 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Video Quality Assessment Resisting Adversarial Attacks
Oct 09, 2024The exponential surge in video traffic has intensified the imperative for Video Quality Assessment (VQA). Leveraging cutting-edge architectures, current VQA models have achieved human-comparable accuracy. However, recent studies have revealed the vulnerability of existing VQA models against adversarial attacks. To establish a reliable and practical assessment system, a secure VQA model capable of resisting such malicious attacks is urgently demanded. Unfortunately, no attempt has been made to explore this issue. This paper first attempts to investigate general adversarial defense principles, aiming at endowing existing VQA models with security. Specifically, we first introduce random spatial grid sampling on the video frame for intra-frame defense. Then, we design pixel-wise randomization through a guardian map, globally neutralizing adversarial perturbations. Meanwhile, we extract temporal information from the video sequence as compensation for inter-frame defense. Building upon these principles, we present a novel VQA framework from the security-oriented perspective, termed SecureVQA. Extensive experiments indicate that SecureVQA sets a new benchmark in security while achieving competitive VQA performance compared with state-of-the-art models. Ablation studies delve deeper into analyzing the principles of SecureVQA, demonstrating their generalization and contributions to the security of leading VQA models.
FRRffusion: Unveiling Authenticity with Diffusion-Based Face Retouching Reversal
May 13, 2024

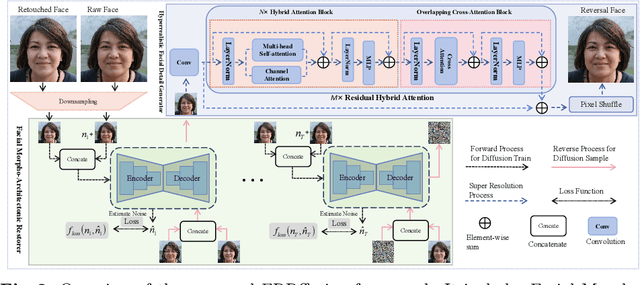

Unveiling the real appearance of retouched faces to prevent malicious users from deceptive advertising and economic fraud has been an increasing concern in the era of digital economics. This article makes the first attempt to investigate the face retouching reversal (FRR) problem. We first collect an FRR dataset, named deepFRR, which contains 50,000 StyleGAN-generated high-resolution (1024*1024) facial images and their corresponding retouched ones by a commercial online API. To our best knowledge, deepFRR is the first FRR dataset tailored for training the deep FRR models. Then, we propose a novel diffusion-based FRR approach (FRRffusion) for the FRR task. Our FRRffusion consists of a coarse-to-fine two-stage network: A diffusion-based Facial Morpho-Architectonic Restorer (FMAR) is constructed to generate the basic contours of low-resolution faces in the first stage, while a Transformer-based Hyperrealistic Facial Detail Generator (HFDG) is designed to create high-resolution facial details in the second stage. Tested on deepFRR, our FRRffusion surpasses the GP-UNIT and Stable Diffusion methods by a large margin in four widespread quantitative metrics. Especially, the de-retouched images by our FRRffusion are visually much closer to the raw face images than both the retouched face images and those restored by the GP-UNIT and Stable Diffusion methods in terms of qualitative evaluation with 85 subjects. These results sufficiently validate the efficacy of our work, bridging the recently-standing gap between the FRR and generic image restoration tasks. The dataset and code are available at https://github.com/GZHU-DVL/FRRffusion.
Generative Model-Driven Synthetic Training Image Generation: An Approach to Cognition in Rail Defect Detection
Dec 31, 2023



Recent advancements in cognitive computing, with the integration of deep learning techniques, have facilitated the development of intelligent cognitive systems (ICS). This is particularly beneficial in the context of rail defect detection, where the ICS would emulate human-like analysis of image data for defect patterns. Despite the success of Convolutional Neural Networks (CNN) in visual defect classification, the scarcity of large datasets for rail defect detection remains a challenge due to infrequent accident events that would result in defective parts and images. Contemporary researchers have addressed this data scarcity challenge by exploring rule-based and generative data augmentation models. Among these, Variational Autoencoder (VAE) models can generate realistic data without extensive baseline datasets for noise modeling. This study proposes a VAE-based synthetic image generation technique for rail defects, incorporating weight decay regularization and image reconstruction loss to prevent overfitting. The proposed method is applied to create a synthetic dataset for the Canadian Pacific Railway (CPR) with just 50 real samples across five classes. Remarkably, 500 synthetic samples are generated with a minimal reconstruction loss of 0.021. A Visual Transformer (ViT) model underwent fine-tuning using this synthetic CPR dataset, achieving high accuracy rates (98%-99%) in classifying the five defect classes. This research offers a promising solution to the data scarcity challenge in rail defect detection, showcasing the potential for robust ICS development in this domain.
A Reusable AI-Enabled Defect Detection System for Railway Using Ensembled CNN
Nov 24, 2023Accurate Defect detection is crucial for ensuring the trustworthiness of intelligent railway systems. Current approaches rely on single deep-learning models, like CNNs, which employ a large amount of data to capture underlying patterns. Training a new defect classifier with limited samples often leads to overfitting and poor performance on unseen images. To address this, researchers have advocated transfer learning and fine-tuning the pre-trained models. However, using a single backbone network in transfer learning still may cause bottleneck issues and inconsistent performance if it is not suitable for a specific problem domain. To overcome these challenges, we propose a reusable AI-enabled defect detection approach. By combining ensemble learning with transfer learning models (VGG-19, MobileNetV3, and ResNet-50), we improved the classification accuracy and achieved consistent performance at a certain phase of training. Our empirical analysis demonstrates better and more consistent performance compared to other state-of-the-art approaches. The consistency substantiates the reusability of the defect detection system for newly evolved defected rail parts. Therefore we anticipate these findings to benefit further research and development of reusable AI-enabled solutions for railway systems.
TSViT: A Time Series Vision Transformer for Fault Diagnosis
Nov 12, 2023Traditional fault diagnosis methods using Convolutional Neural Networks (CNNs) face limitations in capturing temporal features (i.e., the variation of vibration signals over time). To address this issue, this paper introduces a novel model, the Time Series Vision Transformer (TSViT), specifically designed for fault diagnosis. On one hand, TSViT model integrates a convolutional layer to segment vibration signals and capture local features. On the other hand, it employs a transformer encoder to learn long-term temporal information. The experimental results with other methods on two distinct datasets validate the effectiveness and generalizability of TSViT with a comparative analysis of its hyperparameters' impact on model performance, computational complexity, and overall parameter quantity. TSViT reaches average accuracies of 100% and 99.99% on two test sets, correspondingly.