 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Realistic Visual Dubbing with Heterogeneous Sources
Paper and Code
Jan 17, 2022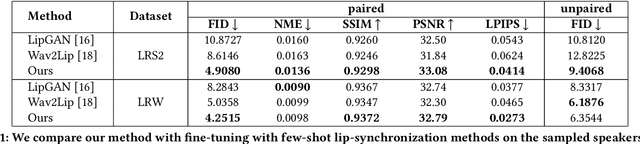
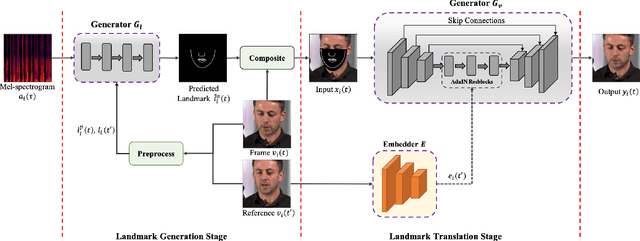
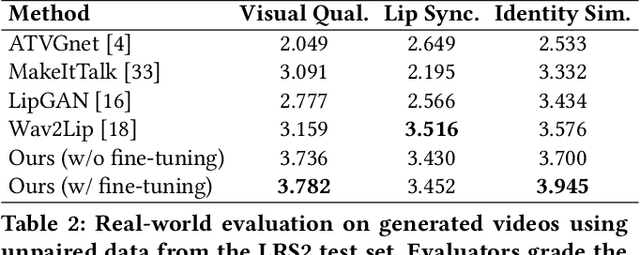
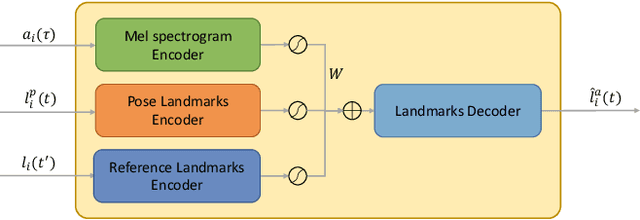
The task of few-shot visual dubbing focuses on synchronizing the lip movements with arbitrary speech input for any talking head video. Albeit moderate improvements in current approaches, they commonly require high-quality homologous data sources of videos and audios, thus causing the failure to leverage heterogeneous data sufficiently. In practice, it may be intractable to collect the perfect homologous data in some cases, for example, audio-corrupted or picture-blurry videos. To explore this kind of data and support high-fidelity few-shot visual dubbing, in this paper, we novelly propose a simple yet efficient two-stage framework with a higher flexibility of mining heterogeneous data. Specifically, our two-stage paradigm employs facial landmarks as intermediate prior of latent representations and disentangles the lip movements prediction from the core task of realistic talking head generation. By this means, our method makes it possible to independently utilize the training corpus for two-stage sub-networks using more available heterogeneous data easily acquired. Besides, thanks to the disentanglement, our framework allows a further fine-tuning for a given talking head, thereby leading to better speaker-identity preserving in the final synthesized results. Moreover, the proposed method can also transfer appearance features from others to the target speaker. Extensive experimental results demonstrate the superiority of our proposed method in generating highly realistic videos synchronized with the speech over the state-of-the-art.