Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWIS -- Shared Weight bIt Sparsity for Efficient Neural Network Acceleration
Mar 03, 2021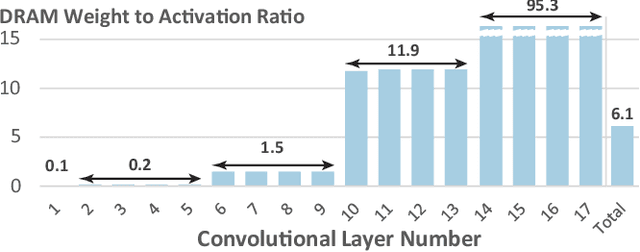

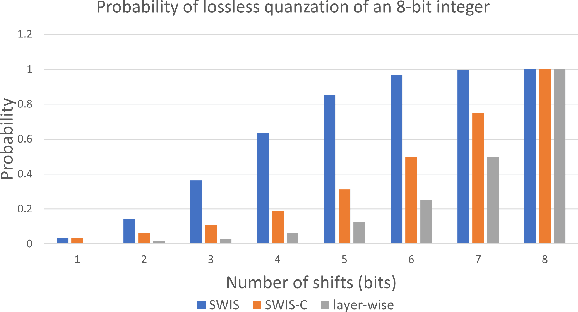
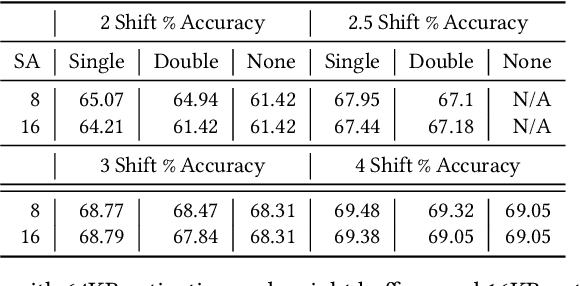
Quantization is spearheading the increase in performance and efficiency of neural network computing systems making headway into commodity hardware. We present SWIS - Shared Weight bIt Sparsity, a quantization framework for efficient neural network inference acceleration delivering improved performance and storage compression through an offline weight decomposition and scheduling algorithm. SWIS can achieve up to 54.3% (19.8%) point accuracy improvement compared to weight truncation when quantizing MobileNet-v2 to 4 (2) bits post-training (with retraining) showing the strength of leveraging shared bit-sparsity in weights. SWIS accelerator gives up to 6x speedup and 1.9x energy improvement overstate of the art bit-serial architectures.
* 8 pages, 6 figures, accepted as a full-length paper at the 2021
TinyML Research Symposium
(https://openreview.net/group?id=tinyml.org/tinyML/2021/Research_Symposium)
Via