 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurvature-Weighted Capacity Allocation: A Minimum Description Length Framework for Layer-Adaptive Large Language Model Optimization
Mar 01, 2026Layer-wise capacity in large language models is highly non-uniform: some layers contribute disproportionately to loss reduction while others are near-redundant. Existing methods for exploiting this non-uniformity, such as influence-function-based layer scoring, produce sensitivity estimates but offer no principled mechanism for translating them into allocation or pruning decisions under hardware constraints. We address this gap with a unified, curvature-aware framework grounded in the Minimum Description Length (MDL) principle. Our central quantity is the curvature-adjusted layer gain $ζ_k^2 = g_k^\top \widetilde{H}_{kk}^{-1} g_k$, which we show equals twice the maximal second-order reduction in empirical risk achievable by updating layer $k$ alone, and which strictly dominates gradient-norm-based scores by incorporating local curvature. Normalizing these gains into layer quality scores $q_k$, we formulate two convex MDL programs: a capacity allocation program that distributes expert slots or LoRA rank preferentially to high-curvature layers under diminishing returns, and a pruning program that concentrates sparsity on low-gain layers while protecting high-gain layers from degradation. Both programs admit unique closed-form solutions parameterized by a single dual variable, computable in $O(K \log 1/\varepsilon)$ via bisection. We prove an $O(δ^2)$ transfer regret bound showing that source-domain allocations remain near-optimal on target tasks when curvature scores drift by $δ$, with explicit constants tied to the condition number of the target program. Together, these results elevate layer-wise capacity optimization from an empirical heuristic to a theoretically grounded, computationally efficient framework with provable optimality and generalization guarantees.
Investigating Pedagogical Teacher and Student LLM Agents: Genetic Adaptation Meets Retrieval Augmented Generation Across Learning Style
May 25, 2025Effective teaching requires adapting instructional strategies to accommodate the diverse cognitive and behavioral profiles of students, a persistent challenge in education and teacher training. While Large Language Models (LLMs) offer promise as tools to simulate such complex pedagogical environments, current simulation frameworks are limited in two key respects: (1) they often reduce students to static knowledge profiles, and (2) they lack adaptive mechanisms for modeling teachers who evolve their strategies in response to student feedback. To address these gaps, \textbf{we introduce a novel simulation framework that integrates LLM-based heterogeneous student agents with a self-optimizing teacher agent}. The teacher agent's pedagogical policy is dynamically evolved using a genetic algorithm, allowing it to discover and refine effective teaching strategies based on the aggregate performance of diverse learners. In addition, \textbf{we propose Persona-RAG}, a Retrieval Augmented Generation module that enables student agents to retrieve knowledge tailored to their individual learning styles. Persona-RAG preserves the retrieval accuracy of standard RAG baselines while enhancing personalization, an essential factor in modeling realistic educational scenarios. Through extensive experiments, we demonstrate how our framework supports the emergence of distinct and interpretable teaching patterns when interacting with varied student populations. Our results highlight the potential of LLM-driven simulations to inform adaptive teaching practices and provide a testbed for training human educators in controlled, data-driven environments.
Bridging Predictive Coding and MDL: A Two-Part Code Framework for Deep Learning
May 20, 2025

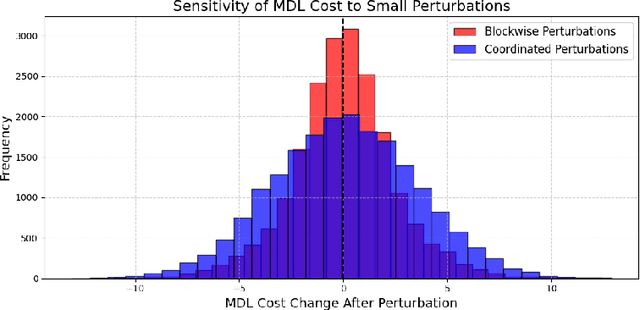
We present the first theoretical framework that connects predictive coding (PC), a biologically inspired local learning rule, with the minimum description length (MDL) principle in deep networks. We prove that layerwise PC performs block-coordinate descent on the MDL two-part code objective, thereby jointly minimizing empirical risk and model complexity. Using Hoeffding's inequality and a prefix-code prior, we derive a novel generalization bound of the form $R(\theta) \le \hat{R}(\theta) + \frac{L(\theta)}{N}$, capturing the tradeoff between fit and compression. We further prove that each PC sweep monotonically decreases the empirical two-part codelength, yielding tighter high-probability risk bounds than unconstrained gradient descent. Finally, we show that repeated PC updates converge to a block-coordinate stationary point, providing an approximate MDL-optimal solution. To our knowledge, this is the first result offering formal generalization and convergence guarantees for PC-trained deep models, positioning PC as a theoretically grounded and biologically plausible alternative to backpropagation.
TeLU Activation Function for Fast and Stable Deep Learning
Dec 28, 2024

