 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedMKEB: A Comprehensive Knowledge Editing Benchmark for Medical Multimodal Large Language Models
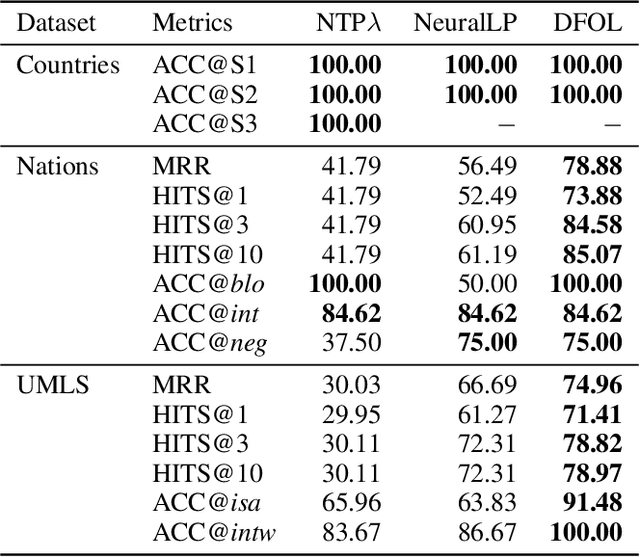
Aug 07, 2025Recent advances in multimodal large language models (MLLMs) have significantly improved medical AI, enabling it to unify the understanding of visual and textual information. However, as medical knowledge continues to evolve, it is critical to allow these models to efficiently update outdated or incorrect information without retraining from scratch. Although textual knowledge editing has been widely studied, there is still a lack of systematic benchmarks for multimodal medical knowledge editing involving image and text modalities. To fill this gap, we present MedMKEB, the first comprehensive benchmark designed to evaluate the reliability, generality, locality, portability, and robustness of knowledge editing in medical multimodal large language models. MedMKEB is built on a high-quality medical visual question-answering dataset and enriched with carefully constructed editing tasks, including counterfactual correction, semantic generalization, knowledge transfer, and adversarial robustness. We incorporate human expert validation to ensure the accuracy and reliability of the benchmark. Extensive single editing and sequential editing experiments on state-of-the-art general and medical MLLMs demonstrate the limitations of existing knowledge-based editing approaches in medicine, highlighting the need to develop specialized editing strategies. MedMKEB will serve as a standard benchmark to promote the development of trustworthy and efficient medical knowledge editing algorithms.
First-Choice Maximality Meets Ex-ante and Ex-post Fairness
May 08, 2023For the assignment problem where multiple indivisible items are allocated to a group of agents given their ordinal preferences, we design randomized mechanisms that satisfy first-choice maximality (FCM), i.e., maximizing the number of agents assigned their first choices, together with Pareto efficiency (PE). Our mechanisms also provide guarantees of ex-ante and ex-post fairness. The generalized eager Boston mechanism is ex-ante envy-free, and ex-post envy-free up to one item (EF1). The generalized probabilistic Boston mechanism is also ex-post EF1, and satisfies ex-ante efficiency instead of fairness. We also show that no strategyproof mechanism satisfies ex-post PE, EF1, and FCM simultaneously. In doing so, we expand the frontiers of simultaneously providing efficiency and both ex-ante and ex-post fairness guarantees for the assignment problem.
A separation logic for sequences in pointer programs and its decidability
Jan 16, 2023Separation logic and its variants can describe various properties on pointer programs. However, when it comes to properties on sequences, one may find it hard to formalize. To deal with properties on variable-length sequences and multilevel data structures, we propose sequence-heap separation logic which integrates sequences into logical reasoning on heap-manipulated programs. Quantifiers over sequence variables and singleton heap storing sequence (sequence singleton heap) are new members in our logic. Further, we study the satisfiability problem of two fragments. The propositional fragment of sequence-heap separation logic is decidable, and the fragment with 2 alternations on program variables and 1 alternation on sequence variables is undecidable. In addition, we explore boundaries between decidable and undecidable fragments of the logic with prenex normal form.
