 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Super-Resolution with Taylor Expansion Approximation and Large Field Reception
Aug 01, 2024



Self-similarity techniques are booming in blind super-resolution (SR) due to accurate estimation of the degradation types involved in low-resolution images. However, high-dimensional matrix multiplication within self-similarity computation prohibitively consumes massive computational costs. We find that the high-dimensional attention map is derived from the matrix multiplication between Query and Key, followed by a softmax function. This softmax makes the matrix multiplication between Query and Key inseparable, posing a great challenge in simplifying computational complexity. To address this issue, we first propose a second-order Taylor expansion approximation (STEA) to separate the matrix multiplication of Query and Key, resulting in the complexity reduction from $\mathcal{O}(N^2)$ to $\mathcal{O}(N)$. Then, we design a multi-scale large field reception (MLFR) to compensate for the performance degradation caused by STEA. Finally, we apply these two core designs to laboratory and real-world scenarios by constructing LabNet and RealNet, respectively. Extensive experimental results tested on five synthetic datasets demonstrate that our LabNet sets a new benchmark in qualitative and quantitative evaluations. Tested on the RealWorld38 dataset, our RealNet achieves superior visual quality over existing methods. Ablation studies further verify the contributions of STEA and MLFR towards both LabNet and RealNet frameworks.
NLCUnet: Single-Image Super-Resolution Network with Hairline Details
Jul 22, 2023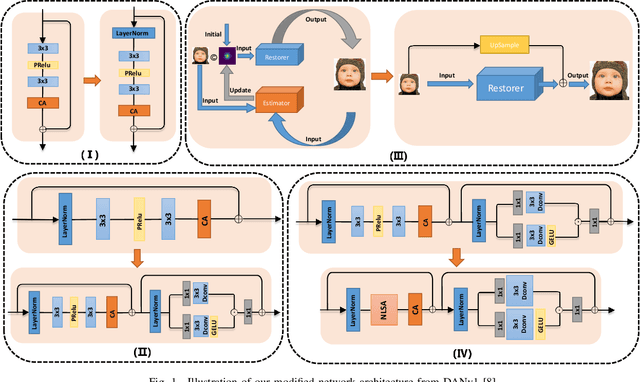
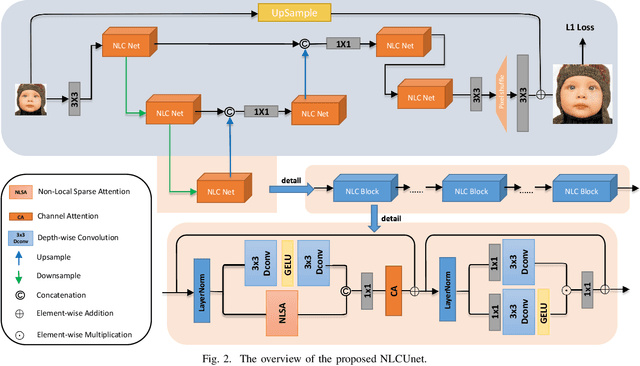


Pursuing the precise details of super-resolution images is challenging for single-image super-resolution tasks. This paper presents a single-image super-resolution network with hairline details (termed NLCUnet), including three core designs. Specifically, a non-local attention mechanism is first introduced to restore local pieces by learning from the whole image region. Then, we find that the blur kernel trained by the existing work is unnecessary. Based on this finding, we create a new network architecture by integrating depth-wise convolution with channel attention without the blur kernel estimation, resulting in a performance improvement instead. Finally, to make the cropped region contain as much semantic information as possible, we propose a random 64$\times$64 crop inside the central 512$\times$512 crop instead of a direct random crop inside the whole image of 2K size. Numerous experiments conducted on the benchmark DF2K dataset demonstrate that our NLCUnet performs better than the state-of-the-art in terms of the PSNR and SSIM metrics and yields visually favorable hairline details.