 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Super-Resolution with Taylor Expansion Approximation and Large Field Reception
Aug 01, 2024



Self-similarity techniques are booming in blind super-resolution (SR) due to accurate estimation of the degradation types involved in low-resolution images. However, high-dimensional matrix multiplication within self-similarity computation prohibitively consumes massive computational costs. We find that the high-dimensional attention map is derived from the matrix multiplication between Query and Key, followed by a softmax function. This softmax makes the matrix multiplication between Query and Key inseparable, posing a great challenge in simplifying computational complexity. To address this issue, we first propose a second-order Taylor expansion approximation (STEA) to separate the matrix multiplication of Query and Key, resulting in the complexity reduction from $\mathcal{O}(N^2)$ to $\mathcal{O}(N)$. Then, we design a multi-scale large field reception (MLFR) to compensate for the performance degradation caused by STEA. Finally, we apply these two core designs to laboratory and real-world scenarios by constructing LabNet and RealNet, respectively. Extensive experimental results tested on five synthetic datasets demonstrate that our LabNet sets a new benchmark in qualitative and quantitative evaluations. Tested on the RealWorld38 dataset, our RealNet achieves superior visual quality over existing methods. Ablation studies further verify the contributions of STEA and MLFR towards both LabNet and RealNet frameworks.
CLIPVQA:Video Quality Assessment via CLIP
Jul 06, 2024
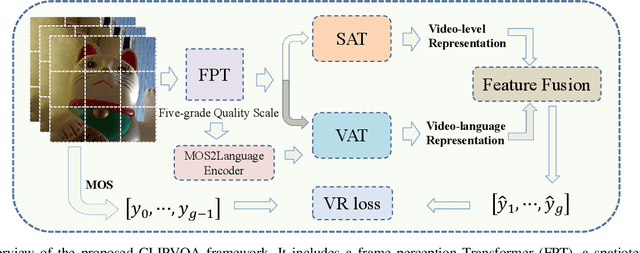
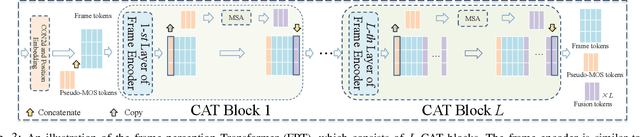
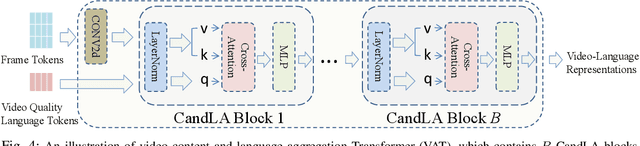
In learning vision-language representations from web-scale data, the contrastive language-image pre-training (CLIP) mechanism has demonstrated a remarkable performance in many vision tasks. However, its application to the widely studied video quality assessment (VQA) task is still an open issue. In this paper, we propose an efficient and effective CLIP-based Transformer method for the VQA problem (CLIPVQA). Specifically, we first design an effective video frame perception paradigm with the goal of extracting the rich spatiotemporal quality and content information among video frames. Then, the spatiotemporal quality features are adequately integrated together using a self-attention mechanism to yield video-level quality representation. To utilize the quality language descriptions of videos for supervision, we develop a CLIP-based encoder for language embedding, which is then fully aggregated with the generated content information via a cross-attention module for producing video-language representation. Finally, the video-level quality and video-language representations are fused together for final video quality prediction, where a vectorized regression loss is employed for efficient end-to-end optimization. Comprehensive experiments are conducted on eight in-the-wild video datasets with diverse resolutions to evaluate the performance of CLIPVQA. The experimental results show that the proposed CLIPVQA achieves new state-of-the-art VQA performance and up to 37% better generalizability than existing benchmark VQA methods. A series of ablation studies are also performed to validate the effectiveness of each module in CLIPVQA.
