 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASTER: Breaking the Cost-Performance Barrier in Multi-Agent Orchestration via Context-Aware Strategy for Task Efficient Routing
Jan 27, 2026Graph-based Multi-Agent Systems (MAS) enable complex cyclic workflows but suffer from inefficient static model allocation, where deploying strong models uniformly wastes computation on trivial sub-tasks. We propose CASTER (Context-Aware Strategy for Task Efficient Routing), a lightweight router for dynamic model selection in graph-based MAS. CASTER employs a Dual-Signal Router that combines semantic embeddings with structural meta-features to estimate task difficulty. During training, the router self-optimizes through a Cold Start to Iterative Evolution paradigm, learning from its own routing failures via on-policy negative feedback. Experiments using LLM-as-a-Judge evaluation across Software Engineering, Data Analysis, Scientific Discovery, and Cybersecurity demonstrate that CASTER reduces inference cost by up to 72.4% compared to strong-model baselines while matching their success rates, and consistently outperforms both heuristic routing and FrugalGPT across all domains.
TSViT: A Time Series Vision Transformer for Fault Diagnosis
Nov 12, 2023Traditional fault diagnosis methods using Convolutional Neural Networks (CNNs) face limitations in capturing temporal features (i.e., the variation of vibration signals over time). To address this issue, this paper introduces a novel model, the Time Series Vision Transformer (TSViT), specifically designed for fault diagnosis. On one hand, TSViT model integrates a convolutional layer to segment vibration signals and capture local features. On the other hand, it employs a transformer encoder to learn long-term temporal information. The experimental results with other methods on two distinct datasets validate the effectiveness and generalizability of TSViT with a comparative analysis of its hyperparameters' impact on model performance, computational complexity, and overall parameter quantity. TSViT reaches average accuracies of 100% and 99.99% on two test sets, correspondingly.
Federated Learning in Big Model Era: Domain-Specific Multimodal Large Models
Aug 24, 2023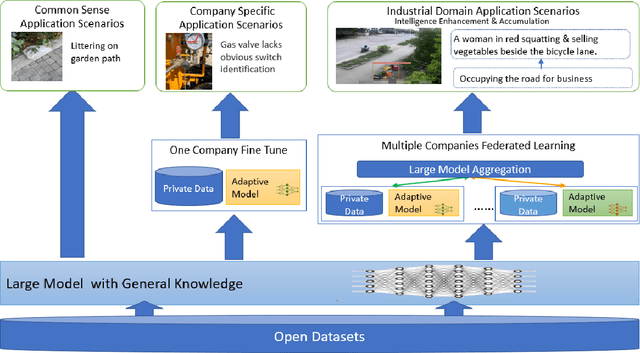
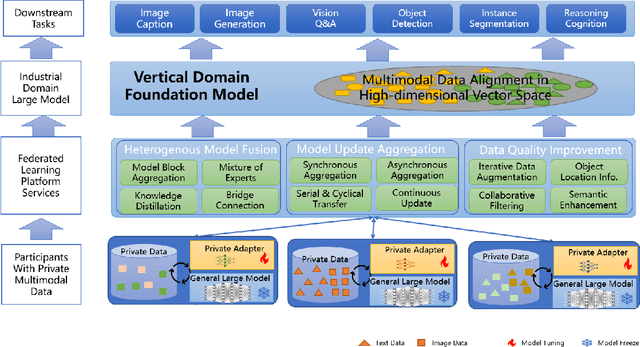
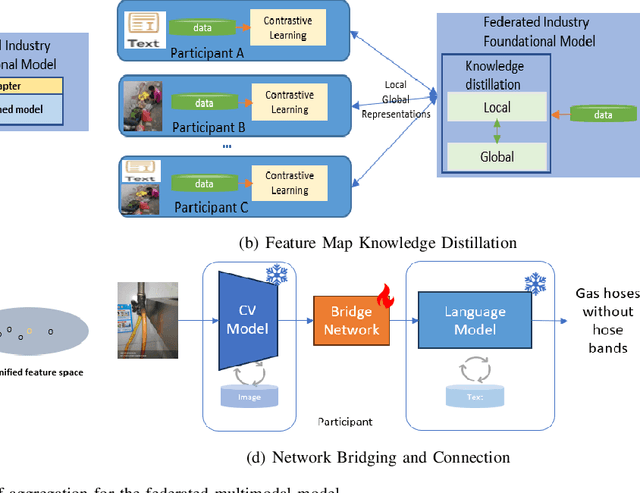
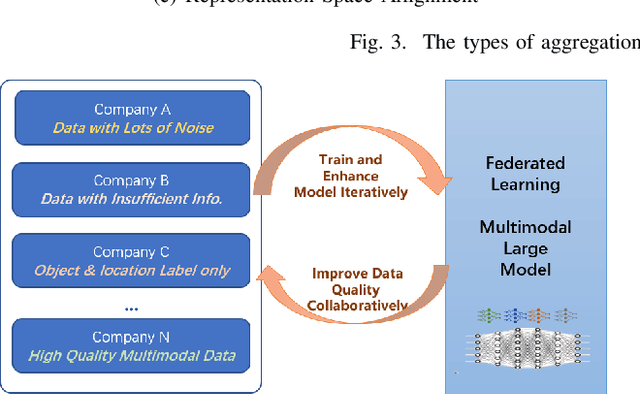
Multimodal data, which can comprehensively perceive and recognize the physical world, has become an essential path towards general artificial intelligence. However, multimodal large models trained on public datasets often underperform in specific industrial domains. This paper proposes a multimodal federated learning framework that enables multiple enterprises to utilize private domain data to collaboratively train large models for vertical domains, achieving intelligent services across