 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Visual Query Segmentation in the Wild
Mar 09, 2026In this paper, we introduce visual query segmentation (VQS), a new paradigm of visual query localization (VQL) that aims to segment all pixel-level occurrences of an object of interest in an untrimmed video, given an external visual query. Compared to existing VQL locating only the last appearance of a target using bounding boxes, VQS enables more comprehensive (i.e., all object occurrences) and precise (i.e., pixel-level masks) localization, making it more practical for real-world scenarios. To foster research on this task, we present VQS-4K, a large-scale benchmark dedicated to VQS. Specifically, VQS-4K contains 4,111 videos with more than 1.3 million frames and covers a diverse set of 222 object categories. Each video is paired with a visual query defined by a frame outside the search video and its target mask, and annotated with spatial-temporal masklets corresponding to the queried target. To ensure high quality, all videos in VQS-4K are manually labeled with meticulous inspection and iterative refinement. To the best of our knowledge, VQS-4K is the first benchmark specifically designed for VQS. Furthermore, to stimulate future research, we present a simple yet effective method, named VQ-SAM, which extends SAM 2 by leveraging target-specific and background distractor cues from the video to progressively evolve the memory through a novel multi-stage framework with an adaptive memory generation (AMG) module for VQS, significantly improving the performance. In our extensive experiments on VQS-4K, VQ-SAM achieves promising results and surpasses all existing approaches, demonstrating its effectiveness. With the proposed VQS-4K and VQ-SAM, we expect to go beyond the current VQL paradigm and inspire more future research and practical applications on VQS. Our benchmark, code, and results will be made publicly available.
LoReTrack: Efficient and Accurate Low-Resolution Transformer Tracking
May 27, 2024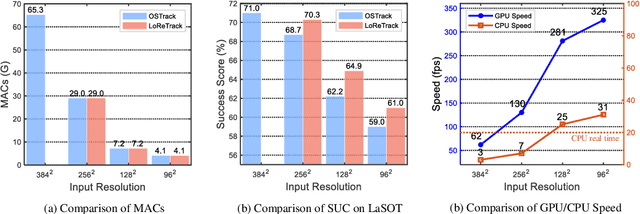
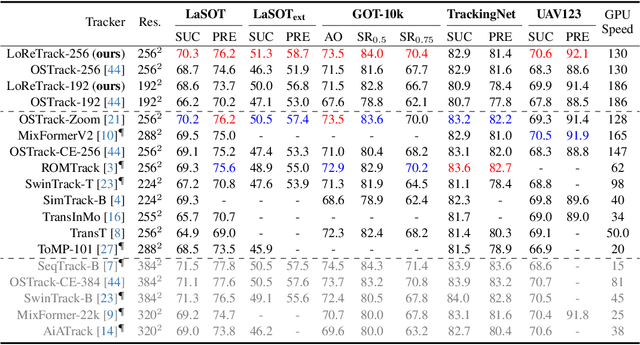
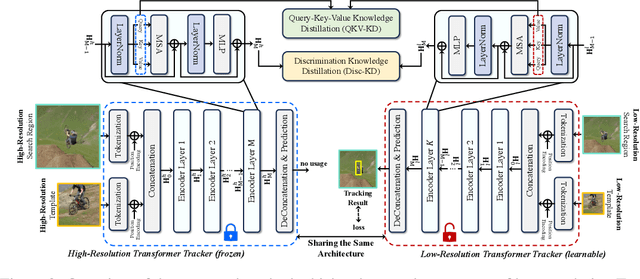
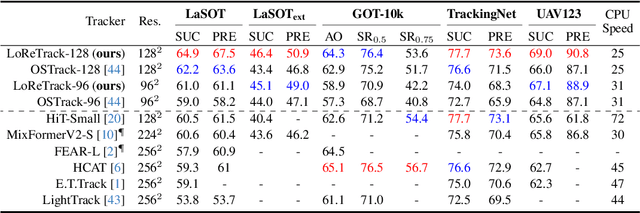
High-performance Transformer trackers have shown excellent results, yet they often bear a heavy computational load. Observing that a smaller input can immediately and conveniently reduce computations without changing the model, an easy solution is to adopt the low-resolution input for efficient Transformer tracking. Albeit faster, this hurts tracking accuracy much due to information loss in low resolution tracking. In this paper, we aim to mitigate such information loss to boost the performance of the low-resolution Transformer tracking via dual knowledge distillation from a frozen high-resolution (but not a larger) Transformer tracker. The core lies in two simple yet effective distillation modules, comprising query-key-value knowledge distillation (QKV-KD) and discrimination knowledge distillation (Disc-KD), across resolutions. The former, from the global view, allows the low-resolution tracker to inherit the features and interactions from the high-resolution tracker, while the later, from the target-aware view, enhances the target-background distinguishing capacity via imitating discriminative regions from its high-resolution counterpart. With the dual knowledge distillation, our Low-Resolution Transformer Tracker (LoReTrack) enjoys not only high efficiency owing to reduced computation but also enhanced accuracy by distilling knowledge from the high-resolution tracker. In extensive experiments, LoReTrack with a 256x256 resolution consistently improves baseline with the same resolution, and shows competitive or even better results compared to 384x384 high-resolution Transformer tracker, while running 52% faster and saving 56% MACs. Moreover, LoReTrack is resolution-scalable. With a 128x128 resolution, it runs 25 fps on a CPU with 64.9%/46.4% SUC scores on LaSOT/LaSOText, surpassing all other CPU real-time trackers. Code will be released.