Differentially Private Condorcet Voting
Jun 27, 2022
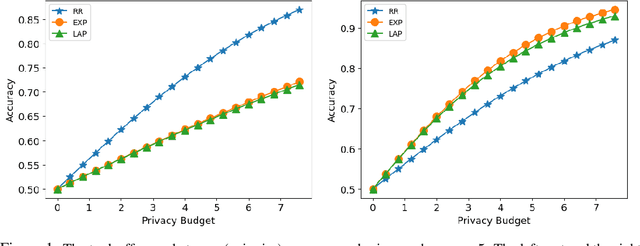
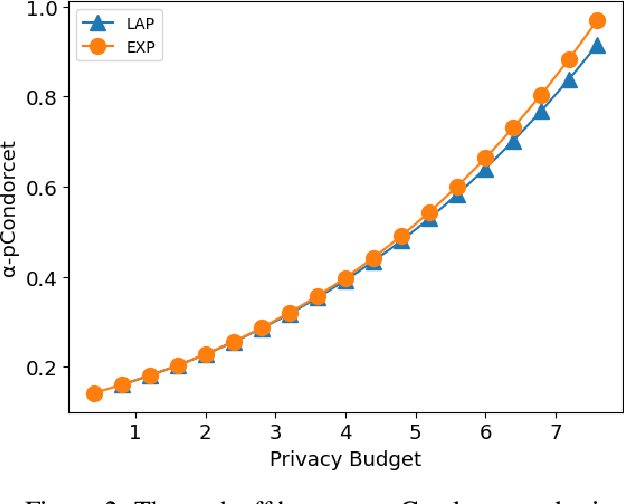
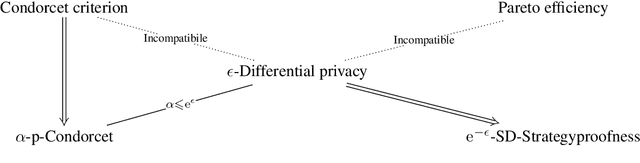
Designing private voting rules is an important and pressing problem for trustworthy democracy. In this paper, under the framework of differential privacy, we propose three classes of randomized voting rules based on the well-known Condorcet method: Laplacian Condorcet method ($CM^{LAP}_\lambda$), exponential Condorcet method ($CM^{EXP}_\lambda$), and randomized response Condorcet method ($CM^{RR}_\lambda$), where $\lambda$ represents the level of noise. By accurately estimating the errors introduced by the randomness, we show that $CM^{EXP}_\lambda$ is the most accurate mechanism in most cases. We prove that all of our rules satisfy absolute monotonicity, lexi-participation, probabilistic Pareto efficiency, approximate probabilistic Condorcet criterion, and approximate SD-strategyproofness. In addition, $CM^{RR}_\lambda$ satisfies (non-approximate) probabilistic Condorcet criterion, while $CM^{LAP}_\lambda$ and $CM^{EXP}_\lambda$ satisfy strong lexi-participation. Finally, we regard differential privacy as a voting axiom, and discuss its relations to other axioms.