scenarios. The authors discuss in-depth the strategic transformation of federated learning in terms of intelligence foundation and objectives in the era of big model, as well as the new challenges faced in heterogeneous data, model aggregation, performance and cost trade-off, data privacy, and incentive mechanism. The paper elaborates a case study of leading enterprises contributing multimodal data and expert knowledge to city safety operation management , including distributed deployment and efficient coordination of the federated learning platform, technical innovations on data quality improvement based on large model capabilities and efficient joint fine-tuning approaches. Preliminary experiments show that enterprises can enhance and accumulate intelligent capabilities through multimodal model federated learning, thereby jointly creating an smart city model that provides high-quality intelligent services covering energy infrastructure safety, residential community security, and urban operation management. The established federated learning cooperation ecosystem is expected to further aggregate industry, academia, and research resources, realize large models in multiple vertical domains, and promote the large-scale industrial application of artificial intelligence and cutting-edge research on multimodal federated learning.
Predicting Token Impact Towards Efficient Vision Transformer
May 24, 2023Token filtering to reduce irrelevant tokens prior to self-attention is a straightforward way to enable efficient vision Transformer. This is the first work to view token filtering from a feature selection perspective, where we weigh the importance of a token according to how much it can change the loss once masked. If the loss changes greatly after masking a token of interest, it means that such a token has a significant impact on the final decision and is thus relevant. Otherwise, the token is less important for the final decision, so it can be filtered out. After applying the token filtering module generalized from the whole training data, the token number fed to the self-attention module can be obviously reduced in the inference phase, leading to much fewer computations in all the subsequent self-attention layers. The token filter can be realized using a very simple network, where we utilize multi-layer perceptron. Except for the uniqueness of performing token filtering only once from the very beginning prior to self-attention, the other core feature making our method different from the other token filters lies in the predictability of token impact from a feature selection point of view. The experiments show that the proposed method provides an efficient way to approach a light weighted model after optimized with a backbone by means of fine tune, which is easy to be deployed in comparison with the existing methods based on training from scratch.
