 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Learning in the Gaussian Single Index Model
May 27, 2025We consider the problem of jointly learning a one-dimensional projection and a univariate function in high-dimensional Gaussian models. Specifically, we study predictors of the form $f(x)=\varphi^\star(\langle w^\star, x \rangle)$, where both the direction $w^\star \in \mathcal{S}_{d-1}$, the sphere of $\mathbb{R}^d$, and the function $\varphi^\star: \mathbb{R} \to \mathbb{R}$ are learned from Gaussian data. This setting captures a fundamental non-convex problem at the intersection of representation learning and nonlinear regression. We analyze the gradient flow dynamics of a natural alternating scheme and prove convergence, with a rate controlled by the information exponent reflecting the \textit{Gaussian regularity} of the function $\varphi^\star$. Strikingly, our analysis shows that convergence still occurs even when the initial direction is negatively correlated with the target. On the practical side, we demonstrate that such joint learning can be effectively implemented using a Reproducing Kernel Hilbert Space (RKHS) adapted to the structure of the problem, enabling efficient and flexible estimation of the univariate function. Our results offer both theoretical insight and practical methodology for learning low-dimensional structure in high-dimensional settings.
Convergence of Shallow ReLU Networks on Weakly Interacting Data
Feb 24, 2025



We analyse the convergence of one-hidden-layer ReLU networks trained by gradient flow on $n$ data points. Our main contribution leverages the high dimensionality of the ambient space, which implies low correlation of the input samples, to demonstrate that a network with width of order $\log(n)$ neurons suffices for global convergence with high probability. Our analysis uses a Polyak-{\L}ojasiewicz viewpoint along the gradient-flow trajectory, which provides an exponential rate of convergence of $\frac{1}{n}$. When the data are exactly orthogonal, we give further refined characterizations of the convergence speed, proving its asymptotic behavior lies between the orders $\frac{1}{n}$ and $\frac{1}{\sqrt{n}}$, and exhibiting a phase-transition phenomenon in the convergence rate, during which it evolves from the lower bound to the upper, and in a relative time of order $\frac{1}{\log(n)}$.
Stochastic Differential Equations models for Least-Squares Stochastic Gradient Descent
Jul 02, 2024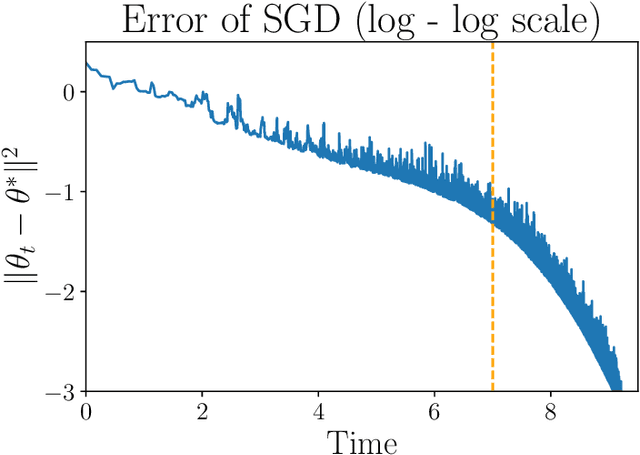
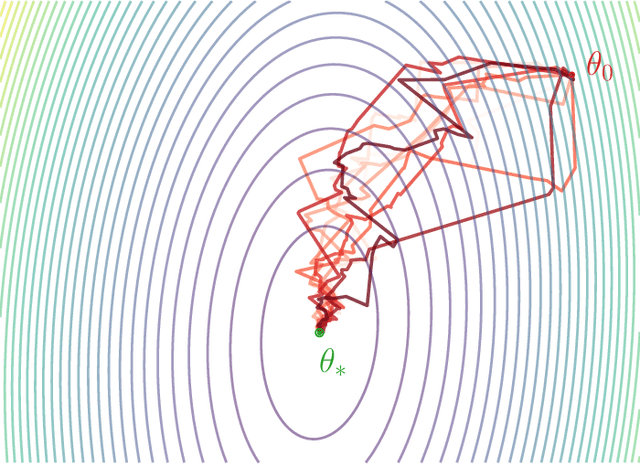