Beyond MOT: Semantic Multi-Object Tracking
Mar 11, 2024Current multi-object tracking (MOT) aims to predict trajectories of targets (i.e.,"where") in videos. Yet, knowing merely "where" is insufficient in many crucial applications. In comparison, semantic understanding such as fine-grained behaviors, interactions, and overall summarized captions (i.e., "what") from videos, associated with "where", is highly-desired for comprehensive video analysis. Thus motivated, we introduce Semantic Multi-Object Tracking (SMOT), that aims to estimate object trajectories and meanwhile understand semantic details of associated trajectories including instance captions, instance interactions, and overall video captions, integrating "where" and "what" for tracking. In order to foster the exploration of SMOT, we propose BenSMOT, a large-scale Benchmark for Semantic MOT. Specifically, BenSMOT comprises 3,292 videos with 151K frames, covering various scenarios for semantic tracking of humans. BenSMOT provides annotations for the trajectories of targets, along with associated instance captions in natural language, instance interactions, and overall caption for each video sequence. To our best knowledge, BenSMOT is the first publicly available benchmark for SMOT. Besides, to encourage future research, we present a novel tracker named SMOTer, which is specially designed and end-to-end trained for SMOT, showing promising performance. By releasing BenSMOT, we expect to go beyond conventional MOT by predicting "where" and "what" for SMOT, opening up a new direction in tracking for video understanding. Our BenSMOT and SMOTer will be released.
VastTrack: Vast Category Visual Object Tracking
Mar 06, 2024In this paper, we introduce a novel benchmark, dubbed VastTrack, towards facilitating the development of more general visual tracking via encompassing abundant classes and videos. VastTrack possesses several attractive properties: (1) Vast Object Category. In particular, it covers target objects from 2,115 classes, largely surpassing object categories of existing popular benchmarks (e.g., GOT-10k with 563 classes and LaSOT with 70 categories). With such vast object classes, we expect to learn more general object tracking. (2) Larger scale. Compared with current benchmarks, VastTrack offers 50,610 sequences with 4.2 million frames, which makes it to date the largest benchmark regarding the number of videos, and thus could benefit training even more powerful visual trackers in the deep learning era. (3) Rich Annotation. Besides conventional bounding box annotations, VastTrack also provides linguistic descriptions for the videos. The rich annotations of VastTrack enables development of both the vision-only and the vision-language tracking. To ensure precise annotation, all videos are manually labeled with multiple rounds of careful inspection and refinement. To understand performance of existing trackers and to provide baselines for future comparison, we extensively assess 25 representative trackers. The results, not surprisingly, show significant drops compared to those on current datasets due to lack of abundant categories and videos from diverse scenarios for training, and more efforts are required to improve general tracking. Our VastTrack and all the evaluation results will be made publicly available https://github.com/HengLan/VastTrack.
Efficient Multimodal Semantic Segmentation via Dual-Prompt Learning
Dec 04, 2023


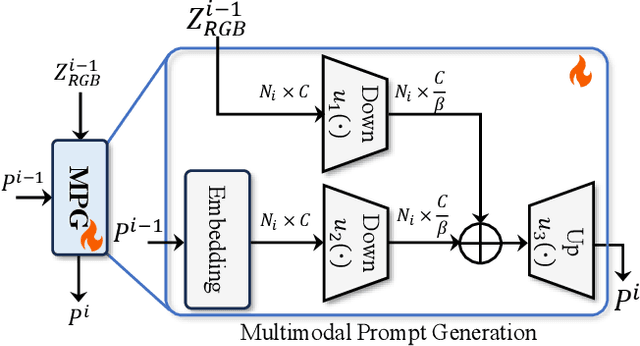
Multimodal (e.g., RGB-Depth/RGB-Thermal) fusion has shown great potential for improving semantic segmentation in complex scenes (e.g., indoor/low-light conditions). Existing approaches often fully fine-tune a dual-branch encoder-decoder framework with a complicated feature fusion strategy for achieving multimodal semantic segmentation, which is training-costly due to the massive parameter updates in feature extraction and fusion. To address this issue, we propose a surprisingly simple yet effective dual-prompt learning network (dubbed DPLNet) for training-efficient multimodal (e.g., RGB-D/T) semantic segmentation. The core of DPLNet is to directly adapt a frozen pre-trained RGB model to multimodal semantic segmentation, reducing parameter updates. For this purpose, we present two prompt learning modules, comprising multimodal prompt generator (MPG) and multimodal feature adapter (MFA). MPG works to fuse the features from different modalities in a compact manner and is inserted from shadow to deep stages to generate the multi-level multimodal prompts that are injected into the frozen backbone, while MPG adapts prompted multimodal features in the frozen backbone for better multimodal semantic segmentation. Since both the MPG and MFA are lightweight, only a few trainable parameters (3.88M, 4.4% of the pre-trained backbone parameters) are introduced for multimodal feature fusion and learning. Using a simple decoder (3.27M parameters), DPLNet achieves new state-of-the-art performance or is on a par with other complex approaches on four RGB-D/T semantic segmentation datasets while satisfying parameter efficiency. Moreover, we show that DPLNet is general and applicable to other multimodal tasks such as salient object detection and video semantic segmentation. Without special design, DPLNet outperforms many complicated models. Our code will be available at github.com/ShaohuaDong2021/DPLNet.
