 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLForgery Face Triad: Detection, Localization and Attribution via Multimodal Large Language Models
Paper and Code
Mar 08, 2025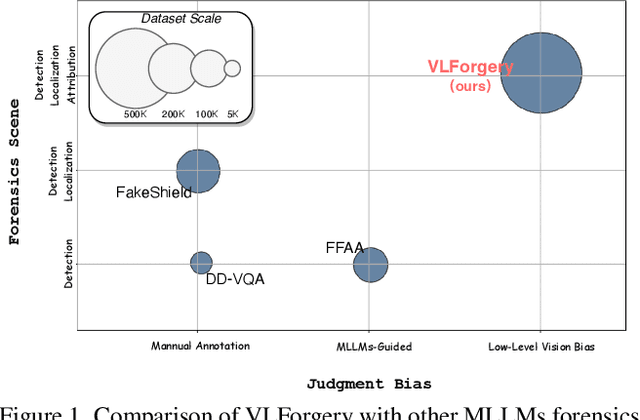

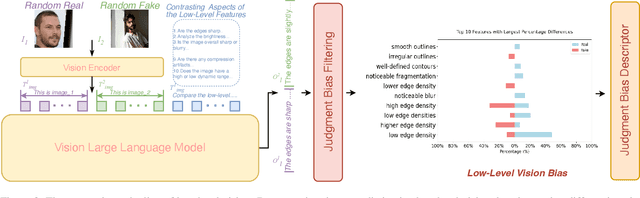

Faces synthesized by diffusion models (DMs) with high-quality and controllable attributes pose a significant challenge for Deepfake detection. Most state-of-the-art detectors only yield a binary decision, incapable of forgery localization, attribution of forgery methods, and providing analysis on the cause of forgeries. In this work, we integrate Multimodal Large Language Models (MLLMs) within DM-based face forensics, and propose a fine-grained analysis triad framework called VLForgery, that can 1) predict falsified facial images; 2) locate the falsified face regions subjected to partial synthesis; and 3) attribute the synthesis with specific generators. To achieve the above goals, we introduce VLF (Visual Language Forensics), a novel and diverse synthesis face dataset designed to facilitate rich interactions between Visual and Language modalities in MLLMs. Additionally, we propose an extrinsic knowledge-guided description method, termed EkCot, which leverages knowledge from the image generation pipeline to enable MLLMs to quickly capture image content. Furthermore, we introduce a low-level vision comparison pipeline designed to identify differential features between real and fake that MLLMs can inherently understand. These features are then incorporated into EkCot, enhancing its ability to analyze forgeries in a structured manner, following the sequence of detection, localization, and attribution. Extensive experiments demonstrate that VLForgery outperforms other state-of-the-art forensic approaches in detection accuracy, with additional potential for falsified region localization and attribution analysis.