 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multimodal Semantic Segmentation via Dual-Prompt Learning
Paper and Code



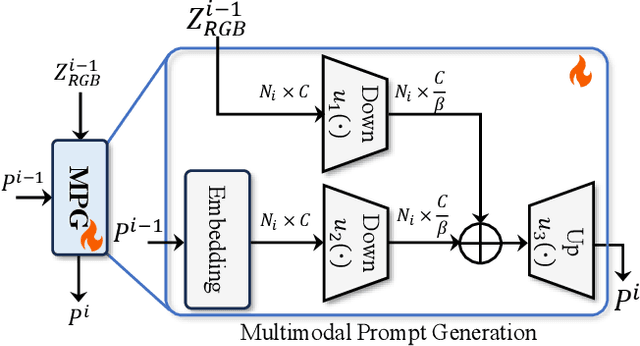
Multimodal (e.g., RGB-Depth/RGB-Thermal) fusion has shown great potential for improving semantic segmentation in complex scenes (e.g., indoor/low-light conditions). Existing approaches often fully fine-tune a dual-branch encoder-decoder framework with a complicated feature fusion strategy for achieving multimodal semantic segmentation, which is training-costly due to the massive parameter updates in feature extraction and fusion. To address this issue, we propose a surprisingly simple yet effective dual-prompt learning network (dubbed DPLNet) for training-efficient multimodal (e.g., RGB-D/T) semantic segmentation. The core of DPLNet is to directly adapt a frozen pre-trained RGB model to multimodal semantic segmentation, reducing parameter updates. For this purpose, we present two prompt learning modules, comprising multimodal prompt generator (MPG) and multimodal feature adapter (MFA). MPG works to fuse the features from different modalities in a compact manner and is inserted from shadow to deep stages to generate the multi-level multimodal prompts that are injected into the frozen backbone, while MPG adapts prompted multimodal features in the frozen backbone for better multimodal semantic segmentation. Since both the MPG and MFA are lightweight, only a few trainable parameters (3.88M, 4.4% of the pre-trained backbone parameters) are introduced for multimodal feature fusion and learning. Using a simple decoder (3.27M parameters), DPLNet achieves new state-of-the-art performance or is on a par with other complex approaches on four RGB-D/T semantic segmentation datasets while satisfying parameter efficiency. Moreover, we show that DPLNet is general and applicable to other multimodal tasks such as salient object detection and video semantic segmentation. Without special design, DPLNet outperforms many complicated models. Our code will be available at github.com/ShaohuaDong2021/DPLNet.