 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Visual Query Segmentation in the Wild
Mar 09, 2026In this paper, we introduce visual query segmentation (VQS), a new paradigm of visual query localization (VQL) that aims to segment all pixel-level occurrences of an object of interest in an untrimmed video, given an external visual query. Compared to existing VQL locating only the last appearance of a target using bounding boxes, VQS enables more comprehensive (i.e., all object occurrences) and precise (i.e., pixel-level masks) localization, making it more practical for real-world scenarios. To foster research on this task, we present VQS-4K, a large-scale benchmark dedicated to VQS. Specifically, VQS-4K contains 4,111 videos with more than 1.3 million frames and covers a diverse set of 222 object categories. Each video is paired with a visual query defined by a frame outside the search video and its target mask, and annotated with spatial-temporal masklets corresponding to the queried target. To ensure high quality, all videos in VQS-4K are manually labeled with meticulous inspection and iterative refinement. To the best of our knowledge, VQS-4K is the first benchmark specifically designed for VQS. Furthermore, to stimulate future research, we present a simple yet effective method, named VQ-SAM, which extends SAM 2 by leveraging target-specific and background distractor cues from the video to progressively evolve the memory through a novel multi-stage framework with an adaptive memory generation (AMG) module for VQS, significantly improving the performance. In our extensive experiments on VQS-4K, VQ-SAM achieves promising results and surpasses all existing approaches, demonstrating its effectiveness. With the proposed VQS-4K and VQ-SAM, we expect to go beyond the current VQL paradigm and inspire more future research and practical applications on VQS. Our benchmark, code, and results will be made publicly available.
Towards Long-Form Spatio-Temporal Video Grounding
Feb 26, 2026In real scenarios, videos can span several minutes or even hours. However, existing research on spatio-temporal video grounding (STVG), given a textual query, mainly focuses on localizing targets in short videos of tens of seconds, typically less than one minute, which limits real-world applications. In this paper, we explore Long-Form STVG (LF-STVG), which aims to locate targets in long-term videos. Compared with short videos, long-term videos contain much longer temporal spans and more irrelevant information, making it difficult for existing STVG methods that process all frames at once. To address this challenge, we propose an AutoRegressive Transformer architecture for LF-STVG, termed ART-STVG. Unlike conventional STVG methods that require the entire video sequence to make predictions at once, ART-STVG treats the video as streaming input and processes frames sequentially, enabling efficient handling of long videos. To model spatio-temporal context, we design spatial and temporal memory banks and apply them to the decoders. Since memories from different moments are not always relevant to the current frame, we introduce simple yet effective memory selection strategies to provide more relevant information to the decoders, significantly improving performance. Furthermore, instead of parallel spatial and temporal localization, we propose a cascaded spatio-temporal design that connects the spatial decoder to the temporal decoder, allowing fine-grained spatial cues to assist complex temporal localization in long videos. Experiments on newly extended LF-STVG datasets show that ART-STVG significantly outperforms state-of-the-art methods, while achieving competitive performance on conventional short-form STVG.
Simplicity Prevails: The Emergence of Generalizable AIGI Detection in Visual Foundation Models
Feb 02, 2026While specialized detectors for AI-Generated Images (AIGI) achieve near-perfect accuracy on curated benchmarks, they suffer from a dramatic performance collapse in realistic, in-the-wild scenarios. In this work, we demonstrate that simplicity prevails over complex architectural designs. A simple linear classifier trained on the frozen features of modern Vision Foundation Models , including Perception Encoder, MetaCLIP 2, and DINOv3, establishes a new state-of-the-art. Through a comprehensive evaluation spanning traditional benchmarks, unseen generators, and challenging in-the-wild distributions, we show that this baseline not only matches specialized detectors on standard benchmarks but also decisively outperforms them on in-the-wild datasets, boosting accuracy by striking margins of over 30\%. We posit that this superior capability is an emergent property driven by the massive scale of pre-training data containing synthetic content. We trace the source of this capability to two distinct manifestations of data exposure: Vision-Language Models internalize an explicit semantic concept of forgery, while Self-Supervised Learning models implicitly acquire discriminative forensic features from the pretraining data. However, we also reveal persistent limitations: these models suffer from performance degradation under recapture and transmission, remain blind to VAE reconstruction and localized editing. We conclude by advocating for a paradigm shift in AI forensics, moving from overfitting on static benchmarks to harnessing the evolving world knowledge of foundation models for real-world reliability.