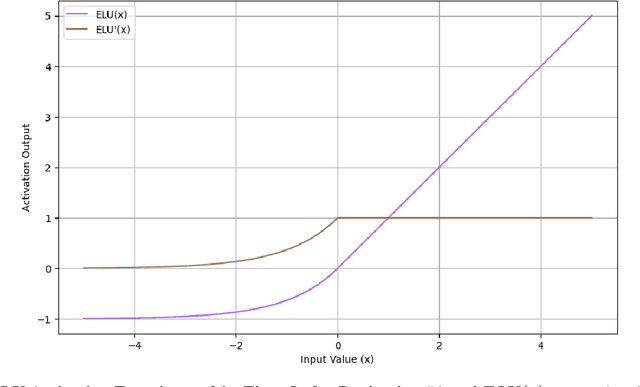

We propose the Hyperbolic Tangent Exponential Linear Unit (TeLU), a neural network hidden activation function defined as TeLU(x)=xtanh(exp(x)). TeLU's design is grounded in the core principles of key activation functions, achieving strong convergence by closely approximating the identity function in its active region while effectively mitigating the vanishing gradient problem in its saturating region. Its simple formulation enhances computational efficiency, leading to improvements in scalability and convergence speed. Unlike many modern activation functions, TeLU seamlessly combines the simplicity and effectiveness of ReLU with the smoothness and analytic properties essential for learning stability in deep neural networks. TeLU's ability to mimic the behavior and optimal hyperparameter settings of ReLU, while introducing the benefits of smoothness and curvature, makes it an ideal drop-in replacement. Its analytic nature positions TeLU as a powerful universal approximator, enhancing both robustness and generalization across a multitude of experiments. We rigorously validate these claims through theoretical analysis and experimental validation, demonstrating TeLU's performance across challenging benchmarks; including ResNet18 on ImageNet, Dynamic-Pooling Transformers on Text8, and Recurrent Neural Networks (RNNs) on the Penn TreeBank dataset. These results highlight TeLU's potential to set a new standard in activation functions, driving more efficient and stable learning in deep neural networks, thereby accelerating scientific discoveries across various fields.
Tight Stability, Convergence, and Robustness Bounds for Predictive Coding Networks
Oct 07, 2024



Energy-based learning algorithms, such as predictive coding (PC), have garnered significant attention in the machine learning community due to their theoretical properties, such as local operations and biologically plausible mechanisms for error correction. In this work, we rigorously analyze the stability, robustness, and convergence of PC through the lens of dynamical systems theory. We show that, first, PC is Lyapunov stable under mild assumptions on its loss and residual energy functions, which implies intrinsic robustness to small random perturbations due to its well-defined energy-minimizing dynamics. Second, we formally establish that the PC updates approximate quasi-Newton methods by incorporating higher-order curvature information, which makes them more stable and able to converge with fewer iterations compared to models trained via backpropagation (BP). Furthermore, using this dynamical framework, we provide new theoretical bounds on the similarity between PC and other algorithms, i.e., BP and target propagation (TP), by precisely characterizing the role of higher-order derivatives. These bounds, derived through detailed analysis of the Hessian structures, show that PC is significantly closer to quasi-Newton updates than TP, providing a deeper understanding of the stability and efficiency of PC compared to conventional learning methods.
Precision, Stability, and Generalization: A Comprehensive Assessment of RNNs learnability capability for Classifying Counter and Dyck Languages
Oct 04, 2024