FRRffusion: Unveiling Authenticity with Diffusion-Based Face Retouching Reversal
May 13, 2024

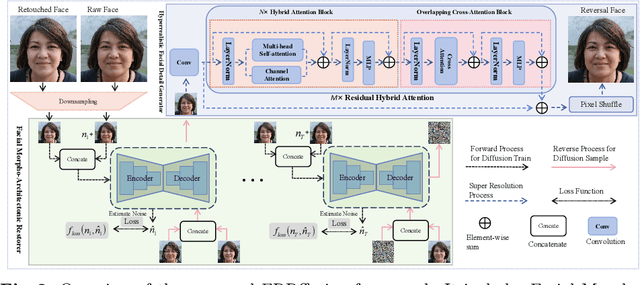

Unveiling the real appearance of retouched faces to prevent malicious users from deceptive advertising and economic fraud has been an increasing concern in the era of digital economics. This article makes the first attempt to investigate the face retouching reversal (FRR) problem. We first collect an FRR dataset, named deepFRR, which contains 50,000 StyleGAN-generated high-resolution (1024*1024) facial images and their corresponding retouched ones by a commercial online API. To our best knowledge, deepFRR is the first FRR dataset tailored for training the deep FRR models. Then, we propose a novel diffusion-based FRR approach (FRRffusion) for the FRR task. Our FRRffusion consists of a coarse-to-fine two-stage network: A diffusion-based Facial Morpho-Architectonic Restorer (FMAR) is constructed to generate the basic contours of low-resolution faces in the first stage, while a Transformer-based Hyperrealistic Facial Detail Generator (HFDG) is designed to create high-resolution facial details in the second stage. Tested on deepFRR, our FRRffusion surpasses the GP-UNIT and Stable Diffusion methods by a large margin in four widespread quantitative metrics. Especially, the de-retouched images by our FRRffusion are visually much closer to the raw face images than both the retouched face images and those restored by the GP-UNIT and Stable Diffusion methods in terms of qualitative evaluation with 85 subjects. These results sufficiently validate the efficacy of our work, bridging the recently-standing gap between the FRR and generic image restoration tasks. The dataset and code are available at https://github.com/GZHU-DVL/FRRffusion.
NLCUnet: Single-Image Super-Resolution Network with Hairline Details
Jul 22, 2023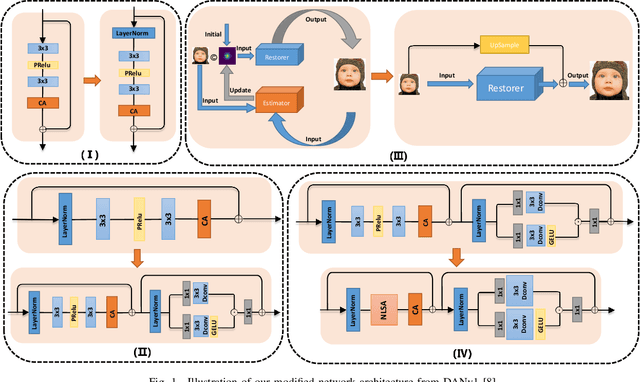
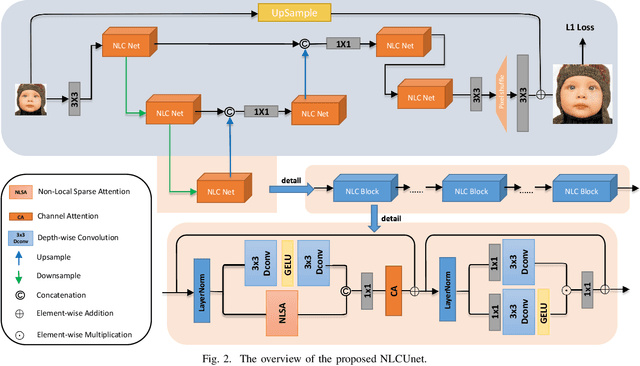


Pursuing the precise details of super-resolution images is challenging for single-image super-resolution tasks. This paper presents a single-image super-resolution network with hairline details (termed NLCUnet), including three core designs. Specifically, a non-local attention mechanism is first introduced to restore local pieces by learning from the whole image region. Then, we find that the blur kernel trained by the existing work is unnecessary. Based on this finding, we create a new network architecture by integrating depth-wise convolution with channel attention without the blur kernel estimation, resulting in a performance improvement instead. Finally, to make the cropped region contain as much semantic information as possible, we propose a random 64$\times$64 crop inside the central 512$\times$512 crop instead of a direct random crop inside the whole image of 2K size. Numerous experiments conducted on the benchmark DF2K dataset demonstrate that our NLCUnet performs better than the state-of-the-art in terms of the PSNR and SSIM metrics and yields visually favorable hairline details.
