 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoration of contaminated data in an Intensity Mapping survey using deep neural networks
Jun 05, 202521-cm Intensity Mapping (IM) is a promising approach to detecting information about the large-scale structure beyond the local universe. One of the biggest challenges for an IM observation is the foreground removal procedure. In this paper, we attempt to conduct the restoration of contaminated data in an IM experiment with a Deep Neural Network (DNN). To investigate the impact of such data restoration, we compare the root-mean-square (RMS) of data with and without restoration after foreground removal using polynomial fitting, singular value decomposition, and independent component analysis, respectively. We find that the DNN-based pipeline performs well in lowering the RMS level of data, especially for data with large contaminated fractions. Furthermore, we investigate the impact of the restoration on the large-scale 21-cm signal in the simulation generated by CRIME. Simulation results show that the angular power spectrum curves from data with restoration are closer to the real one. Our work demonstrates that the DNN-based data restoration approach significantly increases the signal-to-noise ratio compared with conventional ones, achieving excellent potential for IM observations.
Secure Video Quality Assessment Resisting Adversarial Attacks
Oct 09, 2024The exponential surge in video traffic has intensified the imperative for Video Quality Assessment (VQA). Leveraging cutting-edge architectures, current VQA models have achieved human-comparable accuracy. However, recent studies have revealed the vulnerability of existing VQA models against adversarial attacks. To establish a reliable and practical assessment system, a secure VQA model capable of resisting such malicious attacks is urgently demanded. Unfortunately, no attempt has been made to explore this issue. This paper first attempts to investigate general adversarial defense principles, aiming at endowing existing VQA models with security. Specifically, we first introduce random spatial grid sampling on the video frame for intra-frame defense. Then, we design pixel-wise randomization through a guardian map, globally neutralizing adversarial perturbations. Meanwhile, we extract temporal information from the video sequence as compensation for inter-frame defense. Building upon these principles, we present a novel VQA framework from the security-oriented perspective, termed SecureVQA. Extensive experiments indicate that SecureVQA sets a new benchmark in security while achieving competitive VQA performance compared with state-of-the-art models. Ablation studies delve deeper into analyzing the principles of SecureVQA, demonstrating their generalization and contributions to the security of leading VQA models.
SemiDDM-Weather: A Semi-supervised Learning Framework for All-in-one Adverse Weather Removal
Sep 29, 2024
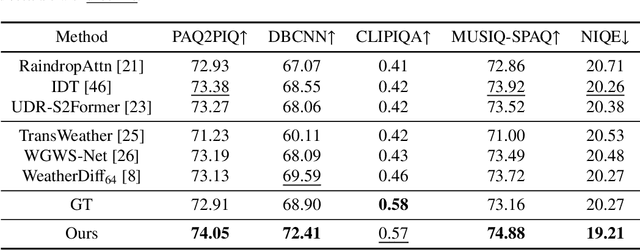
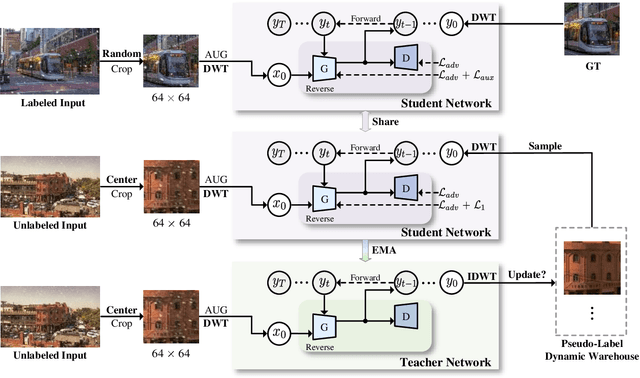
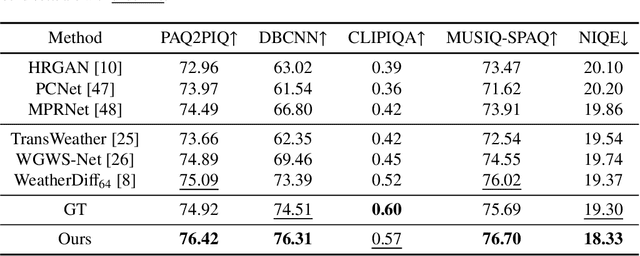
Adverse weather removal aims to restore clear vision under adverse weather conditions. Existing methods are mostly tailored for specific weather types and rely heavily on extensive labeled data. In dealing with these two limitations, this paper presents a pioneering semi-supervised all-in-one adverse weather removal framework built on the teacher-student network with a Denoising Diffusion Model (DDM) as the backbone, termed SemiDDM-Weather. As for the design of DDM backbone in our SemiDDM-Weather, we adopt the SOTA Wavelet Diffusion Model-Wavediff with customized inputs and loss functions, devoted to facilitating the learning of many-to-one mapping distributions for efficient all-in-one adverse weather removal with limited label data. To mitigate the risk of misleading model training due to potentially inaccurate pseudo-labels generated by the teacher network in semi-supervised learning, we introduce quality assessment and content consistency constraints to screen the "optimal" outputs from the teacher network as the pseudo-labels, thus more effectively guiding the student network training with unlabeled data. Experimental results show that on both synthetic and real-world datasets, our SemiDDM-Weather consistently delivers high visual quality and superior adverse weather removal, even when compared to fully supervised competitors. Our code and pre-trained model are available at this repository.