SIEDOB: Semantic Image Editing by Disentangling Object and Background
Mar 23, 2023



Semantic image editing provides users with a flexible tool to modify a given image guided by a corresponding segmentation map. In this task, the features of the foreground objects and the backgrounds are quite different. However, all previous methods handle backgrounds and objects as a whole using a monolithic model. Consequently, they remain limited in processing content-rich images and suffer from generating unrealistic objects and texture-inconsistent backgrounds. To address this issue, we propose a novel paradigm, \textbf{S}emantic \textbf{I}mage \textbf{E}diting by \textbf{D}isentangling \textbf{O}bject and \textbf{B}ackground (\textbf{SIEDOB}), the core idea of which is to explicitly leverages several heterogeneous subnetworks for objects and backgrounds. First, SIEDOB disassembles the edited input into background regions and instance-level objects. Then, we feed them into the dedicated generators. Finally, all synthesized parts are embedded in their original locations and utilize a fusion network to obtain a harmonized result. Moreover, to produce high-quality edited images, we propose some innovative designs, including Semantic-Aware Self-Propagation Module, Boundary-Anchored Patch Discriminator, and Style-Diversity Object Generator, and integrate them into SIEDOB. We conduct extensive experiments on Cityscapes and ADE20K-Room datasets and exhibit that our method remarkably outperforms the baselines, especially in synthesizing realistic and diverse objects and texture-consistent backgrounds.
Reference-Guided Large-Scale Face Inpainting with Identity and Texture Control
Mar 13, 2023Face inpainting aims at plausibly predicting missing pixels of face images within a corrupted region. Most existing methods rely on generative models learning a face image distribution from a big dataset, which produces uncontrollable results, especially with large-scale missing regions. To introduce strong control for face inpainting, we propose a novel reference-guided face inpainting method that fills the large-scale missing region with identity and texture control guided by a reference face image. However, generating high-quality results under imposing two control signals is challenging. To tackle such difficulty, we propose a dual control one-stage framework that decouples the reference image into two levels for flexible control: High-level identity information and low-level texture information, where the identity information figures out the shape of the face and the texture information depicts the component-aware texture. To synthesize