Learning First-Order Rules with Differentiable Logic Program Semantics
Apr 28, 2022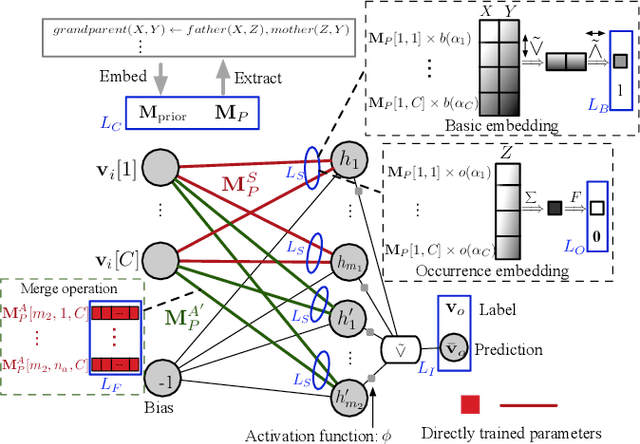
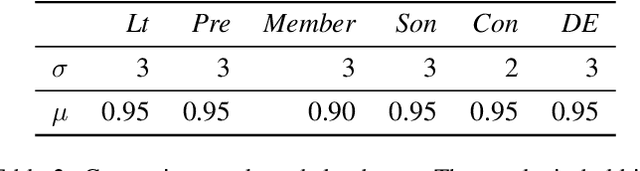

Learning first-order logic programs (LPs) from relational facts which yields intuitive insights into the data is a challenging topic in neuro-symbolic research. We introduce a novel differentiable inductive logic programming (ILP) model, called differentiable first-order rule learner (DFOL), which finds the correct LPs from relational facts by searching for the interpretable matrix representations of LPs. These interpretable matrices are deemed as trainable tensors in neural networks (NNs). The NNs are devised according to the differentiable semantics of LPs. Specifically, we first adopt a novel propositionalization method that transfers facts to NN-readable vector pairs representing interpretation pairs. We replace the immediate consequence operator with NN constraint functions consisting of algebraic operations and a sigmoid-like activation function. We map the symbolic forward-chained format of LPs into NN constraint functions consisting of operations between subsymbolic vector representations of atoms. By applying gradient descent, the trained well parameters of NNs can be decoded into precise symbolic LPs in forward-chained logic format. We demonstrate that DFOL can perform on several standard ILP datasets, knowledge bases, and probabilistic relation facts and outperform several well-known differentiable ILP models. Experimental results indicate that DFOL is a precise, robust, scalable, and computationally cheap differentiable ILP model.
Favoring Eagerness for Remaining Items: Achieving Efficient and Fair Assignments
Sep 18, 2021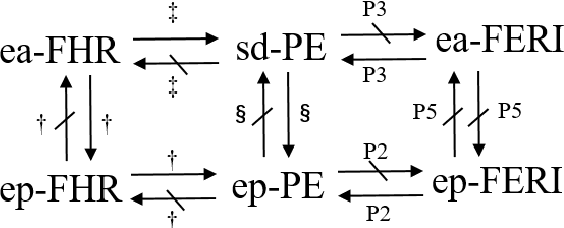
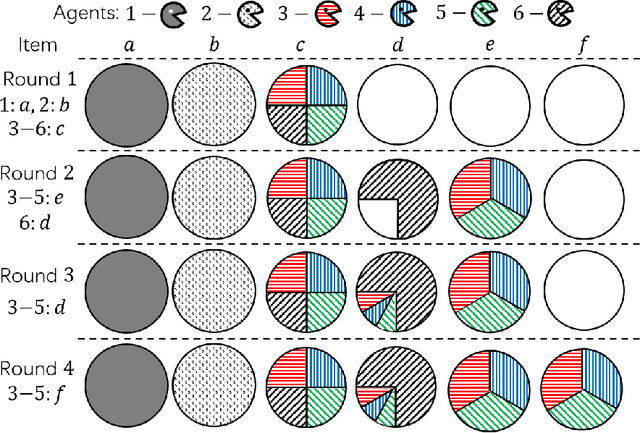
In the assignment problem, items must be assigned to agents who have unit demands, based on agents' ordinal preferences. Often the goal is to design a mechanism that is both fair and efficient. In this paper, we first prove that, unfortunately, the desirable efficiency notions rank-maximality, ex-post favoring-higher-ranks, and ex-ante favoring-higher-ranks, which aim to allocate each item to agents who rank it highest over all the items, are incompatible with the desirable fairness notions strong equal treatment of equals (SETE) and sd-weak-envy-freeness (sd-WEF) simultaneously. In light of this, we propose novel properties of efficiency based on a subtly different notion to favoring higher ranks, by favoring "eagerness" for remaining items and aiming to guarantee that each item is allocated to agents who rank it highest among remaining items. Specifically, we propose ex-post favoring-eagerness-for-remaining-items (ep-FERI) and ex-ante favoring-eagerness-for-remaining-items (ea-FERI). We prove that the eager Boston mechanism satisfies ep-FERI and sd-WSP and that the uniform probabilistic respecting eagerness mechanism satisfies ea-FERI. We also prove that both mechanisms satisfy SETE and sd-WEF, and show that no mechanism can satisfy stronger versions of envy-freeness and strategyproofness while simultaneously maintaining SETE, and either ep-FERI or ea-FERI.
