 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFontCrafter: High-Fidelity Element-Driven Artistic Font Creation with Visual In-Context Generation
Mar 23, 2026Artistic font generation aims to synthesize stylized glyphs based on a reference style. However, existing approaches suffer from limited style diversity and coarse control. In this work, we explore the potential of element-driven artistic font generation. Elements are the fundamental visual units of a font, serving as reference images for the desired style. Conceptually, we categorize elements into object elements (e.g., flowers or stones) with distinct structures and amorphous elements (e.g., flames or clouds) with unstructured textures. We introduce FontCrafter, an element-driven framework for font creation, and construct a large-scale dataset, ElementFont, which contains diverse element types and high-quality glyph images. However, achieving high-fidelity reconstruction of both texture and structure of reference elements remains challenging. To address this, we propose an in-context generation strategy that treats element images as visual context and uses an inpainting model to transfer element styles into glyph regions at the pixel level. To further control glyph shapes, we design a lightweight Context-aware Mask Adapter (CMA) that injects shape information. Moreover, a training-free attention redirection mechanism enables region-aware style control and suppresses stroke hallucination. In addition, edge repainting is applied to make boundaries more natural. Extensive experiments demonstrate that FontCrafter achieves strong zero-shot generation performance, particularly in preserving structural and textural fidelity, while also supporting flexible controls such as style mixture.
SIEDOB: Semantic Image Editing by Disentangling Object and Background
Mar 23, 2023



Semantic image editing provides users with a flexible tool to modify a given image guided by a corresponding segmentation map. In this task, the features of the foreground objects and the backgrounds are quite different. However, all previous methods handle backgrounds and objects as a whole using a monolithic model. Consequently, they remain limited in processing content-rich images and suffer from generating unrealistic objects and texture-inconsistent backgrounds. To address this issue, we propose a novel paradigm, \textbf{S}emantic \textbf{I}mage \textbf{E}diting by \textbf{D}isentangling \textbf{O}bject and \textbf{B}ackground (\textbf{SIEDOB}), the core idea of which is to explicitly leverages several heterogeneous subnetworks for objects and backgrounds. First, SIEDOB disassembles the edited input into background regions and instance-level objects. Then, we feed them into the dedicated generators. Finally, all synthesized parts are embedded in their original locations and utilize a fusion network to obtain a harmonized result. Moreover, to produce high-quality edited images, we propose some innovative designs, including Semantic-Aware Self-Propagation Module, Boundary-Anchored Patch Discriminator, and Style-Diversity Object Generator, and integrate them into SIEDOB. We conduct extensive experiments on Cityscapes and ADE20K-Room datasets and exhibit that our method remarkably outperforms the baselines, especially in synthesizing realistic and diverse objects and texture-consistent backgrounds.