high-quality results, we design two novel modules referred to as Half-AdaIN and Component-Wise Style Injector (CWSI) to inject the two kinds of control information into the inpainting processing. Our method produces realistic results with identity and texture control faithful to reference images. To the best of our knowledge, it is the first work to concurrently apply identity and component-level controls in face inpainting to promise more precise and controllable results. Code is available at https://github.com/WuyangLuo/RefFaceInpainting
Context-Consistent Semantic Image Editing with Style-Preserved Modulation
Jul 13, 2022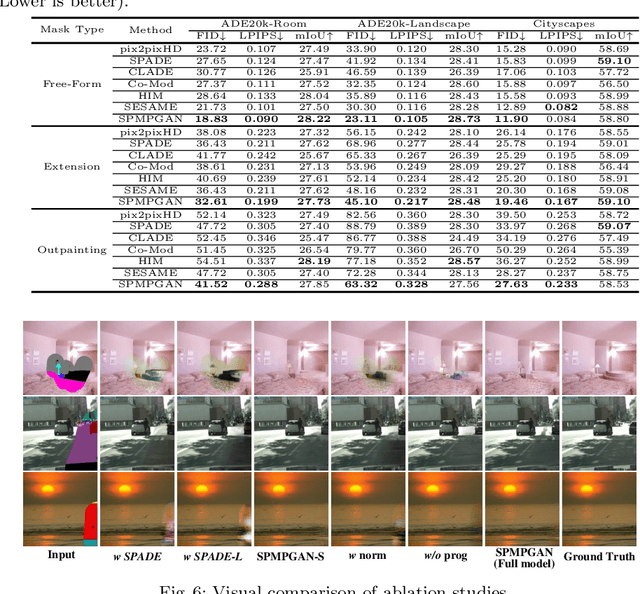
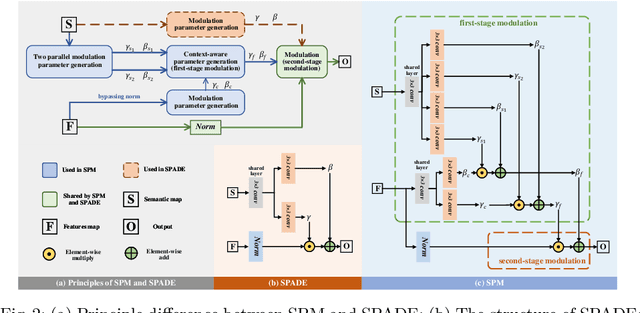
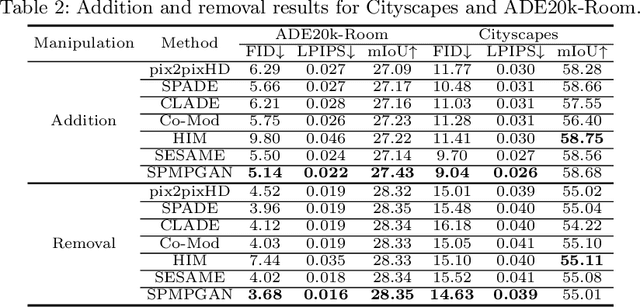
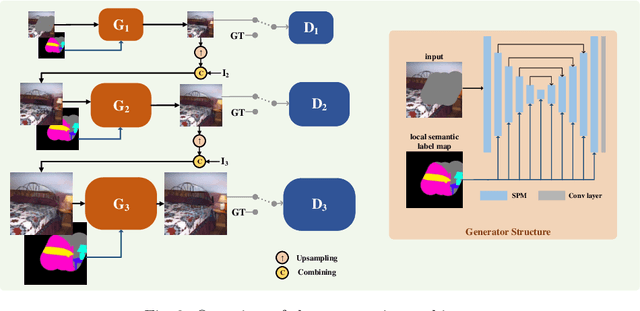
Semantic image editing utilizes local semantic label maps to generate the desired content in the edited region. A recent work borrows SPADE block to achieve semantic image editing. However, it cannot produce pleasing results due to style discrepancy between the edited region and surrounding pixels. We attribute this to the fact that SPADE only uses an image-independent local semantic layout but ignores the image-specific styles included in the known pixels. To address this issue, we propose a style-preserved modulation (SPM) comprising two modulations processes: The first modulation incorporates the contextual style and semantic layout, and then generates two fused modulation parameters. The second modulation employs the fused parameters to modulate feature maps. By using such two modulations, SPM can inject the given semantic layout while preserving the image-specific context style. Moreover, we design a progressive architecture for generating the edited content in a coarse-to-fine manner. The proposed method can obtain context-consistent results and significantly alleviate the unpleasant boundary between the generated regions and the known pixels.
Dynamic Virtual Network Embedding Algorithm based on Graph Convolution Neural Network and Reinforcement Learning
Feb 03, 2022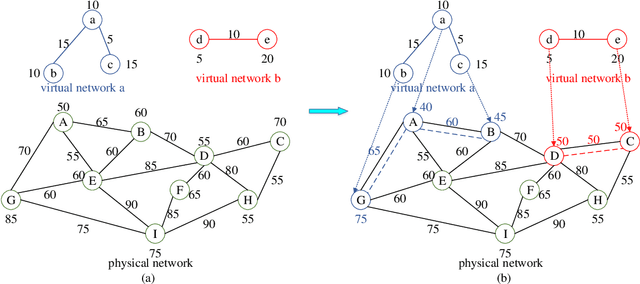
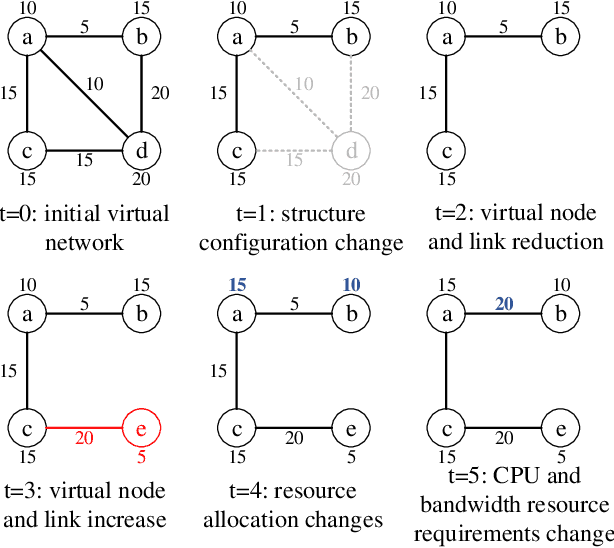
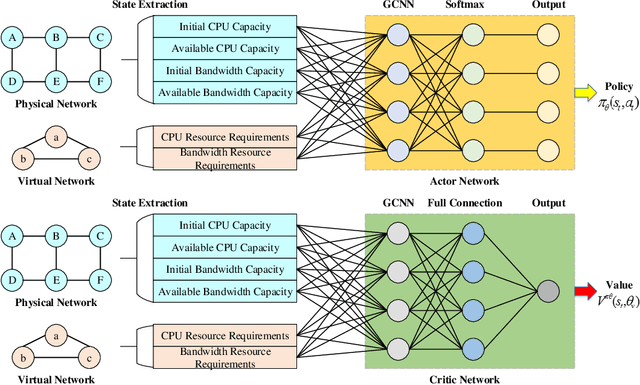
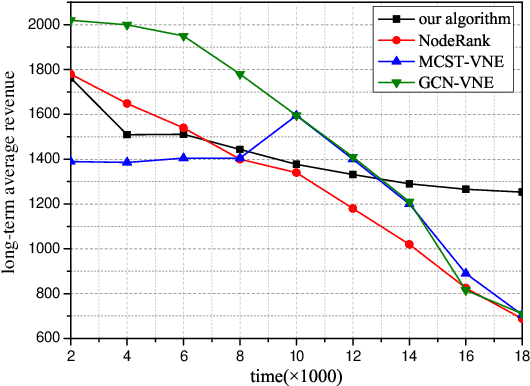
Network virtualization (NV) is a technology with broad application prospects. Virtual network embedding (VNE) is the core orientation of VN, which aims to provide more flexible underlying physical resource allocation for user function requests. The classical VNE problem is usually solved by heuristic method, but this method often limits the flexibility of the algorithm and ignores the time limit. In