 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving speech recognition models with small samples for air traffic control systems
Paper and Code
Feb 16, 2021
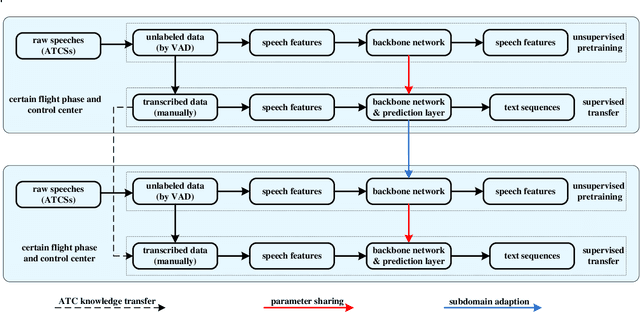
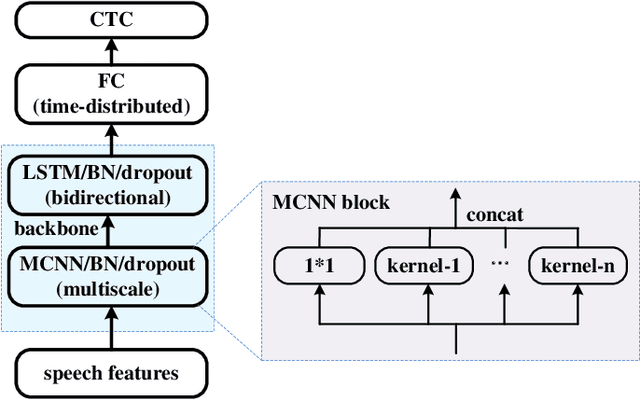
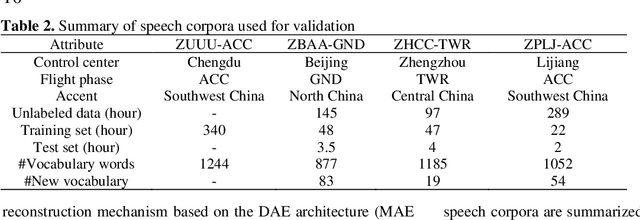
In the domain of air traffic control (ATC) systems, efforts to train a practical automatic speech recognition (ASR) model always faces the problem of small training samples since the collection and annotation of speech samples are expert- and domain-dependent task. In this work, a novel training approach based on pretraining and transfer learning is proposed to address this issue, and an improved end-to-end deep learning model is developed to address the specific challenges of ASR in the ATC domain. An unsupervised pretraining strategy is first proposed to learn speech representations from unlabeled samples for a certain dataset. Specifically, a masking strategy is applied to improve the diversity of the sample without losing their general patterns. Subsequently, transfer learning is applied to fine-tune a pretrained or other optimized baseline models to finally achieves the supervised ASR task. By virtue of the common terminology used in the ATC domain, the transfer learning task can be regarded as a sub-domain adaption task, in which the transferred model is optimized using a joint corpus consisting of baseline samples and new transcribed samples from the target dataset. This joint corpus construction strategy enriches the size and diversity of the training samples, which is important for addressing the issue of the small transcribed corpus. In addition, speed perturbation is applied to augment the new transcribed samples to further improve the quality of the speech corpus. Three real ATC datasets are used to validate the proposed ASR model and training strategies. The experimental results demonstrate that the ASR performance is significantly improved on all three datasets, with an absolute character error rate only one-third of that achieved through the supervised training. The applicability of the proposed strategies to other ASR approaches is also validated.