 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceMark-LDM: Authenticatable Watermarking for Latent Diffusion Models via Binary-Guided Rearrangement
Mar 30, 2025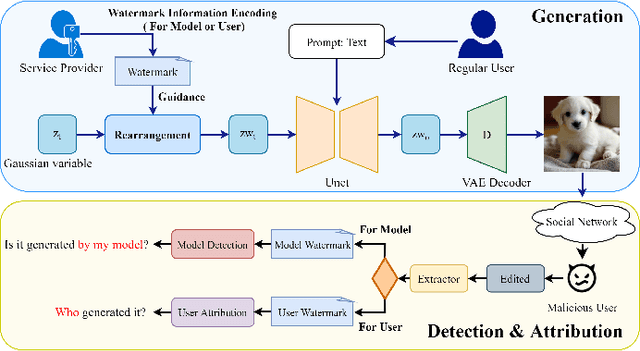
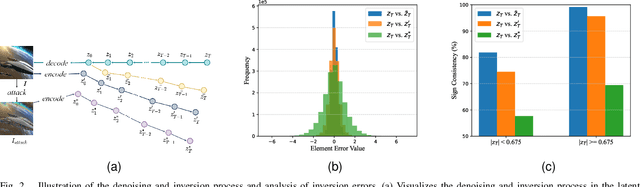
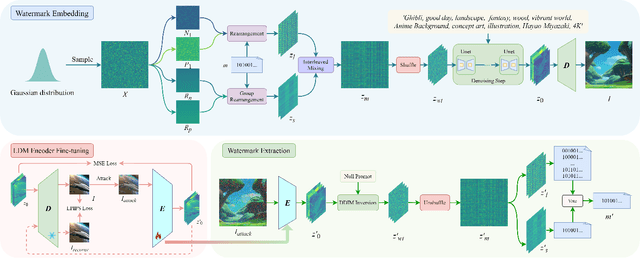
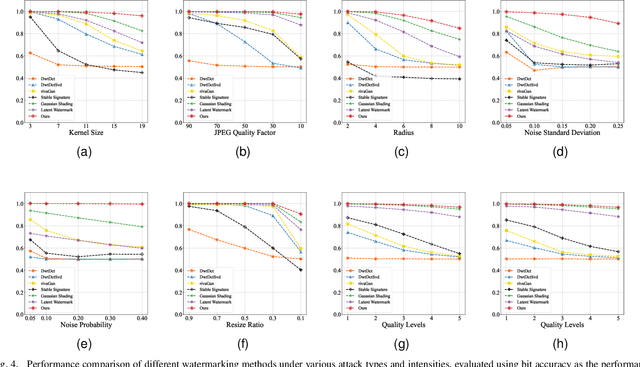
Image generation algorithms are increasingly integral to diverse aspects of human society, driven by their practical applications. However, insufficient oversight in artificial Intelligence generated content (AIGC) can facilitate the spread of malicious content and increase the risk of copyright infringement. Among the diverse range of image generation models, the Latent Diffusion Model (LDM) is currently the most widely used, dominating the majority of the Text-to-Image model market. Currently, most attribution methods for LDMs rely on directly embedding watermarks into the generated images or their intermediate noise, a practice that compromises both the quality and the robustness of the generated content. To address these limitations, we introduce TraceMark-LDM, an novel algorithm that integrates watermarking to attribute generated images while guaranteeing non-destructive performance. Unlike current methods, TraceMark-LDM leverages watermarks as guidance to rearrange random variables sampled from a Gaussian distribution. To mitigate potential deviations caused by inversion errors, the small absolute elements are grouped and rearranged. Additionally, we fine-tune the LDM encoder to enhance the robustness of the watermark. Experimental results show that images synthesized using TraceMark-LDM exhibit superior quality and attribution accuracy compared to state-of-the-art (SOTA) techniques. Notably, TraceMark-LDM demonstrates exceptional robustness against various common attack methods, consistently outperforming SOTA methods.
