 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational-Statistical Gaps in Gaussian Single-Index Models
Paper and Code
Mar 12, 2024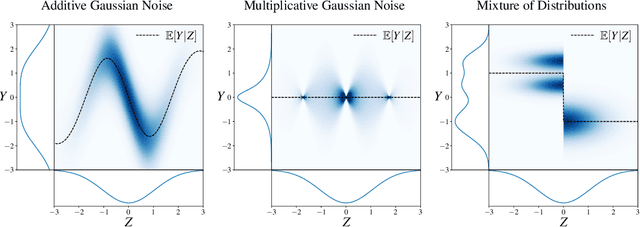
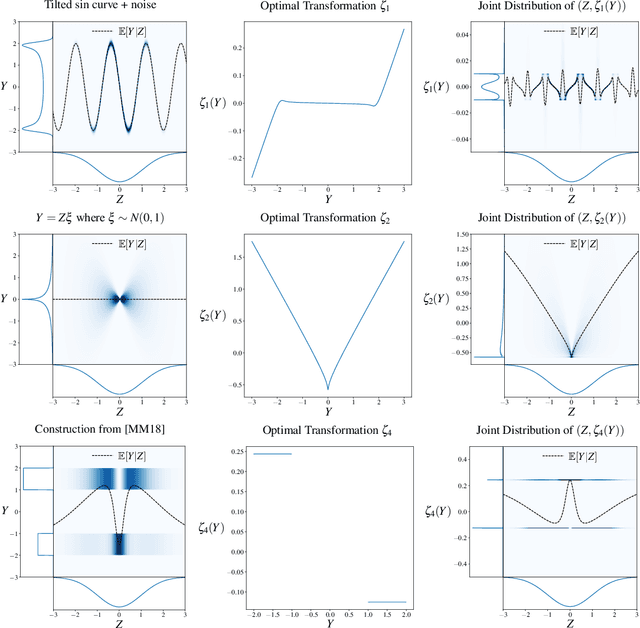
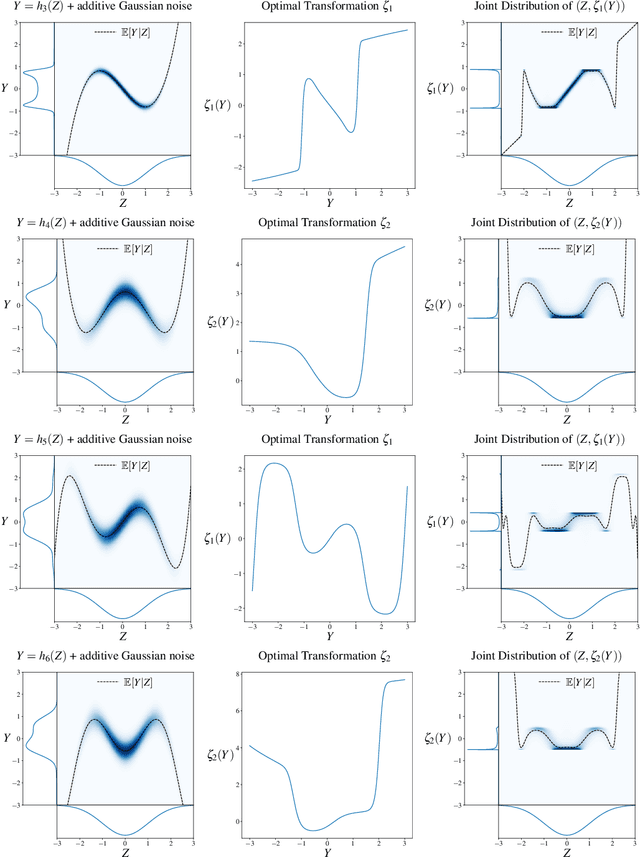
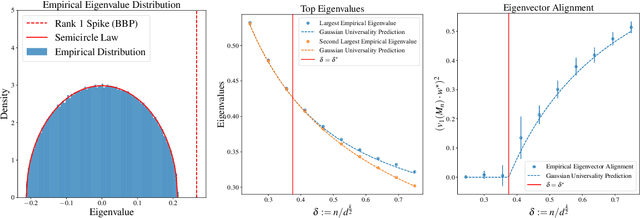
Single-Index Models are high-dimensional regression problems with planted structure, whereby labels depend on an unknown one-dimensional projection of the input via a generic, non-linear, and potentially non-deterministic transformation. As such, they encompass a broad class of statistical inference tasks, and provide a rich template to study statistical and computational trade-offs in the high-dimensional regime. While the information-theoretic sample complexity to recover the hidden direction is linear in the dimension $d$, we show that computationally efficient algorithms, both within the Statistical Query (SQ) and the Low-Degree Polynomial (LDP) framework, necessarily require $\Omega(d^{k^\star/2})$ samples, where $k^\star$ is a "generative" exponent associated with the model that we explicitly characterize. Moreover, we show that this sample complexity is also sufficient, by establishing matching upper bounds using a partial-trace algorithm. Therefore, our results provide evidence of a sharp computational-to-statistical gap (under both the SQ and LDP class) whenever $k^\star>2$. To complete the study, we provide examples of smooth and Lipschitz deterministic target functions with arbitrarily large generative exponents $k^\star$.