 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Image Inpainting with Multimodal Guided GAN Inversion
Apr 17, 2025Generative Adversarial Network (GAN) inversion have demonstrated excellent performance in image inpainting that aims to restore lost or damaged image texture using its unmasked content. Previous GAN inversion-based methods usually utilize well-trained GAN models as effective priors to generate the realistic regions for missing holes. Despite excellence, they ignore a hard constraint that the unmasked regions in the input and the output should be the same, resulting in a gap between GAN inversion and image inpainting and thus degrading the performance. Besides, existing GAN inversion approaches often consider a single modality of the input image, neglecting other auxiliary cues in images for improvements. Addressing these problems, we propose a novel GAN inversion approach, dubbed MMInvertFill, for image inpainting. MMInvertFill contains primarily a multimodal guided encoder with a pre-modulation and a GAN generator with F&W+ latent space. Specifically, the multimodal encoder aims to enhance the multi-scale structures with additional semantic segmentation edge texture modalities through a gated mask-aware attention module. Afterwards, a pre-modulation is presented to encode these structures into style vectors. To mitigate issues of conspicuous color discrepancy and semantic inconsistency, we introduce the F&W+ latent space to bridge the gap between GAN inversion and image inpainting. Furthermore, in order to reconstruct faithful and photorealistic images, we devise a simple yet effective Soft-update Mean Latent module to capture more diversified in-domain patterns for generating high-fidelity textures for massive corruptions. In our extensive experiments on six challenging datasets, we show that our MMInvertFill qualitatively and quantitatively outperforms other state-of-the-arts and it supports the completion of out-of-domain images effectively.
OmniSTVG: Toward Spatio-Temporal Omni-Object Video Grounding
Mar 13, 2025In this paper, we propose spatio-temporal omni-object video grounding, dubbed OmniSTVG, a new STVG task that aims at localizing spatially and temporally all targets mentioned in the textual query from videos. Compared to classic STVG locating only a single target, OmniSTVG enables localization of not only an arbitrary number of text-referred targets but also their interacting counterparts in the query from the video, making it more flexible and practical in real scenarios for comprehensive understanding. In order to facilitate exploration of OmniSTVG, we introduce BOSTVG, a large-scale benchmark dedicated to OmniSTVG. Specifically, our BOSTVG consists of 10,018 videos with 10.2M frames and covers a wide selection of 287 classes from diverse scenarios. Each sequence in BOSTVG, paired with a free-form textual query, encompasses a varying number of targets ranging from 1 to 10. To ensure high quality, each video is manually annotated with meticulous inspection and refinement. To our best knowledge, BOSTVG is to date the first and the largest benchmark for OmniSTVG. To encourage future research, we introduce a simple yet effective approach, named OmniTube, which, drawing inspiration from Transformer-based STVG methods, is specially designed for OmniSTVG and demonstrates promising results. By releasing BOSTVG, we hope to go beyond classic STVG by locating every object appearing in the query for more comprehensive understanding, opening up a new direction for STVG. Our benchmark, model, and results will be released at https://github.com/JellyYao3000/OmniSTVG.
Beyond MOT: Semantic Multi-Object Tracking
Mar 11, 2024Current multi-object tracking (MOT) aims to predict trajectories of targets (i.e.,"where") in videos. Yet, knowing merely "where" is insufficient in many crucial applications. In comparison, semantic understanding such as fine-grained behaviors, interactions, and overall summarized captions (i.e., "what") from videos, associated with "where", is highly-desired for comprehensive video analysis. Thus motivated, we introduce Semantic Multi-Object Tracking (SMOT), that aims to estimate object trajectories and meanwhile understand semantic details of associated trajectories including instance captions, instance interactions, and overall video captions, integrating "where" and "what" for tracking. In order to foster the exploration of SMOT, we propose BenSMOT, a large-scale Benchmark for Semantic MOT. Specifically, BenSMOT comprises 3,292 videos with 151K frames, covering various scenarios for semantic tracking of humans. BenSMOT provides annotations for the trajectories of targets, along with associated instance captions in natural language, instance interactions, and overall caption for each video sequence. To our best knowledge, BenSMOT is the first publicly available benchmark for SMOT. Besides, to encourage future research, we present a novel tracker named SMOTer, which is specially designed and end-to-end trained for SMOT, showing promising performance. By releasing BenSMOT, we expect to go beyond conventional MOT by predicting "where" and "what" for SMOT, opening up a new direction in tracking for video understanding. Our BenSMOT and SMOTer will be released.