MPF-Net: Exposing High-Fidelity AI-Generated Video Forgeries via Hierarchical Manifold Deviation and Micro-Temporal Fluctuations
Jan 29, 2026With the rapid advancement of video generation models such as Veo and Wan, the visual quality of synthetic content has reached a level where macro-level semantic errors and temporal inconsistencies are no longer prominent. However, this does not imply that the distinction between real and cutting-edge high-fidelity fake is untraceable. We argue that AI-generated videos are essentially products of a manifold-fitting process rather than a physical recording. Consequently, the pixel composition logic of consecutive adjacent frames residual in AI videos exhibits a structured and homogenous characteristic. We term this phenomenon `Manifold Projection Fluctuations' (MPF). Driven by this insight, we propose a hierarchical dual-path framework that operates as a sequential filtering process. The first, the Static Manifold Deviation Branch, leverages the refined perceptual boundaries of Large-Scale Vision Foundation Models (VFMs) to capture residual spatial anomalies or physical violations that deviate from the natural real-world manifold (off-manifold). For the remaining high-fidelity videos that successfully reside on-manifold and evade spatial detection, we introduce the Micro-Temporal Fluctuation Branch as a secondary, fine-grained filter. By analyzing the structured MPF that persists even in visually perfect sequences, our framework ensures that forgeries are exposed regardless of whether they manifest as global real-world manifold deviations or subtle computational fingerprints.
Brought a Gun to a Knife Fight: Modern VFM Baselines Outgun Specialized Detectors on In-the-Wild AI Image Detection
Sep 16, 2025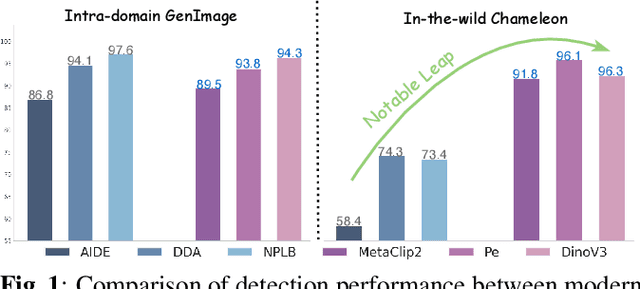
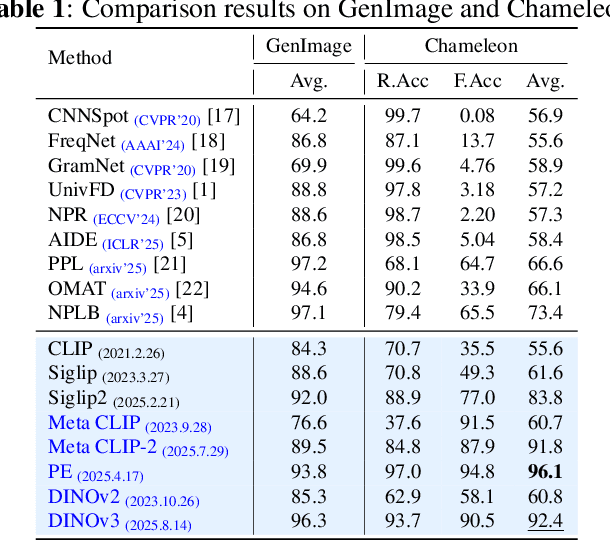
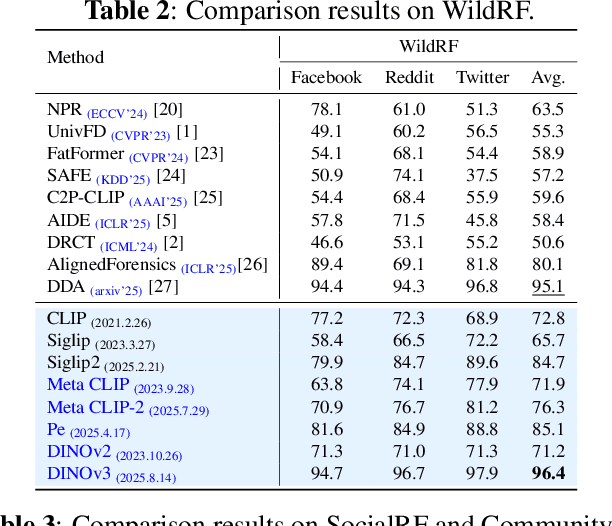
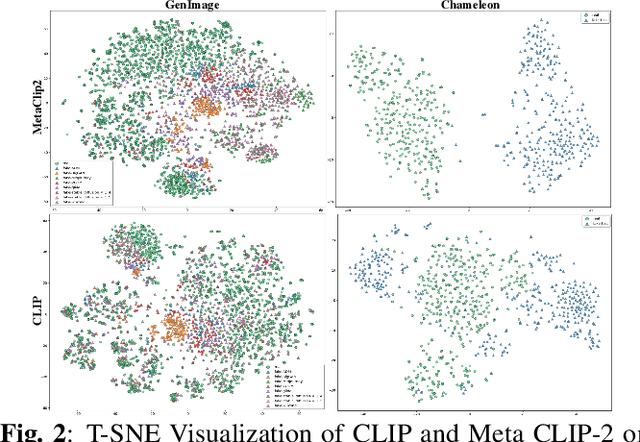
While specialized detectors for AI-generated images excel on curated benchmarks, they fail catastrophically in real-world scenarios, as evidenced by their critically high false-negative rates on `in-the-wild' benchmarks. Instead of crafting another specialized `knife' for this problem, we bring a `gun' to the fight: a simple linear classifier on a modern Vision Foundation Model (VFM). Trained on identical data, this baseline decisively `outguns' bespoke detectors, boosting in-the-wild accuracy by a striking margin of over 20\%. Our analysis pinpoints