We study the dynamics of a continuous-time model of the Stochastic Gradient Descent (SGD) for the least-square problem. Indeed, pursuing the work of Li et al. (2019), we analyze Stochastic Differential Equations (SDEs) that model SGD either in the case of the training loss (finite samples) or the population one (online setting). A key qualitative feature of the dynamics is the existence of a perfect interpolator of the data, irrespective of the sample size. In both scenarios, we provide precise, non-asymptotic rates of convergence to the (possibly degenerate) stationary distribution. Additionally, we describe this asymptotic distribution, offering estimates of its mean, deviations from it, and a proof of the emergence of heavy-tails related to the step-size magnitude. Numerical simulations supporting our findings are also presented.
An Ordering of Divergences for Variational Inference with Factorized Gaussian Approximations
Mar 20, 2024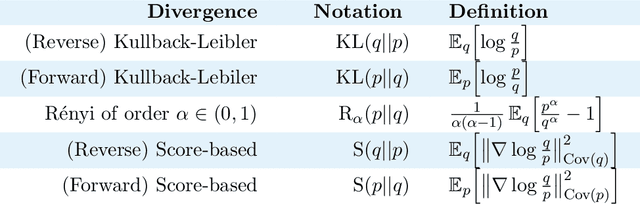


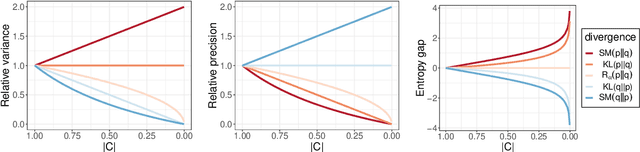
Given an intractable distribution $p$, the problem of variational inference (VI) is to compute the best approximation $q$ from some more tractable family $\mathcal{Q}$. Most commonly the approximation is found by minimizing a Kullback-Leibler (KL) divergence. However, there exist other valid choices of divergences, and when $\mathcal{Q}$ does not contain~$p$, each divergence champions a different solution. We analyze how the choice of divergence affects the outcome of VI when a Gaussian with a dense covariance matrix is approximated by a Gaussian with a diagonal covariance matrix. In this setting we show that different divergences can be \textit{ordered} by the amount that their variational approximations misestimate various measures of uncertainty, such as the variance, precision, and entropy. We also derive an impossibility theorem showing that no two of these measures can be simultaneously matched by a