A flexible and accurate total variation and cascaded denoisers-based image reconstruction algorithm for hyperspectrally compressed ultrafast photography
Sep 06, 2023Hyperspectrally compressed ultrafast photography (HCUP) based on compressed sensing and the time- and spectrum-to-space mappings can simultaneously realize the temporal and spectral imaging of non-repeatable or difficult-to-repeat transient events passively in a single exposure. It possesses an incredibly high frame rate of tens of trillions of frames per second and a sequence depth of several hundred, and plays a revolutionary role in single-shot ultrafast optical imaging. However, due to the ultra-high data compression ratio induced by the extremely large sequence depth as well as the limited fidelities of traditional reconstruction algorithms over the reconstruction process, HCUP suffers from a poor image reconstruction quality and fails to capture fine structures in complex transient scenes. To overcome these restrictions, we propose a flexible image reconstruction algorithm based on the total variation (TV) and cascaded denoisers (CD) for HCUP, named the TV-CD algorithm. It applies the TV denoising model cascaded with several advanced deep learning-based denoising models in the iterative plug-and-play alternating direction method of multipliers framework, which can preserve the image smoothness while utilizing the deep denoising networks to obtain more priori, and thus solving the common sparsity representation problem in local similarity and motion compensation. Both simulation and experimental results show that the proposed TV-CD algorithm can effectively improve the image reconstruction accuracy and quality of HCUP, and further promote the practical applications of HCUP in capturing high-dimensional complex physical, chemical and biological ultrafast optical scenes.
Towards Realistic Visual Dubbing with Heterogeneous Sources
Jan 17, 2022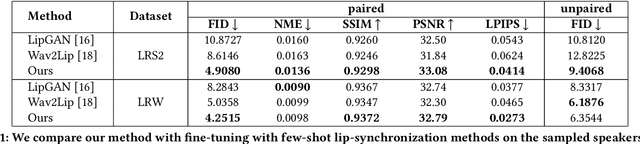
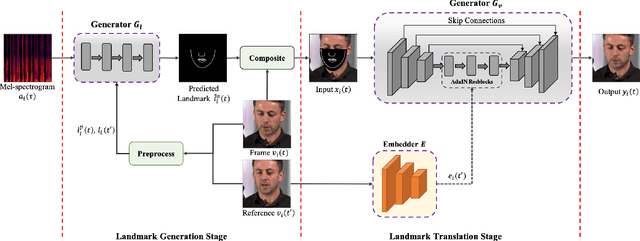
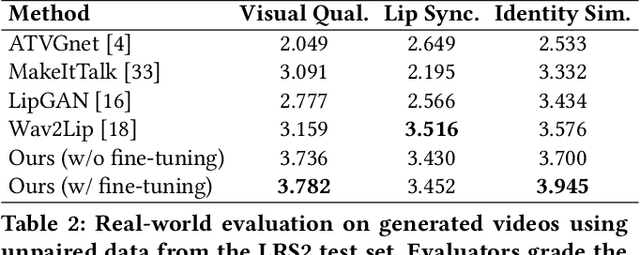
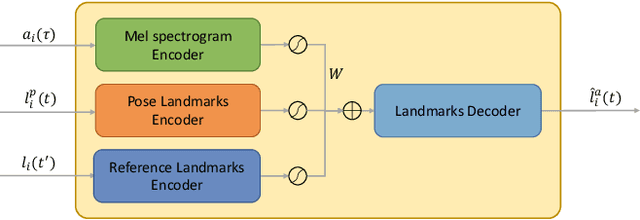
The task of few-shot visual dubbing focuses on synchronizing the lip movements with arbitrary speech input for any talking head video. Albeit moderate improvements in current approaches, they commonly require high-quality homologous data sources of videos and audios, thus causing the failure to leverage heterogeneous data sufficiently. In practice, it may be intractable to collect the perfect homologous data in some cases, for example, audio-corrupted or picture-blurry videos. To explore this kind of data and support high-fidelity few-shot visual dubbing, in this paper, we novelly propose a simple yet efficient two-stage framework with a higher flexibility of mining heterogeneous data. Specifically, our two-stage paradigm employs facial landmarks as intermediate prior of latent representations and disentangles the lip movements prediction from the core task of realistic talking head generation. By this means, our method makes it possible to independently utilize the training corpus for two-stage sub-networks using more available heterogeneous data easily acquired. Besides, thanks to the disentanglement, our framework allows a further fine-tuning for a given talking head, thereby leading to better speaker-identity preserving in the final synthesized results. Moreover, the proposed method can also transfer appearance features from others to the target speaker. Extensive experimental results demonstrate the superiority of our proposed method in generating highly realistic videos synchronized with the speech over the state-of-the-art.
