 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box Adversarial Attacks Against Image Quality Assessment Models
Paper and Code
Feb 28, 2024

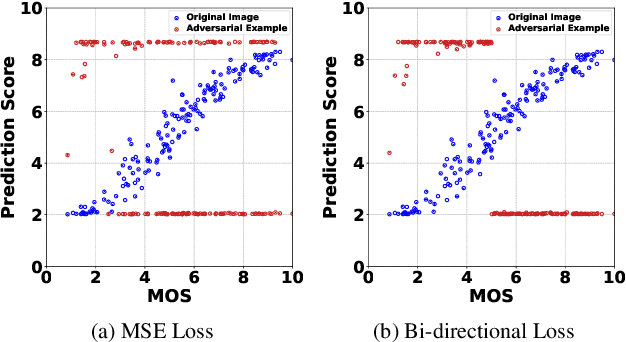
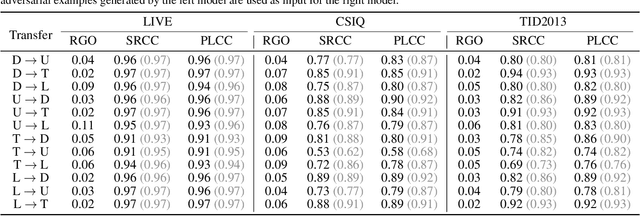
The goal of No-Reference Image Quality Assessment (NR-IQA) is to predict the perceptual quality of an image in line with its subjective evaluation. To put the NR-IQA models into practice, it is essential to study their potential loopholes for model refinement. This paper makes the first attempt to explore the black-box adversarial attacks on NR-IQA models. Specifically, we first formulate the attack problem as maximizing the deviation between the estimated quality scores of original and perturbed images, while restricting the perturbed image distortions for visual quality preservation. Under such formulation, we then design a Bi-directional loss function to mislead the estimated quality scores of adversarial examples towards an opposite direction with maximum deviation. On this basis, we finally develop an efficient and effective black-box attack method against NR-IQA models. Extensive experiments reveal that all the evaluated NR-IQA models are vulnerable to the proposed attack method. And the generated perturbations are not transferable, enabling them to serve the investigation of specialities of disparate IQA models.