StarVQA+: Co-training Space-Time Attention for Video Quality Assessment
Jun 21, 2023Self-attention based Transformer has achieved great success in many computer vision tasks. However, its application to video quality assessment (VQA) has not been satisfactory so far. Evaluating the quality of in-the-wild videos is challenging due to the unknown of pristine reference and shooting distortion. This paper presents a co-trained Space-Time Attention network for the VQA problem, termed StarVQA+. Specifically, we first build StarVQA+ by alternately concatenating the divided space-time attention. Then, to facilitate the training of StarVQA+, we design a vectorized regression loss by encoding the mean opinion score (MOS) to the probability vector and embedding a special token as the learnable variable of MOS, leading to better fitting of human's rating process. Finally, to solve the data hungry problem with Transformer, we propose to co-train the spatial and temporal attention weights using both images and videos. Various experiments are conducted on the de-facto in-the-wild video datasets, including LIVE-Qualcomm, LIVE-VQC, KoNViD-1k, YouTube-UGC, LSVQ, LSVQ-1080p, and DVL2021. Experimental results demonstrate the superiority of the proposed StarVQA+ over the state-of-the-art.
StarVQA: Space-Time Attention for Video Quality Assessment
Aug 22, 2021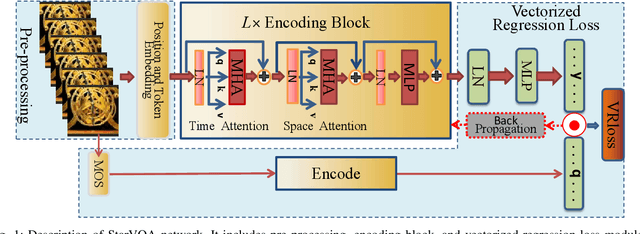
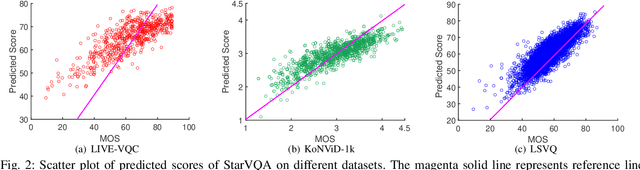
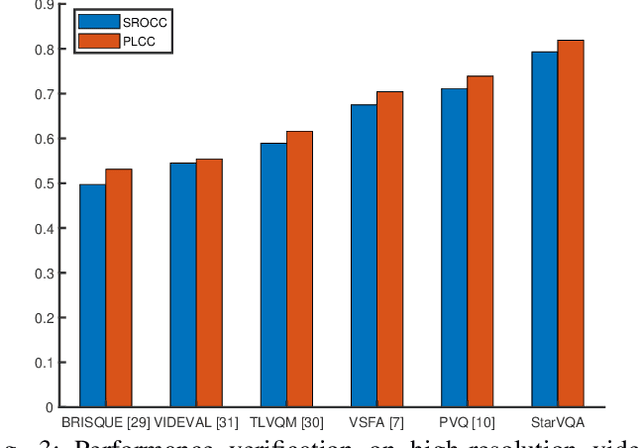
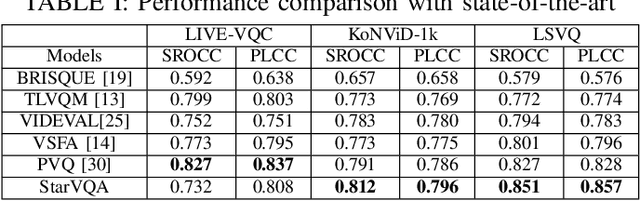
The attention mechanism is blooming in computer vision nowadays. However, its application to video quality assessment (VQA) has not been reported. Evaluating the quality of in-the-wild videos is challenging due to the unknown of pristine reference and shooting distortion. This paper presents a novel \underline{s}pace-\underline{t}ime \underline{a}ttention network fo\underline{r} the \underline{VQA} problem, named StarVQA. StarVQA builds a Transformer by alternately concatenating the divided space-time attention. To adapt the Transformer architecture for training, StarVQA designs a vectorized regression loss by encoding the mean opinion score (MOS) to the probability vector and embedding a special vectorized label token as the learnable variable. To capture the long-range spatiotemporal dependencies of a video sequence, StarVQA encodes the space-time position information of each patch to the input of the Transformer. Various experiments are conducted on the de-facto in-the-wild video datasets, including LIVE-VQC, KoNViD-1k, LSVQ, and LSVQ-1080p. Experimental results demonstrate the superiority of the proposed StarVQA over the state-of-the-art. Code and model will be available at: https://github.com/DVL/StarVQA.