Universal Phone Recognition with a Multilingual Allophone System
Feb 26, 2020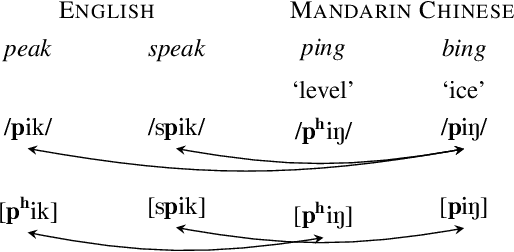

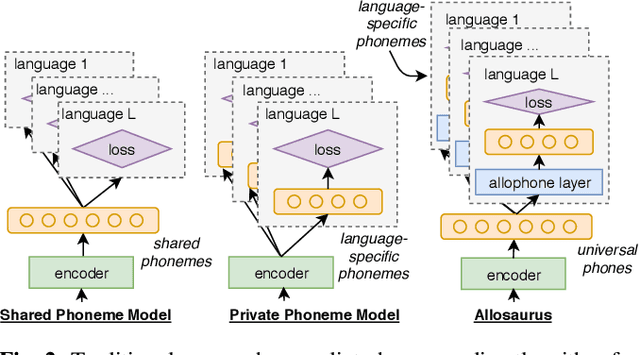

Multilingual models can improve language processing, particularly for low resource situations, by sharing parameters across languages. Multilingual acoustic models, however, generally ignore the difference between phonemes (sounds that can support lexical contrasts in a particular language) and their corresponding phones (the sounds that are actually spoken, which are language independent). This can lead to performance degradation when combining a variety of training languages, as identically annotated phonemes can actually correspond to several different underlying phonetic realizations. In this work, we propose a joint model of both language-independent phone and language-dependent phoneme distributions. In multilingual ASR experiments over 11 languages, we find that this model improves testing performance by 2% phoneme error rate absolute in low-resource conditions. Additionally, because we are explicitly modeling language-independent phones, we can build a (nearly-)universal phone recognizer that, when combined with the PHOIBLE large, manually curated database of phone inventories, can be customized into 2,000 language dependent recognizers. Experiments on two low-resourced indigenous languages, Inuktitut and Tusom, show that our recognizer achieves phone accuracy improvements of more than 17%, moving a step closer to speech recognition for all languages in the world.
Real-time Neural-based Input Method
Oct 19, 2018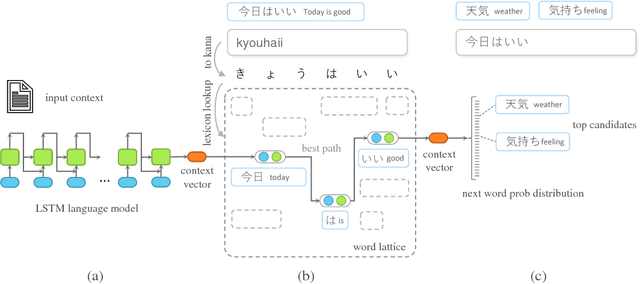
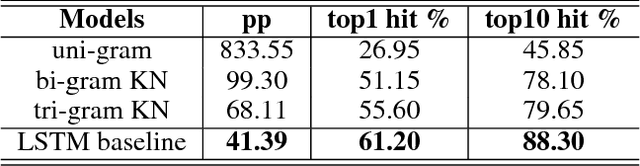
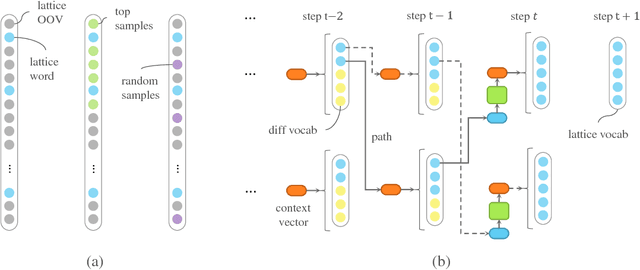
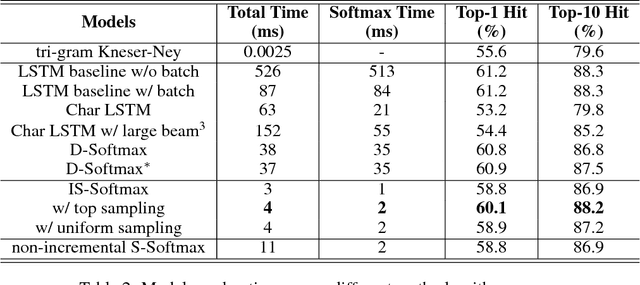
The input method is an essential service on every mobile and desktop devices that provides text suggestions. It converts sequential keyboard inputs to the characters in its target language, which is indispensable for Japanese and Chinese users. Due to critical resource constraints and limited network bandwidth of the target devices, applying neural models to input method is not well explored. In this work, we apply a LSTM-based language model to input method and evaluate its performance for both prediction and conversion tasks with Japanese BCCWJ corpus. We articulate the bottleneck to be the slow softmax computation during conversion. To solve the issue, we propose incremental softmax approximation approach, which computes softmax with a selected subset vocabulary and fix the stale probabilities when the vocabulary is updated in future steps. We refer to this method as incremental selective softmax. The results show a two order speedup for the softmax computation when converting Japanese input sequences with a large vocabulary, reaching real-time speed on commodity CPU. We also exploit the model compressing potential to achieve a 92% model size reduction without losing accuracy.