VLForgery Face Triad: Detection, Localization and Attribution via Multimodal Large Language Models
Mar 08, 2025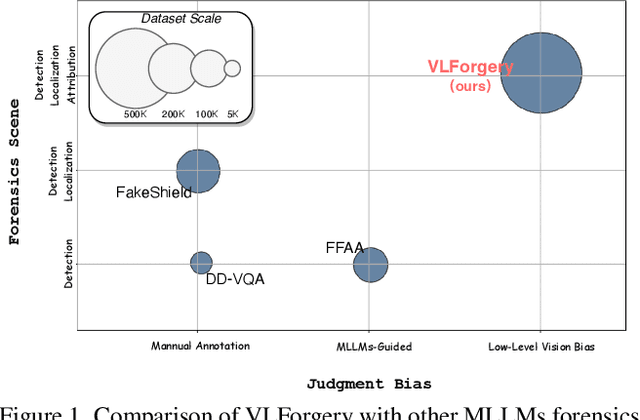

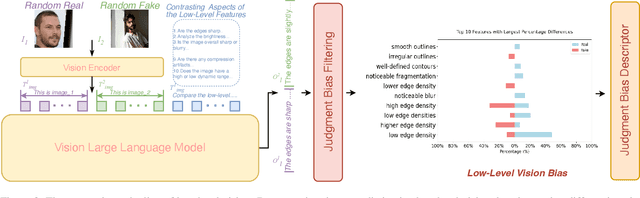

Faces synthesized by diffusion models (DMs) with high-quality and controllable attributes pose a significant challenge for Deepfake detection. Most state-of-the-art detectors only yield a binary decision, incapable of forgery localization, attribution of forgery methods, and providing analysis on the cause of forgeries. In this work, we integrate Multimodal Large Language Models (MLLMs) within DM-based face forensics, and propose a fine-grained analysis triad framework called VLForgery, that can 1) predict falsified facial images; 2) locate the falsified face regions subjected to partial synthesis; and 3) attribute the synthesis with specific generators. To achieve the above goals, we introduce VLF (Visual Language Forensics), a novel and diverse synthesis face dataset designed to facilitate rich interactions between Visual and Language modalities in MLLMs. Additionally, we propose an extrinsic knowledge-guided description method, termed EkCot, which leverages knowledge from the image generation pipeline to enable MLLMs to quickly capture image content. Furthermore, we introduce a low-level vision comparison pipeline designed to identify differential features between real and fake that MLLMs can inherently understand. These features are then incorporated into EkCot, enhancing its ability to analyze forgeries in a structured manner, following the sequence of detection, localization, and attribution. Extensive experiments demonstrate that VLForgery outperforms other state-of-the-art forensic approaches in detection accuracy, with additional potential for falsified region localization and attribution analysis.
CLIPVQA:Video Quality Assessment via CLIP
Jul 06, 2024
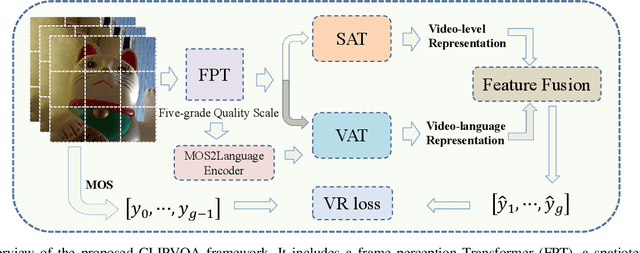
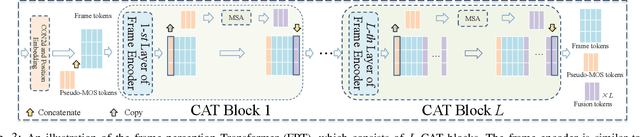
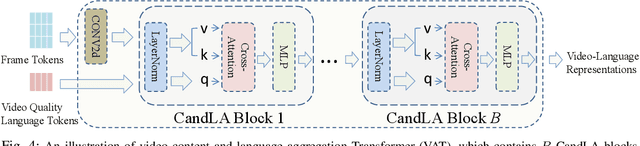
In learning vision-language representations from web-scale data, the contrastive language-image pre-training (CLIP) mechanism has demonstrated a remarkable performance in many vision tasks. However, its application to the widely studied video quality assessment (VQA) task is still an open issue. In this paper, we propose an efficient and effective CLIP-based Transformer method for the VQA problem (CLIPVQA). Specifically, we first design an effective video frame perception paradigm with the goal of extracting the rich spatiotemporal quality and content information among video frames. Then, the spatiotemporal quality features are adequately integrated together using a self-attention mechanism to yield video-level quality representation. To utilize the quality language descriptions of videos for supervision, we develop a CLIP-based encoder for language embedding, which is then fully aggregated with the generated content information via a cross-attention module for producing video-language representation. Finally, the video-level quality and video-language representations are fused together for final video quality prediction, where a vectorized regression loss is employed for efficient end-to-end optimization. Comprehensive experiments are conducted on eight in-the-wild video datasets with diverse resolutions to evaluate the performance of CLIPVQA. The experimental results show that the proposed CLIPVQA achieves new state-of-the-art VQA performance and up to 37% better generalizability than existing benchmark VQA methods. A series of ablation studies are also performed to validate the effectiveness of each module in CLIPVQA.
