 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLCUnet: Single-Image Super-Resolution Network with Hairline Details
Paper and Code
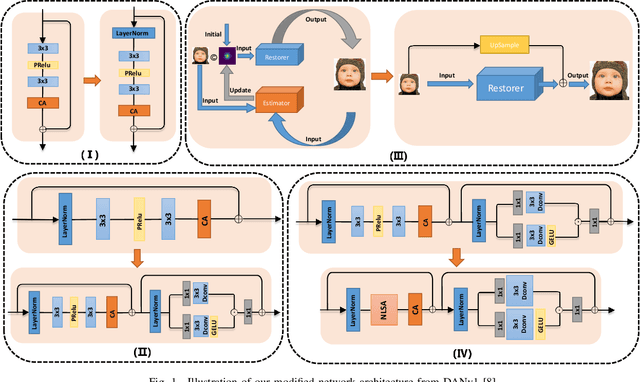
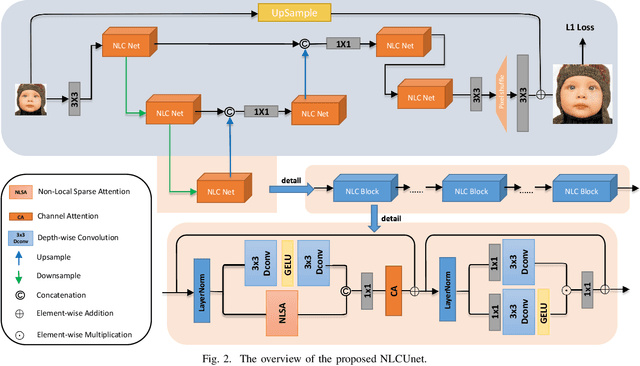


Pursuing the precise details of super-resolution images is challenging for single-image super-resolution tasks. This paper presents a single-image super-resolution network with hairline details (termed NLCUnet), including three core designs. Specifically, a non-local attention mechanism is first introduced to restore local pieces by learning from the whole image region. Then, we find that the blur kernel trained by the existing work is unnecessary. Based on this finding, we create a new network architecture by integrating depth-wise convolution with channel attention without the blur kernel estimation, resulting in a performance improvement instead. Finally, to make the cropped region contain as much semantic information as possible, we propose a random 64$\times$64 crop inside the central 512$\times$512 crop instead of a direct random crop inside the whole image of 2K size. Numerous experiments conducted on the benchmark DF2K dataset demonstrate that our NLCUnet performs better than the state-of-the-art in terms of the PSNR and SSIM metrics and yields visually favorable hairline details.