factorized approximation; hence, the choice of divergence informs which measure, if any, is correctly estimated. Our analysis covers the KL divergence, the R\'enyi divergences, and a score-based divergence that compares $\nabla\log p$ and $\nabla\log q$. We empirically evaluate whether these orderings hold when VI is used to approximate non-Gaussian distributions.
Computational-Statistical Gaps in Gaussian Single-Index Models
Mar 12, 2024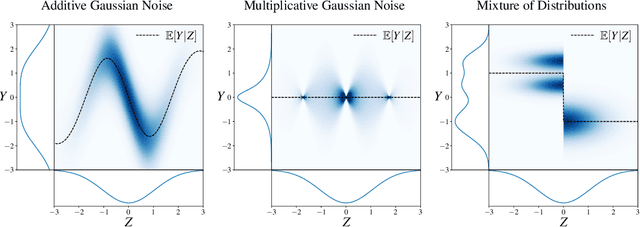
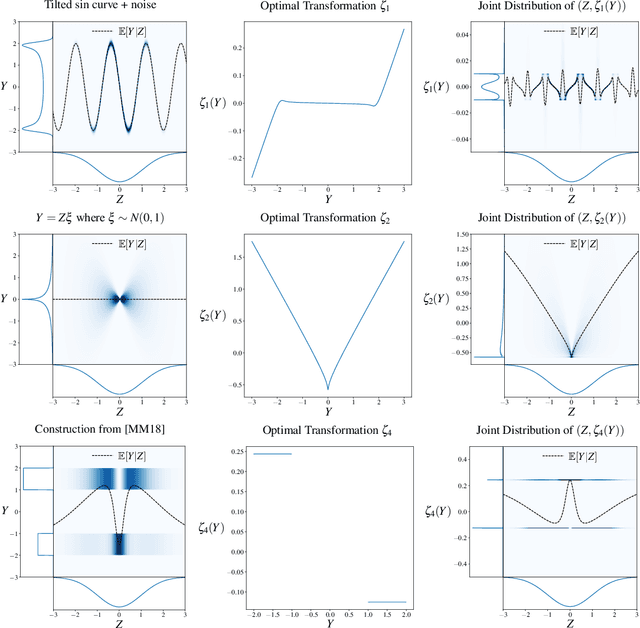
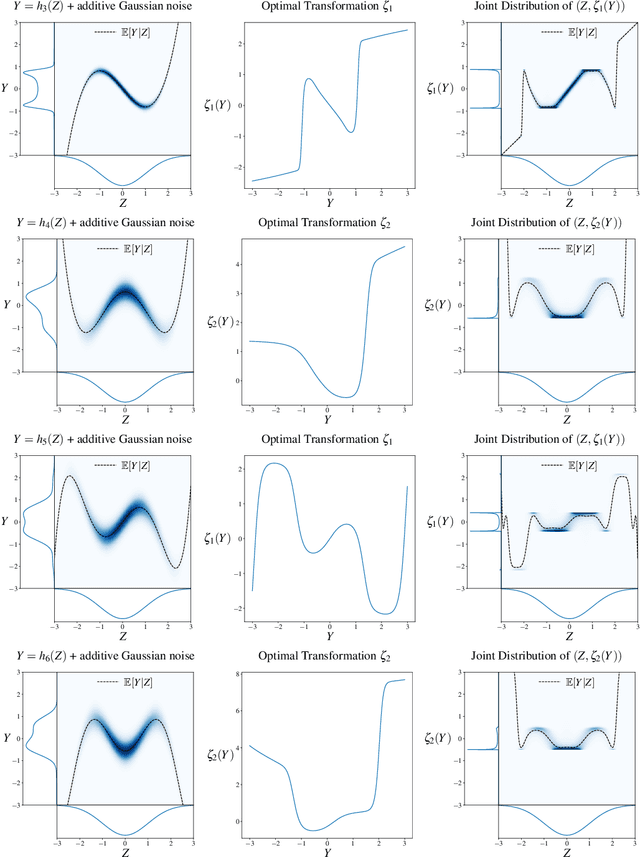
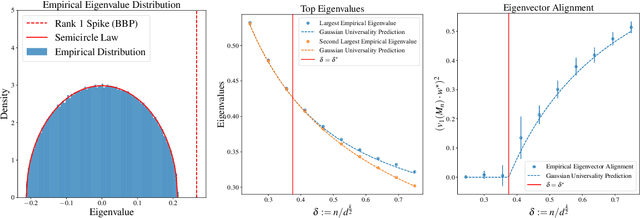
Single-Index Models are high-dimensional regression problems with planted structure, whereby labels depend on an unknown one-dimensional projection of the input via a generic, non-linear, and potentially non-deterministic transformation. As such, they encompass a broad class of statistical inference tasks, and provide a rich template to study statistical and computational trade-offs in the high-dimensional regime. While the information-theoretic sample complexity to recover the hidden direction is linear in the dimension $d$, we show that computationally efficient algorithms, both within the Statistical Query (SQ) and the Low-Degree Polynomial (LDP) framework, necessarily require $\Omega(d^{k^\star/2})$ samples, where $k^\star$ is a "generative" exponent associated with the model that we explicitly characterize. Moreover, we show that this sample complexity is also sufficient, by establishing matching upper bounds using a partial-trace algorithm. Therefore, our results provide evidence of a sharp computational-to-statistical gap (under both the SQ and LDP class) whenever $k^\star>2$. To complete the study, we provide examples of smooth and Lipschitz deterministic target functions with arbitrarily large generative exponents $k^\star$.
Batch and match: black-box variational inference with a score-based divergence
Feb 22, 2024



