS accelerator gives up to 6x speedup and 1.9x energy improvement overstate of the art bit-serial architectures.