addition, the partition autonomy of physical domain and the dynamic characteristics of virtual network request (VNR) also increase the difficulty of VNE. This paper proposed a new type of VNE algorithm, which applied reinforcement learning (RL) and graph neural network (GNN) theory to the algorithm, especially the combination of graph convolutional neural network (GCNN) and RL algorithm. Based on a self-defined fitness matrix and fitness value, we set up the objective function of the algorithm implementation, realized an efficient dynamic VNE algorithm, and effectively reduced the degree of resource fragmentation. Finally, we used comparison algorithms to evaluate the proposed method. Simulation experiments verified that the dynamic VNE algorithm based on RL and GCNN has good basic VNE characteristics. By changing the resource attributes of physical network and virtual network, it can be proved that the algorithm has good flexibility.
TransPPG: Two-stream Transformer for Remote Heart Rate Estimate
Jan 26, 2022Non-contact facial video-based heart rate estimation using remote photoplethysmography (rPPG) has shown great potential in many applications (e.g., remote health care) and achieved creditable results in constrained scenarios. However, practical applications require results to be accurate even under complex environment with head movement and unstable illumination. Therefore, improving the performance of rPPG in complex environment has become a key challenge. In this paper, we propose a novel video embedding method that embeds each facial video sequence into a feature map referred to as Multi-scale Adaptive Spatial and Temporal Map with Overlap (MAST_Mop), which contains not only vital information but also surrounding information as reference, which acts as the mirror to figure out the homogeneous perturbations imposed on foreground and background simultaneously, such as illumination instability. Correspondingly, we propose a two-stream Transformer model to map the MAST_Mop into heart rate (HR), where one stream follows the pulse signal in the facial area while the other figures out the perturbation signal from the surrounding region such that the difference of the two channels leads to adaptive noise cancellation. Our approach significantly outperforms all current state-of-the-art methods on two public datasets MAHNOB-HCI and VIPL-HR. As far as we know, it is the first work with Transformer as backbone to capture the temporal dependencies in rPPGs and apply the two stream scheme to figure out the interference from backgrounds as mirror of the corresponding perturbation on foreground signals for noise tolerating.