Most leading implementations of black-box variational inference (BBVI) are based on optimizing a stochastic evidence lower bound (ELBO). But such approaches to BBVI often converge slowly due to the high variance of their gradient estimates. In this work, we propose batch and match (BaM), an alternative approach to BBVI based on a score-based divergence. Notably, this score-based divergence can be optimized by a closed-form proximal update for Gaussian variational families with full covariance matrices. We analyze the convergence of BaM when the target distribution is Gaussian, and we prove that in the limit of infinite batch size the variational parameter updates converge exponentially quickly to the target mean and covariance. We also evaluate the performance of BaM on Gaussian and non-Gaussian target distributions that arise from posterior inference in hierarchical and deep generative models. In these experiments, we find that BaM typically converges in fewer (and sometimes significantly fewer) gradient evaluations than leading implementations of BBVI based on ELBO maximization.
On Learning Gaussian Multi-index Models with Gradient Flow
Nov 02, 2023



We study gradient flow on the multi-index regression problem for high-dimensional Gaussian data. Multi-index functions consist of a composition of an unknown low-rank linear projection and an arbitrary unknown, low-dimensional link function. As such, they constitute a natural template for feature learning in neural networks. We consider a two-timescale algorithm, whereby the low-dimensional link function is learnt with a non-parametric model infinitely faster than the subspace parametrizing the low-rank projection. By appropriately exploiting the matrix semigroup structure arising over the subspace correlation matrices, we establish global convergence of the resulting Grassmannian population gradient flow dynamics, and provide a quantitative description of its associated `saddle-to-saddle' dynamics. Notably, the timescales associated with each saddle can be explicitly characterized in terms of an appropriate Hermite decomposition of the target link function. In contrast with these positive results, we also show that the related \emph{planted} problem, where the link function is known and fixed, in fact has a rough optimization landscape, in which gradient flow dynamics might get trapped with high probability.
On Single Index Models beyond Gaussian Data
Jul 28, 2023Sparse high-dimensional functions have arisen as a rich framework to study the behavior of gradient-descent methods using shallow neural networks, showcasing their ability to perform feature learning beyond linear models. Amongst those functions, the simplest are single-index models $f(x) = \phi( x \cdot \theta^*)$, where the labels are generated by an arbitrary non-linear scalar link function $\phi$ applied to an unknown one-dimensional projection $\theta^*$ of the input data. By focusing on Gaussian data, several recent works have built a remarkable picture, where the so-called information exponent (related to the regularity of the link function) controls the required sample complexity. In essence, these tools exploit the stability and spherical symmetry of Gaussian distributions. In this work, building from the framework of \cite{arous2020online}, we explore extensions of this picture beyond the Gaussian setting, where both stability or symmetry might be violated. Focusing on the planted setting where $\phi$ is known, our main results establish that Stochastic Gradient Descent can efficiently recover the unknown direction $\theta^*$ in the high-dimensional regime, under assumptions that extend previous works ~\cite{yehudai2020learning,wu2022learning}.
Kernelized Diffusion maps
Feb 13, 2023Spectral clustering and diffusion maps are celebrated dimensionality reduction algorithms built on eigen-elements related to the diffusive structure of the data. The core of these procedures is the approximation of a Laplacian through a graph kernel approach, however this local average construction is known to be cursed by the high-dimension d. In this article, we build a different estimator of the Laplacian, via a reproducing kernel Hilbert space method, which adapts naturally to the regularity of the problem. We provide non-asymptotic statistical rates proving that the kernel estimator we build can circumvent the curse of dimensionality. Finally we discuss techniques (Nystr\"om subsampling, Fourier features) that enable to reduce the computational cost of the estimator while not degrading its overall performance.
SGD with large step sizes learns sparse features
Oct 11, 2022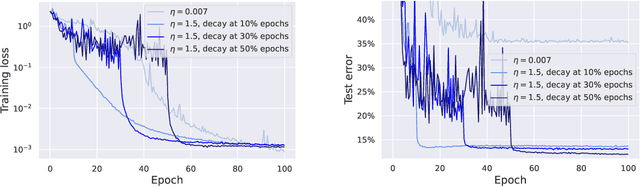

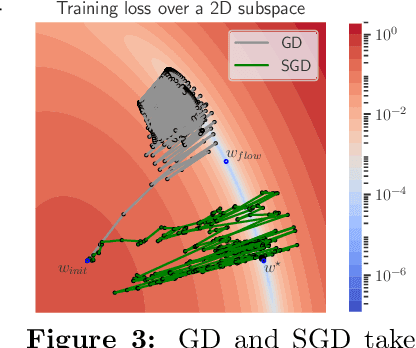

We showcase important features of the dynamics of the Stochastic Gradient Descent (SGD) in the training of neural networks. We present empirical observations that commonly used large step sizes (i) lead the iterates to jump from one side of a valley to the other causing loss stabilization, and (ii) this stabilization induces a hidden stochastic dynamics orthogonal to the bouncing directions that biases it implicitly toward simple predictors. Furthermore, we show empirically that the longer large step sizes keep SGD high in the loss landscape valleys, the better the implicit regularization can operate and find sparse representations. Notably, no explicit regularization is used so that the regularization effect comes solely from the SGD training dynamics influenced by the step size schedule. Therefore, these observations unveil how, through the step size schedules, both gradient and noise drive together the SGD dynamics through the loss landscape of neural networks. We justify these findings theoretically through the study of simple neural network models as well as qualitative arguments inspired from stochastic processes. Finally, this analysis allows to shed a new light on some common practice and observed phenomena when training neural networks. The code of our experiments is available at https://github.com/tml-epfl/sgd-sparse-features.