Reference-Guided Large-Scale Face Inpainting with Identity and Texture Control
Mar 13, 2023Face inpainting aims at plausibly predicting missing pixels of face images within a corrupted region. Most existing methods rely on generative models learning a face image distribution from a big dataset, which produces uncontrollable results, especially with large-scale missing regions. To introduce strong control for face inpainting, we propose a novel reference-guided face inpainting method that fills the large-scale missing region with identity and texture control guided by a reference face image. However, generating high-quality results under imposing two control signals is challenging. To tackle such difficulty, we propose a dual control one-stage framework that decouples the reference image into two levels for flexible control: High-level identity information and low-level texture information, where the identity information figures out the shape of the face and the texture information depicts the component-aware texture. To synthesize high-quality results, we design two novel modules referred to as Half-AdaIN and Component-Wise Style Injector (CWSI) to inject the two kinds of control information into the inpainting processing. Our method produces realistic results with identity and texture control faithful to reference images. To the best of our knowledge, it is the first work to concurrently apply identity and component-level controls in face inpainting to promise more precise and controllable results. Code is available at https://github.com/WuyangLuo/RefFaceInpainting
Context-Consistent Semantic Image Editing with Style-Preserved Modulation
Jul 13, 2022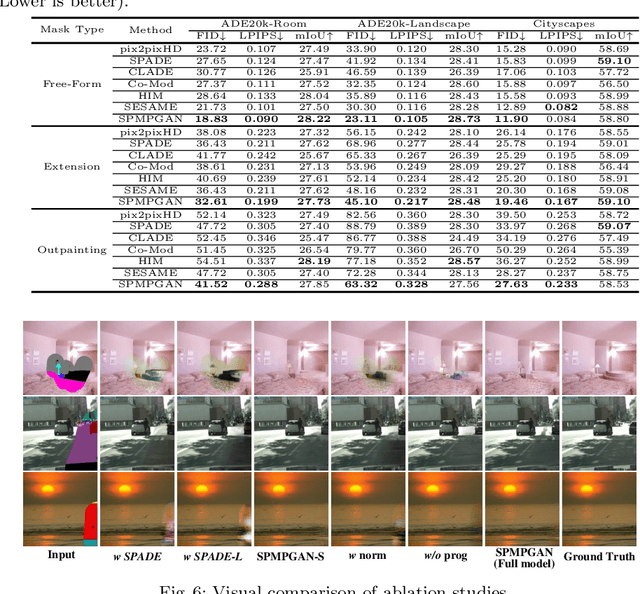
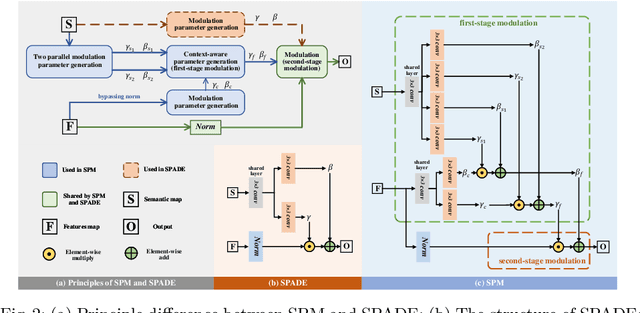
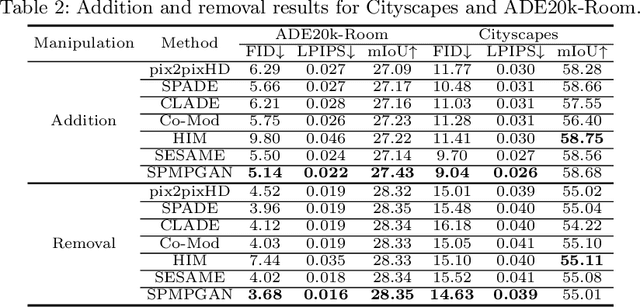
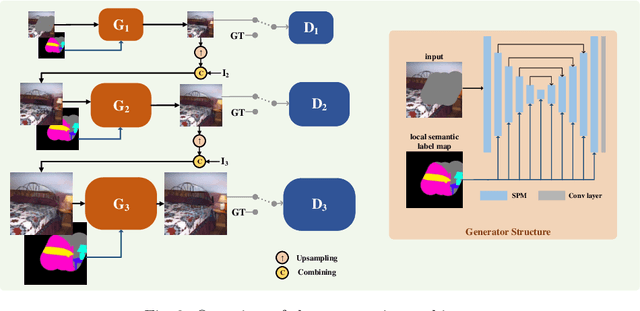
Semantic image editing utilizes local semantic label maps to generate the desired content in the edited region. A recent work borrows SPADE block to achieve semantic image editing. However, it cannot produce pleasing results due to style discrepancy between the edited region and surrounding pixels. We attribute this to the fact that SPADE only uses an image-independent local semantic layout but ignores the image-specific styles included in the known pixels. To address this issue, we propose a style-preserved modulation (SPM) comprising two modulations processes: The first modulation incorporates the contextual style and semantic layout, and then generates two fused modulation parameters. The second modulation employs the fused parameters to modulate feature maps. By using such two modulations, SPM can inject the given semantic layout while preserving the image-specific context style. Moreover, we design a progressive architecture for generating the edited content in a coarse-to-fine manner. The proposed method can obtain context-consistent results and significantly alleviate the unpleasant boundary between the generated regions and the known pixels.