 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttack End-to-End Autonomous Driving through Module-Wise Noise
Sep 12, 2024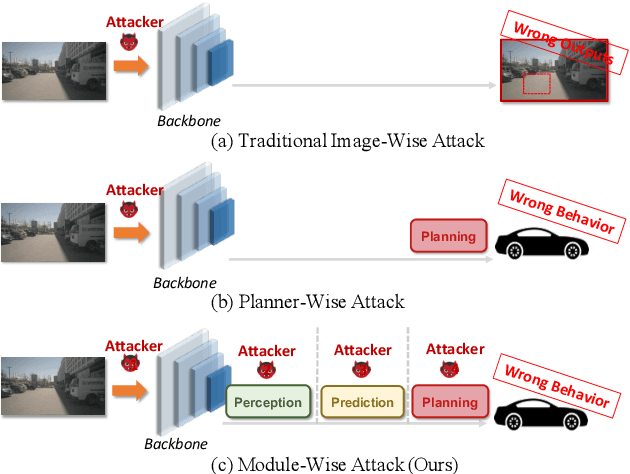
With recent breakthroughs in deep neural networks, numerous tasks within autonomous driving have exhibited remarkable performance. However, deep learning models are susceptible to adversarial attacks, presenting significant security risks to autonomous driving systems. Presently, end-to-end architectures have emerged as the predominant solution for autonomous driving, owing to their collaborative nature across different tasks. Yet, the implications of adversarial attacks on such models remain relatively unexplored. In this paper, we conduct comprehensive adversarial security research on the modular end-to-end autonomous driving model for the first time. We thoroughly consider the potential vulnerabilities in the model inference process and design a universal attack scheme through module-wise noise injection. We conduct large-scale experiments on the full-stack autonomous driving model and demonstrate that our attack method outperforms previous attack methods. We trust that our research will offer fresh insights into ensuring the safety and reliability of autonomous driving systems.
Module-wise Adaptive Adversarial Training for End-to-end Autonomous Driving
Sep 11, 2024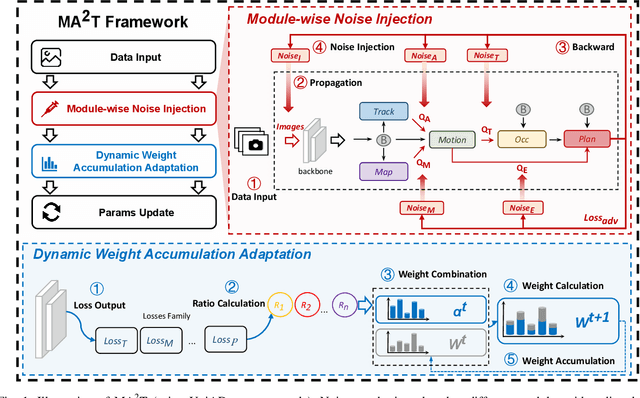
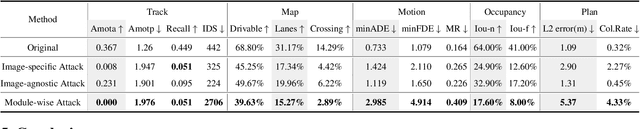
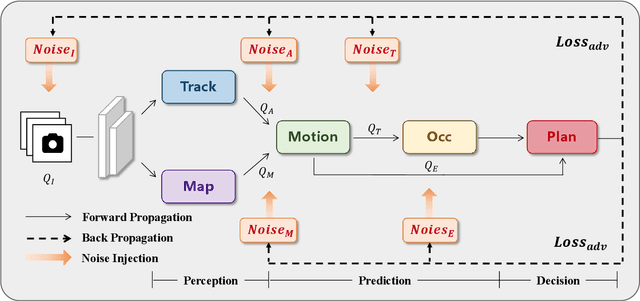
Recent advances in deep learning have markedly improved autonomous driving (AD) models, particularly end-to-end systems that integrate perception, prediction, and planning stages, achieving state-of-the-art performance. However, these models remain vulnerable to adversarial attacks, where human-imperceptible perturbations can disrupt decision-making processes. While adversarial training is an effective method for enhancing model robustness against such attacks, no prior studies have focused on its application to end-to-end AD models. In this paper, we take the first step in adversarial training for end-to-end AD models and present a novel Module-wise Adaptive Adversarial Training (MA2T). However, extending conventional adversarial training to this context is highly non-trivial, as different stages within the model have distinct objectives and are strongly interconnected. To address these challenges, MA2T first introduces Module-wise Noise Injection, which injects noise before the input of different modules, targeting training models with the guidance of overall objectives rather than each independent module loss. Additionally, we introduce Dynamic Weight Accumulation Adaptation, which incorporates accumulated weight changes to adaptively learn and adjust the loss weights of each module based on their contributions (accumulated reduction rates) for better balance and robust training. To demonstrate the efficacy of our defense, we conduct extensive experiments on the widely-used nuScenes dataset across several end-to-end AD models under both white-box and black-box attacks, where our method outperforms other baselines by large margins (+5-10%). Moreover, we validate the robustness of our defense through closed-loop evaluation in the CARLA simulation environment, showing improved resilience even against natural corruption.
TransPPG: Two-stream Transformer for Remote Heart Rate Estimate
Jan 26, 2022Non-contact facial video-based heart rate estimation using remote photoplethysmography (rPPG) has shown great potential in many applications (e.g., remote health care) and achieved creditable results in constrained scenarios. However, practical applications require results to be accurate even under complex environment with head movement and unstable illumination. Therefore, improving the performance of rPPG in complex environment has become a key challenge. In this paper, we propose a novel video embedding method that embeds each facial video sequence into a feature map referred to as Multi-scale Adaptive Spatial and Temporal Map with Overlap (MAST_Mop), which contains not only vital information but also surrounding information as reference, which acts as the mirror to figure out the homogeneous perturbations imposed on foreground and background simultaneously, such as illumination instability. Correspondingly, we propose a two-stream Transformer model to map the MAST_Mop into heart rate (HR), where one stream follows the pulse signal in the facial area while the other figures out the perturbation signal from the surrounding region such that the difference of the two channels leads to adaptive noise cancellation. Our approach significantly outperforms all current state-of-the-art methods on two public datasets MAHNOB-HCI and VIPL-HR. As far as we know, it is the first work with Transformer as backbone to capture the temporal dependencies in rPPGs and apply the two stream scheme to figure out the interference from backgrounds as mirror of the corresponding perturbation on foreground signals for noise tolerating.