StarVQA: Space-Time Attention for Video Quality Assessment
Aug 22, 2021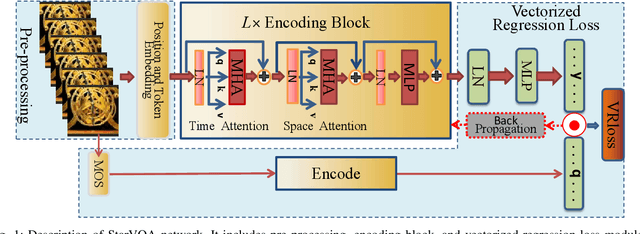
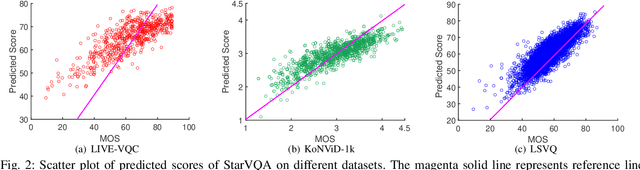
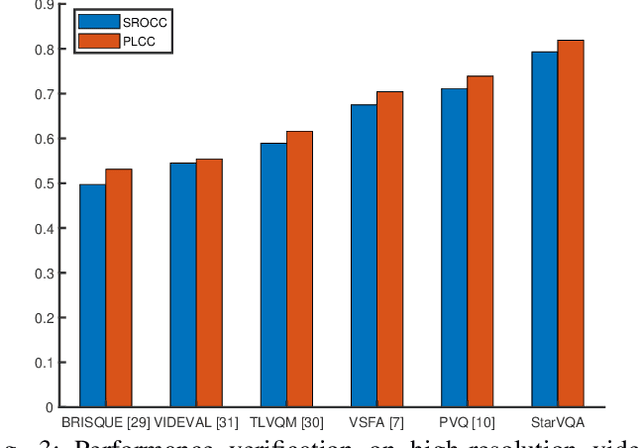
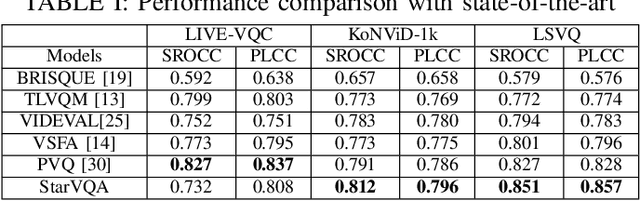
The attention mechanism is blooming in computer vision nowadays. However, its application to video quality assessment (VQA) has not been reported. Evaluating the quality of in-the-wild videos is challenging due to the unknown of pristine reference and shooting distortion. This paper presents a novel \underline{s}pace-\underline{t}ime \underline{a}ttention network fo\underline{r} the \underline{VQA} problem, named StarVQA. StarVQA builds a Transformer by alternately concatenating the divided space-time attention. To adapt the Transformer architecture for training, StarVQA designs a vectorized regression loss by encoding the mean opinion score (MOS) to the probability vector and embedding a special vectorized label token as the learnable variable. To capture the long-range spatiotemporal dependencies of a video sequence, StarVQA encodes the space-time position information of each patch to the input of the Transformer. Various experiments are conducted on the de-facto in-the-wild video datasets, including LIVE-VQC, KoNViD-1k, LSVQ, and LSVQ-1080p. Experimental results demonstrate the superiority of the proposed StarVQA over the state-of-the-art. Code and model will be available at: https://github.com/DVL/StarVQA.