Balanced Residual Distillation Learning for 3D Point Cloud Class-Incremental Semantic Segmentation
Aug 02, 2024



Class-incremental learning (CIL) thrives due to its success in processing the influx of information by learning from continuously added new classes while preventing catastrophic forgetting about the old ones. It is essential for the performance breakthrough of CIL to effectively refine past knowledge from the base model and balance it with new learning. However, such an issue has not yet been considered in current research. In this work, we explore the potential of CIL from these perspectives and propose a novel balanced residual distillation framework (BRD-CIL) to push the performance bar of CIL to a new higher level. Specifically, BRD-CIL designs a residual distillation learning strategy, which can dynamically expand the network structure to capture the residuals between the base and target models, effectively refining the past knowledge. Furthermore, BRD-CIL designs a balanced pseudo-label learning strategy by generating a guidance mask to reduce the preference for old classes, ensuring balanced learning from new and old classes. We apply the proposed BRD-CIL to a challenging 3D point cloud semantic segmentation task where the data are unordered and unstructured. Extensive experimental results demonstrate that BRD-CIL sets a new benchmark with an outstanding balance capability in class-biased scenarios.
Image Super-Resolution with Taylor Expansion Approximation and Large Field Reception
Aug 01, 2024



Self-similarity techniques are booming in blind super-resolution (SR) due to accurate estimation of the degradation types involved in low-resolution images. However, high-dimensional matrix multiplication within self-similarity computation prohibitively consumes massive computational costs. We find that the high-dimensional attention map is derived from the matrix multiplication between Query and Key, followed by a softmax function. This softmax makes the matrix multiplication between Query and Key inseparable, posing a great challenge in simplifying computational complexity. To address this issue, we first propose a second-order Taylor expansion approximation (STEA) to separate the matrix multiplication of Query and Key, resulting in the complexity reduction from $\mathcal{O}(N^2)$ to $\mathcal{O}(N)$. Then, we design a multi-scale large field reception (MLFR) to compensate for the performance degradation caused by STEA. Finally, we apply these two core designs to laboratory and real-world scenarios by constructing LabNet and RealNet, respectively. Extensive experimental results tested on five synthetic datasets demonstrate that our LabNet sets a new benchmark in qualitative and quantitative evaluations. Tested on the RealWorld38 dataset, our RealNet achieves superior visual quality over existing methods. Ablation studies further verify the contributions of STEA and MLFR towards both LabNet and RealNet frameworks.
