 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Large-Scale Foundational Model for Natural Gas Demand Forecasting
Sep 24, 2024



In the context of global energy strategy, accurate natural gas demand forecasting is crucial for ensuring efficient resource allocation and operational planning. Traditional forecasting methods struggle to cope with the growing complexity and variability of gas consumption patterns across diverse industries and commercial sectors. To address these challenges, we propose the first foundation model specifically tailored for natural gas demand forecasting. Foundation models, known for their ability to generalize across tasks and datasets, offer a robust solution to the limitations of traditional methods, such as the need for separate models for different customer segments and their limited generalization capabilities. Our approach leverages contrastive learning to improve prediction accuracy in real-world scenarios, particularly by tackling issues such as noise in historical consumption data and the potential misclassification of similar data samples, which can lead to degradation in the quaility of the representation and thus the accuracy of downstream forecasting tasks. By integrating advanced noise filtering techniques within the contrastive learning framework, our model enhances the quality of learned representations, leading to more accurate predictions. Furthermore, the model undergoes industry-specific fine-tuning during pretraining, enabling it to better capture the unique characteristics of gas consumption across various sectors. We conducted extensive experiments using a large-scale dataset from ENN Group, which includes data from over 10,000 industrial, commercial, and welfare-related customers across multiple regions. Our model outperformed existing state-of-the-art methods, demonstrating a relative improvement in MSE by 3.68\% and in MASE by 6.15\% compared to the best available model.
HiMTM: Hierarchical Multi-Scale Masked Time Series Modeling for Long-Term Forecasting
Jan 10, 2024Time series forecasting is crucial and challenging in the real world. The recent surge in interest regarding time series foundation models, which cater to a diverse array of downstream tasks, is noteworthy. However, existing methods often overlook the multi-scale nature of time series, an aspect crucial for precise forecasting. To bridge this gap, we propose HiMTM, a hierarchical multi-scale masked time series modeling method designed for long-term forecasting. Specifically, it comprises four integral components: (1) hierarchical multi-scale transformer (HMT) to capture temporal information at different scales; (2) decoupled encoder-decoder (DED) forces the encoder to focus on feature extraction, while the decoder to focus on pretext tasks; (3) multi-scale masked reconstruction (MMR) provides multi-stage supervision signals for pre-training; (4) cross-scale attention fine-tuning (CSA-FT) to capture dependencies between different scales for forecasting. Collectively, these components enhance multi-scale feature extraction capabilities in masked time series modeling and contribute to improved prediction accuracy. We conduct extensive experiments on 7 mainstream datasets to prove that HiMTM has obvious advantages over contemporary self-supervised and end-to-end learning methods. The effectiveness of HiMTM is further showcased by its application in the industry of natural gas demand forecasting.
Federated Learning in Big Model Era: Domain-Specific Multimodal Large Models
Aug 24, 2023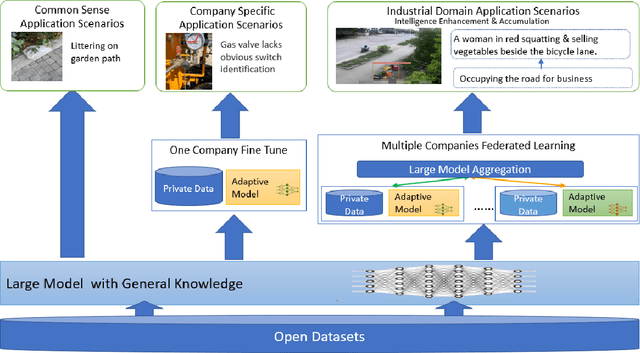
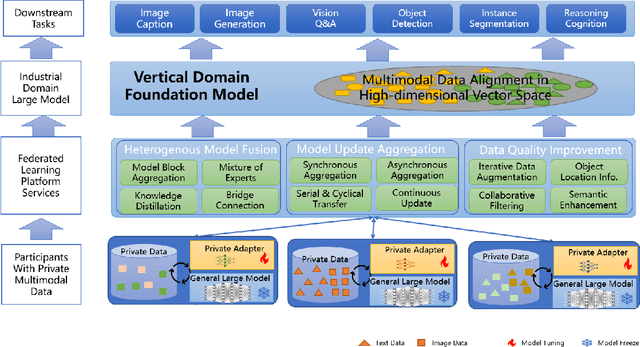
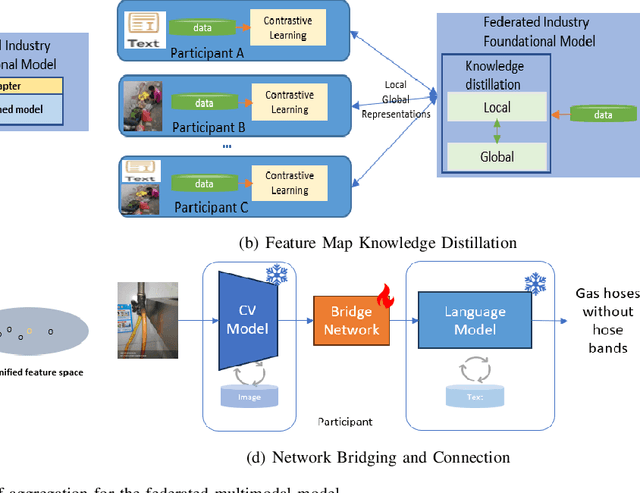
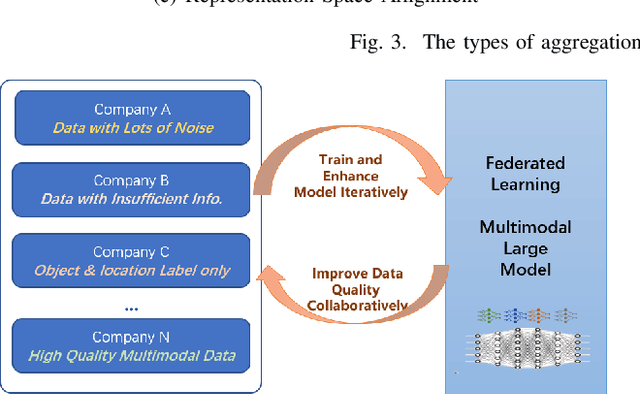