Probabilistic Serial Mechanism for Multi-Type Resource Allocation
Apr 25, 2020
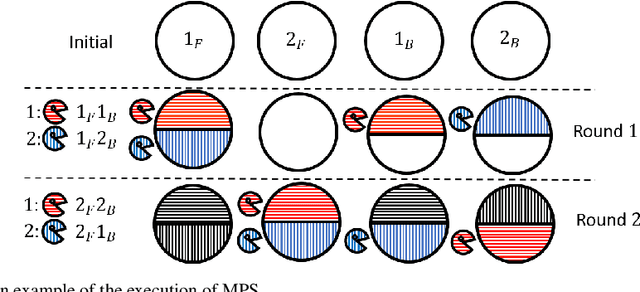
In multi-type resource allocation (MTRA) problems, there are p $\ge$ 2 types of items, and n agents, who each demand one unit of items of each type, and have strict linear preferences over bundles consisting of one item of each type. For MTRAs with indivisible items, our first result is an impossibility theorem that is in direct contrast to the single type (p = 1) setting: No mechanism, the output of which is always decomposable into a probability distribution over discrete assignments (where no item is split between agents), can satisfy both sd-efficiency and sd-envy-freeness. To circumvent this impossibility result, we consider the natural assumption of lexicographic preference, and provide an extension of the probabilistic serial (PS), called lexicographic probabilistic serial (LexiPS).We prove that LexiPS satisfies sd-efficiency and sd-envy-freeness, retaining the desirable properties of PS. Moreover, LexiPS satisfies sd-weak-strategyproofness when agents are not allowed to misreport their importance orders. For MTRAs with divisible items, we show that the existing multi-type probabilistic serial (MPS) mechanism satisfies the stronger efficiency notion of lexi-efficiency, and is sd-envy-free under strict linear preferences, and sd-weak-strategyproof under lexicographic preferences. We also prove that MPS can be characterized both by leximin-ptimality and by item-wise ordinal fairness, and the family of eating algorithms which MPS belongs to can be characterized by no-generalized-cycle condition.
Multi-type Resource Allocation with Partial Preferences
Jun 13, 2019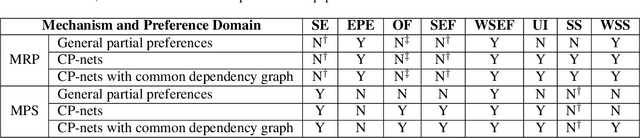
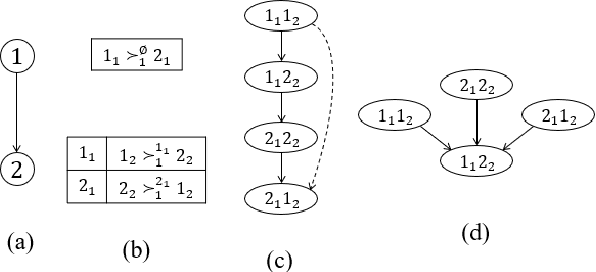
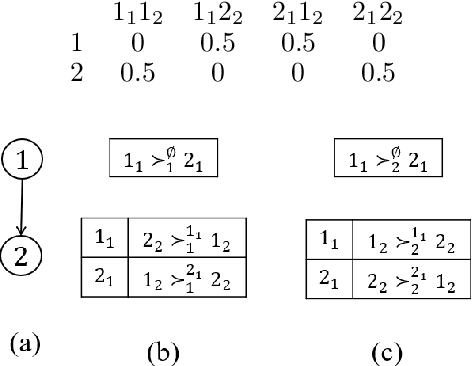
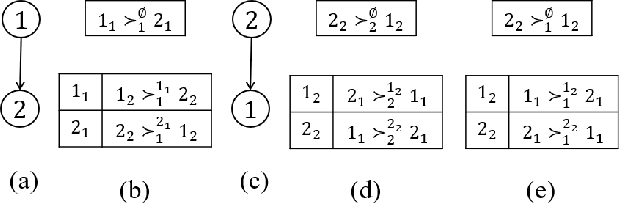
We propose multi-type probabilistic serial (MPS) and multi-type random priority (MRP) as extensions of the well known PS and RP mechanisms to the multi-type resource allocation problem (MTRA) with partial preferences. In our setting, there are multiple types of divisible items, and a group of agents who have partial order preferences over bundles consisting of one item of each type. We show that for the unrestricted domain of partial order preferences, no mechanism satisfies both sd-efficiency and sd-envy-freeness. Notwithstanding this impossibility result, our main message is positive: When agents' preferences are represented by acyclic CP-nets, MPS satisfies sd-efficiency, sd-envy-freeness, ordinal fairness, and upper invariance, while MRP satisfies ex-post-efficiency, sd-strategy-proofness, and upper invariance, recovering the properties of PS and RP.