StarVQA+: Co-training Space-Time Attention for Video Quality Assessment
Jun 21, 2023Self-attention based Transformer has achieved great success in many computer vision tasks. However, its application to video quality assessment (VQA) has not been satisfactory so far. Evaluating the quality of in-the-wild videos is challenging due to the unknown of pristine reference and shooting distortion. This paper presents a co-trained Space-Time Attention network for the VQA problem, termed StarVQA+. Specifically, we first build StarVQA+ by alternately concatenating the divided space-time attention. Then, to facilitate the training of StarVQA+, we design a vectorized regression loss by encoding the mean opinion score (MOS) to the probability vector and embedding a special token as the learnable variable of MOS, leading to better fitting of human's rating process. Finally, to solve the data hungry problem with Transformer, we propose to co-train the spatial and temporal attention weights using both images and videos. Various experiments are conducted on the de-facto in-the-wild video datasets, including LIVE-Qualcomm, LIVE-VQC, KoNViD-1k, YouTube-UGC, LSVQ, LSVQ-1080p, and DVL2021. Experimental results demonstrate the superiority of the proposed StarVQA+ over the state-of-the-art.
Object-Attentional Untargeted Adversarial Attack
Oct 16, 2022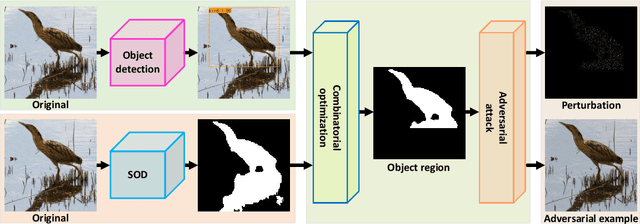


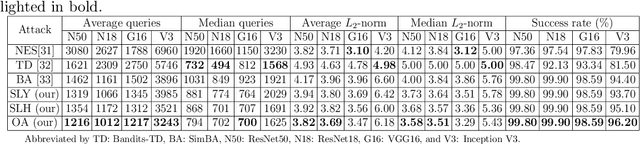
Deep neural networks are facing severe threats from adversarial attacks. Most existing black-box attacks fool target model by generating either global perturbations or local patches. However, both global perturbations and local patches easily cause annoying visual artifacts in adversarial example. Compared with some smooth regions of an image, the object region generally has more edges and a more complex texture. Thus small perturbations on it will be more imperceptible. On the other hand, the object region is undoubtfully the decisive part of an image to classification tasks. Motivated by these two facts, we propose an object-attentional adversarial attack method for untargeted attack. Specifically, we first generate an object region by intersecting the object detection region from YOLOv4 with the salient object detection (SOD) region from HVPNet. Furthermore, we design an activation strategy to avoid the reaction caused by the incomplete SOD. Then, we perform an adversarial attack only on the detected object region by leveraging Simple Black-box Adversarial Attack (SimBA). To verify the proposed method, we create a unique dataset by extracting all the images containing the object defined by COCO from ImageNet-1K, named COCO-Reduced-ImageNet in this paper. Experimental results on ImageNet-1K and COCO-Reduced-ImageNet show that under various system settings, our method yields the adversarial example with better perceptual quality meanwhile saving the query budget up to 24.16\% compared to the state-of-the-art approaches including SimBA.