the source of the VFM's `firepower': First, by probing text-image similarities, we find that recent VLMs (e.g., Perception Encoder, Meta CLIP2) have learned to align synthetic images with forgery-related concepts (e.g., `AI-generated'), unlike previous versions. Second, we speculate that this is due to data exposure, as both this alignment and overall accuracy plummet on a novel dataset scraped after the VFM's pre-training cut-off date, ensuring it was unseen during pre-training. Our findings yield two critical conclusions: 1) For the real-world `gunfight' of AI-generated image detection, the raw `firepower' of an updated VFM is far more effective than the `craftsmanship' of a static detector. 2) True generalization evaluation requires test data to be independent of the model's entire training history, including pre-training.
OmniSTVG: Toward Spatio-Temporal Omni-Object Video Grounding
Mar 13, 2025In this paper, we propose spatio-temporal omni-object video grounding, dubbed OmniSTVG, a new STVG task that aims at localizing spatially and temporally all targets mentioned in the textual query from videos. Compared to classic STVG locating only a single target, OmniSTVG enables localization of not only an arbitrary number of text-referred targets but also their interacting counterparts in the query from the video, making it more flexible and practical in real scenarios for comprehensive understanding. In order to facilitate exploration of OmniSTVG, we introduce BOSTVG, a large-scale benchmark dedicated to OmniSTVG. Specifically, our BOSTVG consists of 10,018 videos with 10.2M frames and covers a wide selection of 287 classes from diverse scenarios. Each sequence in BOSTVG, paired with a free-form textual query, encompasses a varying number of targets ranging from 1 to 10. To ensure high quality, each video is manually annotated with meticulous inspection and refinement. To our best knowledge, BOSTVG is to date the first and the largest benchmark for OmniSTVG. To encourage future research, we introduce a simple yet effective approach, named OmniTube, which, drawing inspiration from Transformer-based STVG methods, is specially designed for OmniSTVG and demonstrates promising results. By releasing BOSTVG, we hope to go beyond classic STVG by locating every object appearing in the query for more comprehensive understanding, opening up a new direction for STVG. Our benchmark, model, and results will be released at https://github.com/JellyYao3000/OmniSTVG.