Multimodal data, which can comprehensively perceive and recognize the physical world, has become an essential path towards general artificial intelligence. However, multimodal large models trained on public datasets often underperform in specific industrial domains. This paper proposes a multimodal federated learning framework that enables multiple enterprises to utilize private domain data to collaboratively train large models for vertical domains, achieving intelligent services across scenarios. The authors discuss in-depth the strategic transformation of federated learning in terms of intelligence foundation and objectives in the era of big model, as well as the new challenges faced in heterogeneous data, model aggregation, performance and cost trade-off, data privacy, and incentive mechanism. The paper elaborates a case study of leading enterprises contributing multimodal data and expert knowledge to city safety operation management , including distributed deployment and efficient coordination of the federated learning platform, technical innovations on data quality improvement based on large model capabilities and efficient joint fine-tuning approaches. Preliminary experiments show that enterprises can enhance and accumulate intelligent capabilities through multimodal model federated learning, thereby jointly creating an smart city model that provides high-quality intelligent services covering energy infrastructure safety, residential community security, and urban operation management. The established federated learning cooperation ecosystem is expected to further aggregate industry, academia, and research resources, realize large models in multiple vertical domains, and promote the large-scale industrial application of artificial intelligence and cutting-edge research on multimodal federated learning.
The Prospect of Enhancing Large-Scale Heterogeneous Federated Learning with Transformers
Aug 22, 2023Federated learning (FL) addresses data privacy concerns by enabling collaborative training of AI models across distributed data owners. Wide adoption of FL faces the fundamental challenges of data heterogeneity and the large scale of data owners involved. In this paper, we investigate the prospect of Transformer-based FL models for achieving generalization and personalization in this setting. We conduct extensive comparative experiments involving FL with Transformers, ResNet, and personalized ResNet-based FL approaches under various scenarios. These experiments consider varying numbers of data owners to demonstrate Transformers' advantages over deep neural networks in large-scale heterogeneous FL tasks. In addition, we analyze the superior performance of Transformers by comparing the Centered Kernel Alignment (CKA) representation similarity across different layers and FL models to gain insight into the reasons behind their promising capabilities.
FedDRL: A Trustworthy Federated Learning Model Fusion Method Based on Staged Reinforcement Learning
Jul 25, 2023



Traditional federated learning uses the number of samples to calculate the weights of each client model and uses this fixed weight value to fusion the global model. However, in practical scenarios, each client's device and data heterogeneity leads to differences in the quality of each client's model. Thus the contribution to the global model is not wholly determined by the sample size. In addition, if clients intentionally upload low-quality or malicious models, using these models for aggregation will lead to a severe decrease in global model accuracy. Traditional federated learning algorithms do not address these issues. To solve this probelm, we propose FedDRL, a model fusion approach using reinforcement learning based on a two staged approach. In the first stage, Our method could filter out malicious models and selects trusted client models to participate in the model fusion. In the second stage, the FedDRL algorithm adaptively adjusts the weights of the trusted client models and aggregates the optimal global model. We also define five model fusion scenarios and compare our method with two baseline algorithms in those scenarios. The experimental results show that our algorithm has higher reliability than other algorithms while maintaining accuracy.