Feature-context driven Federated Meta-Learning for Rare Disease Prediction
Dec 29, 2021
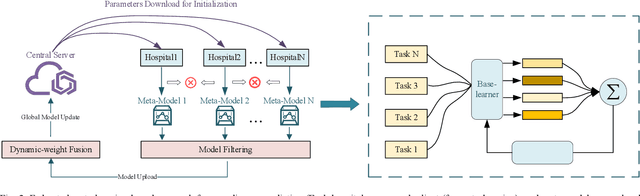
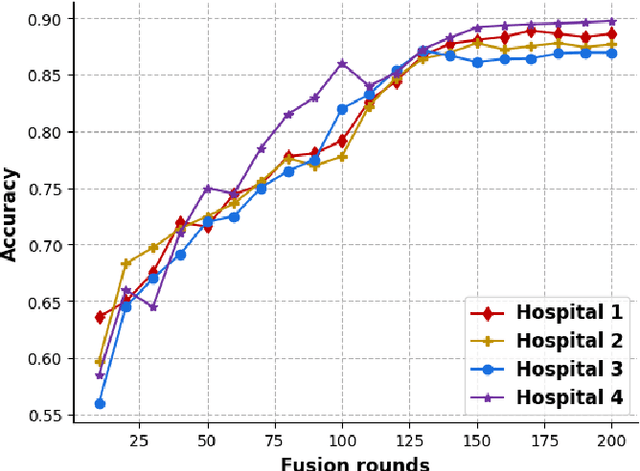
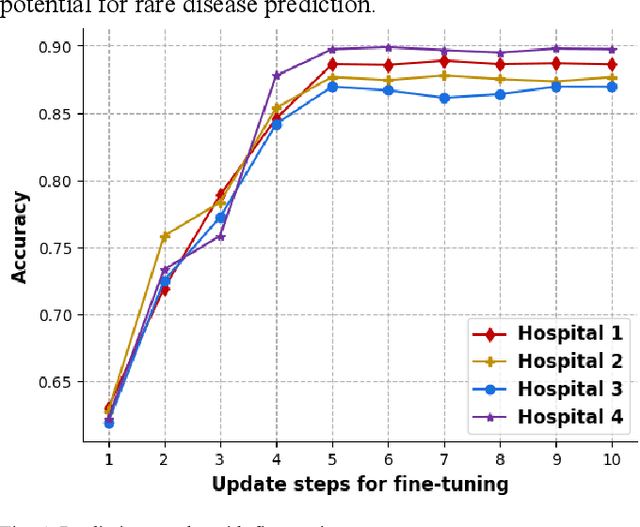
Millions of patients suffer from rare diseases around the world. However, the samples of rare diseases are much smaller than those of common diseases. In addition, due to the sensitivity of medical data, hospitals are usually reluctant to share patient information for data fusion citing privacy concerns. These challenges make it difficult for traditional AI models to extract rare disease features for the purpose of disease prediction. In this paper, we overcome this limitation by proposing a novel approach for rare disease prediction based on federated meta-learning. To improve the prediction accuracy of rare diseases, we design an attention-based meta-learning (ATML) approach which dynamically adjusts the attention to different tasks according to the measured training effect of base learners. Additionally, a dynamic-weight based fusion strategy is proposed to further improve the accuracy of federated learning, which dynamically selects clients based on the accuracy of each local model. Experiments show that with as few as five shots, our approach out-performs the original federated meta-learning algorithm in accuracy and speed. Compared with each hospital's local model, the proposed model's average prediction accuracy increased by 13.28%.