CLIPVQA:Video Quality Assessment via CLIP
Jul 06, 2024
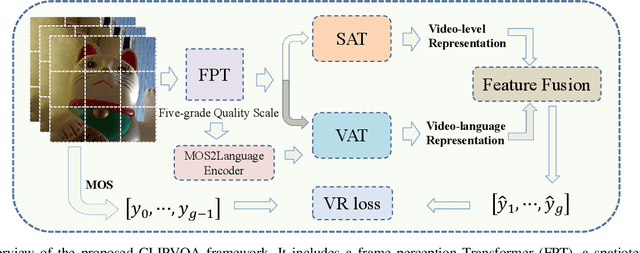
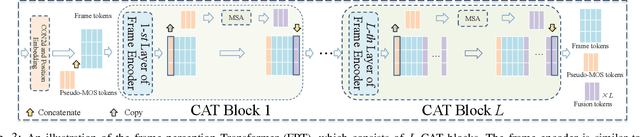
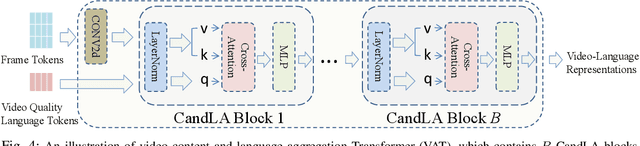
In learning vision-language representations from web-scale data, the contrastive language-image pre-training (CLIP) mechanism has demonstrated a remarkable performance in many vision tasks. However, its application to the widely studied video quality assessment (VQA) task is still an open issue. In this paper, we propose an efficient and effective CLIP-based Transformer method for the VQA problem (CLIPVQA). Specifically, we first design an effective video frame perception paradigm with the goal of extracting the rich spatiotemporal quality and content information among video frames. Then, the spatiotemporal quality features are adequately integrated together using a self-attention mechanism to yield video-level quality representation. To utilize the quality language descriptions of videos for supervision, we develop a CLIP-based encoder for language embedding, which is then fully aggregated with the generated content information via a cross-attention module for producing video-language representation. Finally, the video-level quality and video-language representations are fused together for final video quality prediction, where a vectorized regression loss is employed for efficient end-to-end optimization. Comprehensive experiments are conducted on eight in-the-wild video datasets with diverse resolutions to evaluate the performance of CLIPVQA. The experimental results show that the proposed CLIPVQA achieves new state-of-the-art VQA performance and up to 37% better generalizability than existing benchmark VQA methods. A series of ablation studies are also performed to validate the effectiveness of each module in CLIPVQA.
$L_p$-norm Distortion-Efficient Adversarial Attack
Jul 03, 2024



Adversarial examples have shown a powerful ability to make a well-trained model misclassified. Current mainstream adversarial attack methods only consider one of the distortions among $L_0$-norm, $L_2$-norm, and $L_\infty$-norm. $L_0$-norm based methods cause large modification on a single pixel, resulting in naked-eye visible detection, while $L_2$-norm and $L_\infty$-norm based methods suffer from weak robustness against adversarial defense since they always diffuse tiny perturbations to all pixels. A more realistic adversarial perturbation should be sparse and imperceptible. In this paper, we propose a novel $L_p$-norm distortion-efficient adversarial attack, which not only owns the least $L_2$-norm loss but also significantly reduces the $L_0$-norm distortion. To this aim, we design a new optimization scheme, which first optimizes an initial adversarial perturbation under $L_2$-norm constraint, and then constructs a dimension unimportance matrix for the initial perturbation. Such a dimension unimportance matrix can indicate the adversarial unimportance of each dimension of the initial perturbation. Furthermore, we introduce a new concept of adversarial threshold for the dimension unimportance matrix. The dimensions of the initial perturbation whose unimportance is higher than the threshold will be all set to zero, greatly decreasing the $L_0$-norm distortion. Experimental results on three benchmark datasets show that under the same query budget, the adversarial examples generated by our method have lower $L_0$-norm and $L_2$-norm distortion than the state-of-the-art. Especially for the MNIST dataset, our attack reduces 8.1$\%$ $L_2$-norm distortion meanwhile remaining 47$\%$ pixels unattacked. This demonstrates the superiority of the proposed method over its competitors in terms of adversarial robustness and visual imperceptibility.
FRRffusion: Unveiling Authenticity with Diffusion-Based Face Retouching Reversal
May 13, 2024

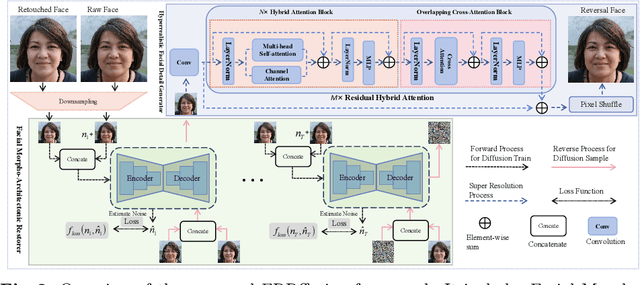

Unveiling the real appearance of retouched faces to prevent malicious users from deceptive advertising and economic fraud has been an increasing concern in the era of digital economics. This article makes the first attempt to investigate the face retouching reversal (FRR) problem. We first collect an FRR dataset, named deepFRR, which contains 50,000 StyleGAN-generated high-resolution (1024*1024) facial images and their corresponding retouched ones by a commercial online API. To our best knowledge, deepFRR is the first FRR dataset tailored for training the deep FRR models. Then, we propose a novel diffusion-based FRR approach (FRRffusion) for the FRR task. Our FRRffusion consists of a coarse-to-fine two-stage network: A diffusion-based Facial Morpho-Architectonic Restorer (FMAR) is constructed to generate the basic contours of low-resolution faces in the first stage, while a Transformer-based Hyperrealistic Facial Detail Generator (HFDG) is designed to create high-resolution facial details in the second stage. Tested on deepFRR, our FRRffusion surpasses the GP-UNIT and Stable Diffusion methods by a large margin in four widespread quantitative metrics. Especially, the de-retouched images by our FRRffusion are visually much closer to the raw face images than both the retouched face images and those restored by the GP-UNIT and Stable Diffusion methods in terms of qualitative evaluation with 85 subjects. These results sufficiently validate the efficacy of our work, bridging the recently-standing gap between the FRR and generic image restoration tasks. The dataset and code are available at https://github.com/GZHU-DVL/FRRffusion.