StarVQA: Space-Time Attention for Video Quality Assessment
Aug 22, 2021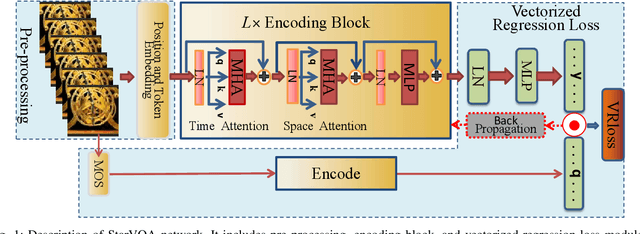
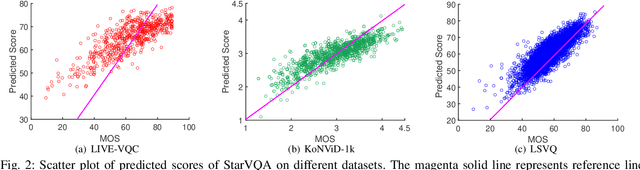
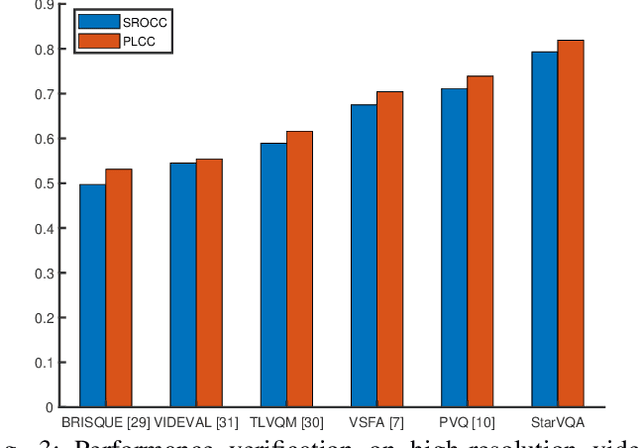
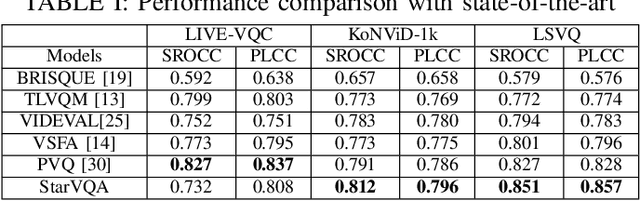
The attention mechanism is blooming in computer vision nowadays. However, its application to video quality assessment (VQA) has not been reported. Evaluating the quality of in-the-wild videos is challenging due to the unknown of pristine reference and shooting distortion. This paper presents a novel \underline{s}pace-\underline{t}ime \underline{a}ttention network fo\underline{r} the \underline{VQA} problem, named StarVQA. StarVQA builds a Transformer by alternately concatenating the divided space-time attention. To adapt the Transformer architecture for training, StarVQA designs a vectorized regression loss by encoding the mean opinion score (MOS) to the probability vector and embedding a special vectorized label token as the learnable variable. To capture the long-range spatiotemporal dependencies of a video sequence, StarVQA encodes the space-time position information of each patch to the input of the Transformer. Various experiments are conducted on the de-facto in-the-wild video datasets, including LIVE-VQC, KoNViD-1k, LSVQ, and LSVQ-1080p. Experimental results demonstrate the superiority of the proposed StarVQA over the state-of-the-art. Code and model will be available at: https://github.com/DVL/StarVQA.
Controllable List-wise Ranking for Universal No-reference Image Quality Assessment
Jan 06, 2020
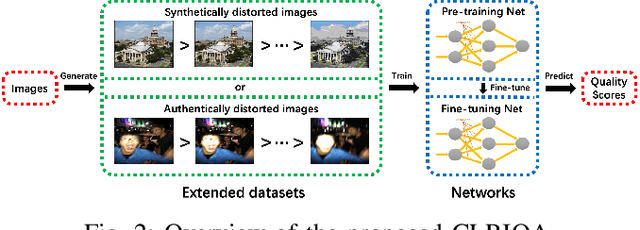

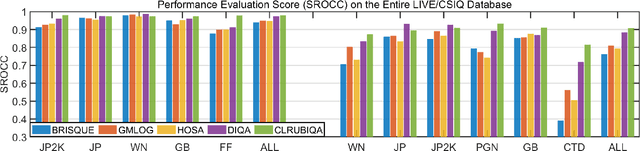
No-reference image quality assessment (NR-IQA) has received increasing attention in the IQA community since reference image is not always available. Real-world images generally suffer from various types of distortion. Unfortunately, existing NR-IQA methods do not work with all types of distortion. It is a challenging task to develop universal NR-IQA that has the ability of evaluating all types of distorted images. In this paper, we propose a universal NR-IQA method based on controllable list-wise ranking (CLRIQA). First, to extend the authentically distorted image dataset, we present an imaging-heuristic approach, in which the over-underexposure is formulated as an inverse of Weber-Fechner law, and fusion strategy and probabilistic compression are adopted, to generate the degraded real-world images. These degraded images are label-free yet associated with quality ranking information. We then design a controllable list-wise ranking function by limiting rank range and introducing an adaptive margin to tune rank interval. Finally, the extended dataset and controllable list-wise ranking function are used to pre-train a CNN. Moreover, in order to obtain an accurate prediction model, we take advantage of the original dataset to further fine-tune the pre-trained network. Experiments evaluated on four benchmark datasets (i.e. LIVE, CSIQ, TID2013, and LIVE-C) show that the proposed CLRIQA improves the state of the art by over 9% in terms of overall performance. The code and model are publicly available at https://github.com/GZHU-Image-Lab/CLRIQA.