Edge-aware Guidance Fusion Network for RGB Thermal Scene Parsing
Dec 09, 2021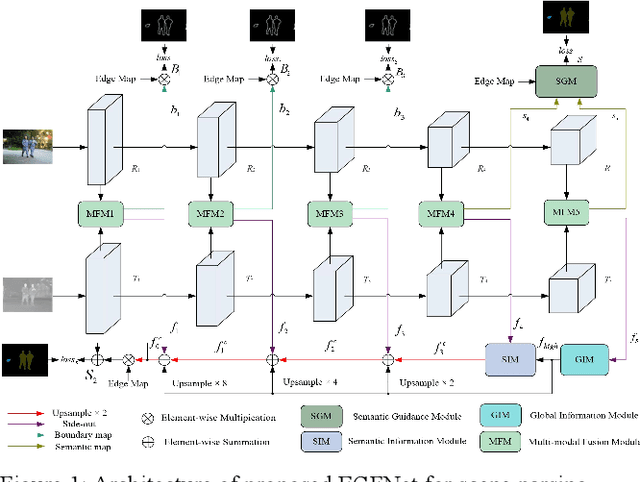
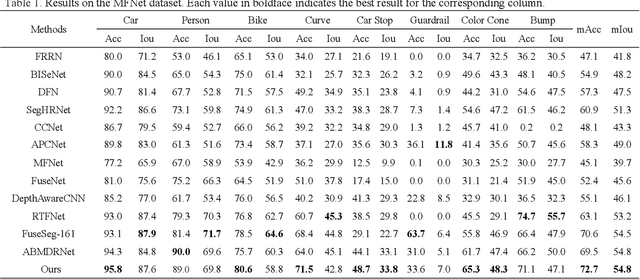
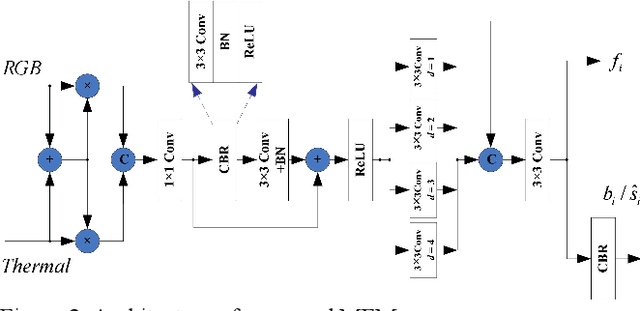
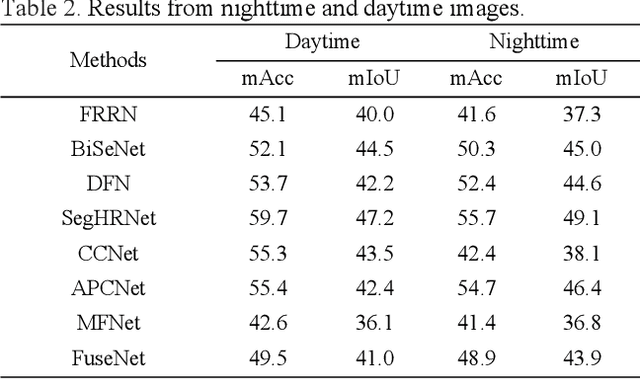
RGB thermal scene parsing has recently attracted increasing research interest in the field of computer vision. However, most existing methods fail to perform good boundary extraction for prediction maps and cannot fully use high level features. In addition, these methods simply fuse the features from RGB and thermal modalities but are unable to obtain comprehensive fused features. To address these problems, we propose an edge-aware guidance fusion network (EGFNet) for RGB thermal scene parsing. First, we introduce a prior edge map generated using the RGB and thermal images to capture detailed information in the prediction map and then embed the prior edge information in the feature maps. To effectively fuse the RGB and thermal information, we propose a multimodal fusion module that guarantees adequate cross-modal fusion. Considering the importance of high level semantic information, we propose a global information module and a semantic information module to extract rich semantic information from the high-level features. For decoding, we use simple elementwise addition for cascaded feature fusion. Finally, to improve the parsing accuracy, we apply multitask deep supervision to the semantic and boundary maps. Extensive experiments were performed on benchmark datasets to demonstrate the effectiveness of the proposed EGFNet and its superior performance compared with state of the art methods. The code and results can be found at https://github.com/ShaohuaDong2021/EGFNet.