Adaptive Mixed-Scale Feature Fusion Network for Blind AI-Generated Image Quality Assessment
Apr 23, 2024With the increasing maturity of the text-to-image and image-to-image generative models, AI-generated images (AGIs) have shown great application potential in advertisement, entertainment, education, social media, etc. Although remarkable advancements have been achieved in generative models, very few efforts have been paid to design relevant quality assessment models. In this paper, we propose a novel blind image quality assessment (IQA) network, named AMFF-Net, for AGIs. AMFF-Net evaluates AGI quality from three dimensions, i.e., "visual quality", "authenticity", and "consistency". Specifically, inspired by the characteristics of the human visual system and motivated by the observation that "visual quality" and "authenticity" are characterized by both local and global aspects, AMFF-Net scales the image up and down and takes the scaled images and original-sized image as the inputs to obtain multi-scale features. After that, an Adaptive Feature Fusion (AFF) block is used to adaptively fuse the multi-scale features with learnable weights. In addition, considering the correlation between the image and prompt, AMFF-Net compares the semantic features from text encoder and image encoder to evaluate the text-to-image alignment. We carry out extensive experiments on three AGI quality assessment databases, and the experimental results show that our AMFF-Net obtains better performance than nine state-of-the-art blind IQA methods. The results of ablation experiments further demonstrate the effectiveness of the proposed multi-scale input strategy and AFF block.
Black-box Adversarial Attacks Against Image Quality Assessment Models
Feb 28, 2024

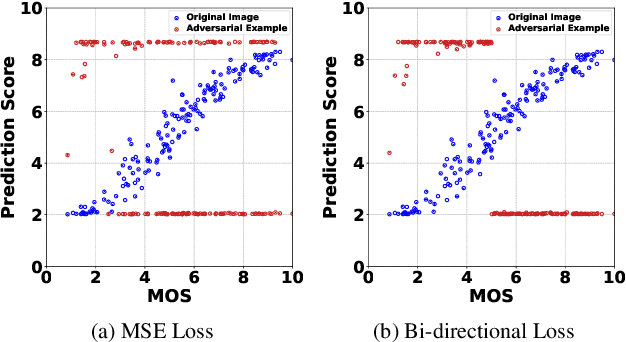
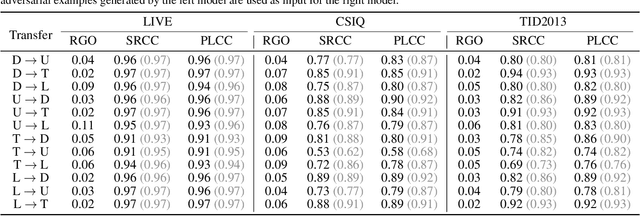
The goal of No-Reference Image Quality Assessment (NR-IQA) is to predict the perceptual quality of an image in line with its subjective evaluation. To put the NR-IQA models into practice, it is essential to study their potential loopholes for model refinement. This paper makes the first attempt to explore the black-box adversarial attacks on NR-IQA models. Specifically, we first formulate the attack problem as maximizing the deviation between the estimated quality scores of original and perturbed images, while restricting the perturbed image distortions for visual quality preservation. Under such formulation, we then design a Bi-directional loss function to mislead the estimated quality scores of adversarial examples towards an opposite direction with maximum deviation. On this basis, we finally develop an efficient and effective black-box attack method against NR-IQA models. Extensive experiments reveal that all the evaluated NR-IQA models are vulnerable to the proposed attack method. And the generated perturbations are not transferable, enabling them to serve the investigation of specialities of disparate IQA models.