VLForgery Face Triad: Detection, Localization and Attribution via Multimodal Large Language Models
Mar 08, 2025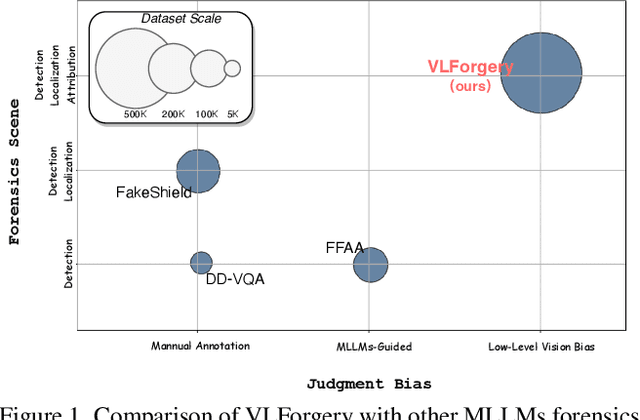

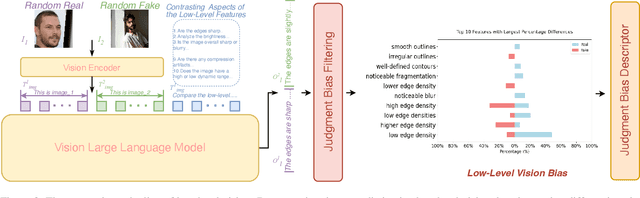

Faces synthesized by diffusion models (DMs) with high-quality and controllable attributes pose a significant challenge for Deepfake detection. Most state-of-the-art detectors only yield a binary decision, incapable of forgery localization, attribution of forgery methods, and providing analysis on the cause of forgeries. In this work, we integrate Multimodal Large Language Models (MLLMs) within DM-based face forensics, and propose a fine-grained analysis triad framework called VLForgery, that can 1) predict falsified facial images; 2) locate the falsified face regions subjected to partial synthesis; and 3) attribute the synthesis with specific generators. To achieve the above goals, we introduce VLF (Visual Language Forensics), a novel and diverse synthesis face dataset designed to facilitate rich interactions between Visual and Language modalities in MLLMs. Additionally, we propose an extrinsic knowledge-guided description method, termed EkCot, which leverages knowledge from the image generation pipeline to enable MLLMs to quickly capture image content. Furthermore, we introduce a low-level vision comparison pipeline designed to identify differential features between real and fake that MLLMs can inherently understand. These features are then incorporated into EkCot, enhancing its ability to analyze forgeries in a structured manner, following the sequence of detection, localization, and attribution. Extensive experiments demonstrate that VLForgery outperforms other state-of-the-art forensic approaches in detection accuracy, with additional potential for falsified region localization and attribution analysis.
PRVQL: Progressive Knowledge-guided Refinement for Robust Egocentric Visual Query Localization
Feb 11, 2025Egocentric visual query localization (EgoVQL) focuses on localizing the target of interest in space and time from first-person videos, given a visual query. Despite recent progressive, existing methods often struggle to handle severe object appearance changes and cluttering background in the video due to lacking sufficient target cues, leading to degradation. Addressing this, we introduce PRVQL, a novel Progressive knowledge-guided Refinement framework for EgoVQL. The core is to continuously exploit target-relevant knowledge directly from videos and utilize it as guidance to refine both query and video features for improving target localization. Our PRVQL contains multiple processing stages. The target knowledge from one stage, comprising appearance and spatial knowledge extracted via two specially designed knowledge learning modules, are utilized as guidance to refine the query and videos features for the next stage, which are used to generate more accurate knowledge for further feature refinement. With such a progressive process, target knowledge in PRVQL can be gradually improved, which, in turn, leads to better refined query and video features for localization in the final stage. Compared to previous methods, our PRVQL, besides the given object cues, enjoys additional crucial target information from a video as guidance to refine features, and hence enhances EgoVQL in complicated scenes. In our experiments on challenging Ego4D, PRVQL achieves state-of-the-art result and largely surpasses other methods, showing its efficacy. Our code, model and results will be released at https://github.com/fb-reps/PRVQL.
Synthesizing Black-box Anti-forensics DeepFakes with High Visual Quality
Dec 17, 2023DeepFake, an AI technology for creating facial forgeries, has garnered global attention. Amid such circumstances, forensics researchers focus on developing defensive algorithms to counter these threats. In contrast, there are techniques developed for enhancing the aggressiveness of DeepFake, e.g., through anti-forensics attacks, to disrupt forensic detectors. However, such attacks often sacrifice image visual quality for improved undetectability. To address this issue, we propose a method to generate novel adversarial sharpening masks for launching black-box anti-forensics attacks. Unlike many existing arts, with such perturbations injected, DeepFakes could achieve high anti-forensics performance while exhibiting pleasant sharpening visual effects. After experimental evaluations, we prove that the proposed method could successfully disrupt the state-of-the-art DeepFake detectors. Besides, compared with the images processed by existing DeepFake anti-forensics methods, the visual qualities of anti-forensics DeepFakes rendered by the proposed method are significantly refined.