Feature-context driven Federated Meta-Learning for Rare Disease Prediction
Dec 29, 2021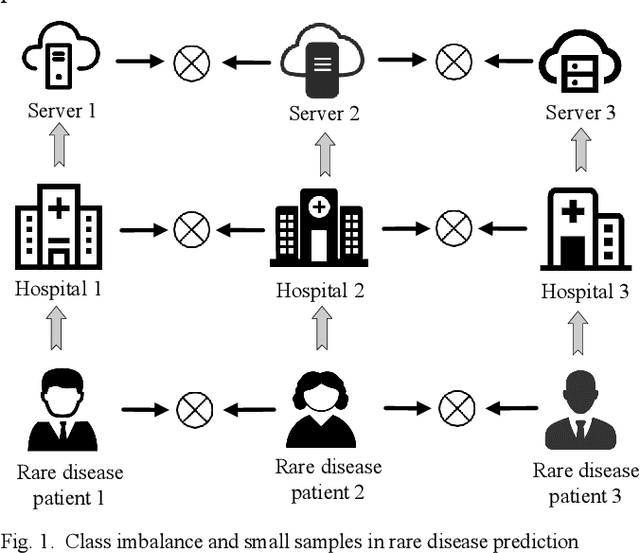
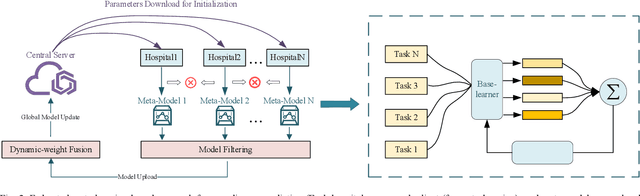
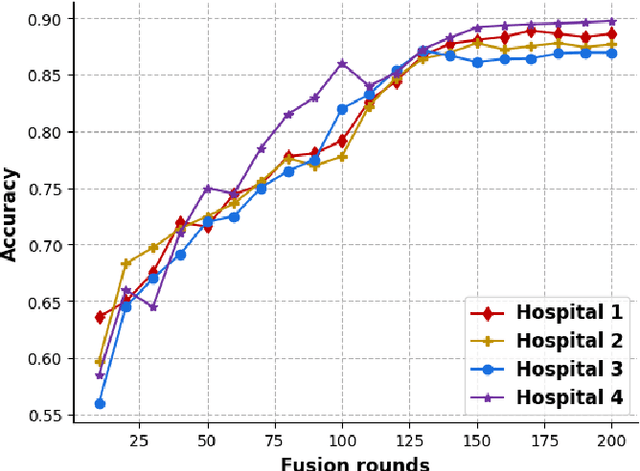
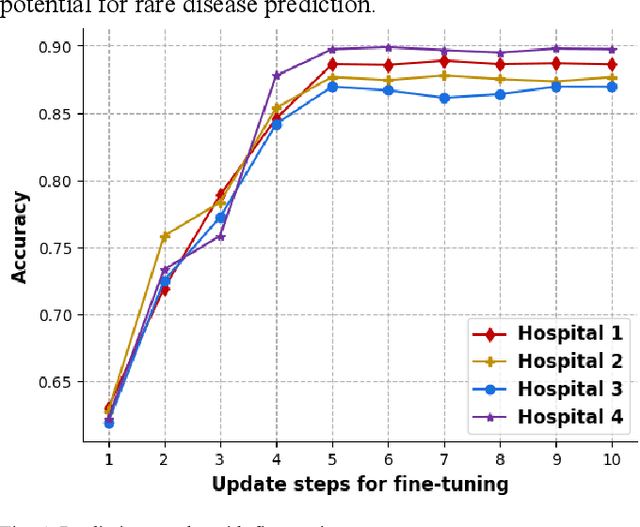
Millions of patients suffer from rare diseases around the world. However, the samples of rare diseases are much smaller than those of common diseases. In addition, due to the sensitivity of medical data, hospitals are usually reluctant to share patient information for data fusion citing privacy concerns. These challenges make it difficult for traditional AI models to extract rare disease features for the purpose of disease prediction. In this paper, we overcome this limitation by proposing a novel approach for rare disease prediction based on federated meta-learning. To improve the prediction accuracy of rare diseases, we design an attention-based meta-learning (ATML) approach which dynamically adjusts the attention to different tasks according to the measured training effect of base learners. Additionally, a dynamic-weight based fusion strategy is proposed to further improve the accuracy of federated learning, which dynamically selects clients based on the accuracy of each local model. Experiments show that with as few as five shots, our approach out-performs the original federated meta-learning algorithm in accuracy and speed. Compared with each hospital's local model, the proposed model's average prediction accuracy increased by 13.28%.