This study investigates the learnability of Recurrent Neural Networks (RNNs) in classifying structured formal languages, focusing on counter and Dyck languages. Traditionally, both first-order (LSTM) and second-order (O2RNN) RNNs have been considered effective for such tasks, primarily based on their theoretical expressiveness within the Chomsky hierarchy. However, our research challenges this notion by demonstrating that RNNs primarily operate as state machines, where their linguistic capabilities are heavily influenced by the precision of their embeddings and the strategies used for sampling negative examples. Our experiments revealed that performance declines significantly as the structural similarity between positive and negative examples increases. Remarkably, even a basic single-layer classifier using RNN embeddings performed better than chance. To evaluate generalization, we trained models on strings up to a length of 40 and tested them on strings from lengths 41 to 500, using 10 unique seeds to ensure statistical robustness. Stability comparisons between LSTM and O2RNN models showed that O2RNNs generally offer greater stability across various scenarios. We further explore the impact of different initialization strategies revealing that our hypothesis is consistent with various RNNs. Overall, this research questions established beliefs about RNNs' computational capabilities, highlighting the importance of data structure and sampling techniques in assessing neural networks' potential for language classification tasks. It emphasizes that stronger constraints on expressivity are crucial for understanding true learnability, as mere expressivity does not capture the essence of learning.
Exploring Learnability in Memory-Augmented Recurrent Neural Networks: Precision, Stability, and Empirical Insights
Oct 04, 2024This study explores the learnability of memory-less and memory-augmented RNNs, which are theoretically equivalent to Pushdown Automata. Empirical results show that these models often fail to generalize on longer sequences, relying more on precision than mastering symbolic grammar. Experiments on fully trained and component-frozen models reveal that freezing the memory component significantly improves performance, achieving state-of-the-art results on the Penn Treebank dataset (test perplexity reduced from 123.5 to 120.5). Models with frozen memory retained up to 90% of initial performance on longer sequences, compared to a 60% drop in standard models. Theoretical analysis suggests that freezing memory stabilizes temporal dependencies, leading to robust convergence. These findings stress the need for stable memory designs and long-sequence evaluations to understand RNNs true learnability limits.
A Unified Framework for Continual Learning and Machine Unlearning
Aug 21, 2024Continual learning and machine unlearning are crucial challenges in machine learning, typically addressed separately. Continual learning focuses on adapting to new knowledge while preserving past information, whereas unlearning involves selectively forgetting specific subsets of data. In this paper, we introduce a novel framework that jointly tackles both tasks by leveraging controlled knowledge distillation. Our approach enables efficient learning with minimal forgetting and effective targeted unlearning. By incorporating a fixed memory buffer, the system supports learning new concepts while retaining prior knowledge. The distillation process is carefully managed to ensure a balance between acquiring new information and forgetting specific data as needed. Experimental results on benchmark datasets show that our method matches or exceeds the performance of existing approaches in both continual learning and machine unlearning. This unified framework is the first to address both challenges simultaneously, paving the way for adaptable models capable of dynamic learning and forgetting while maintaining strong overall performance.
Investigating Symbolic Capabilities of Large Language Models
May 21, 2024Prompting techniques have significantly enhanced the capabilities of Large Language Models (LLMs) across various complex tasks, including reasoning, planning, and solving math word problems. However, most research has predominantly focused on language-based reasoning and word problems, often overlooking the potential of LLMs in handling symbol-based calculations and reasoning. This study aims to bridge this gap by rigorously evaluating LLMs on a series of symbolic tasks, such as addition, multiplication, modulus arithmetic, numerical precision, and symbolic counting. Our analysis encompasses eight LLMs, including four enterprise-grade and four open-source models, of which three have been pre-trained on mathematical tasks. The assessment framework is anchored in Chomsky's Hierarchy, providing a robust measure of the computational abilities of these models. The evaluation employs minimally explained prompts alongside the zero-shot Chain of Thoughts technique, allowing models to navigate the solution process autonomously. The findings reveal a significant decline in LLMs' performance on context-free and context-sensitive symbolic tasks as the complexity, represented by the number of symbols, increases. Notably, even the fine-tuned GPT3.5 exhibits only marginal improvements, mirroring the performance trends observed in other models. Across the board, all models demonstrated a limited generalization ability on these symbol-intensive tasks. This research underscores LLMs' challenges with increasing symbolic complexity and highlights the need for specialized training, memory and architectural adjustments to enhance their proficiency in symbol-based reasoning tasks.
Neuro-mimetic Task-free Unsupervised Online Learning with Continual Self-Organizing Maps
Feb 19, 2024An intelligent system capable of continual learning is one that can process and extract knowledge from potentially infinitely long streams of pattern vectors. The major challenge that makes crafting such a system difficult is known as catastrophic forgetting - an agent, such as one based on artificial neural networks (ANNs), struggles to retain previously acquired knowledge when learning from new samples. Furthermore, ensuring that knowledge is preserved for previous tasks becomes more challenging when input is not supplemented with task boundary information. Although forgetting in the context of ANNs has been studied extensively, there still exists far less work investigating it in terms of unsupervised architectures such as the venerable self-organizing map (SOM), a neural model often used in clustering and dimensionality reduction. While the internal mechanisms of SOMs could, in principle, yield sparse representations that improve memory retention, we observe that, when a fixed-size SOM processes continuous data streams, it experiences concept drift. In light of this, we propose a generalization of the SOM, the continual SOM (CSOM), which is capable of online unsupervised learning under a low memory budget. Our results, on benchmarks including MNIST, Kuzushiji-MNIST, and Fashion-MNIST, show almost a two times increase in accuracy, and CIFAR-10 demonstrates a state-of-the-art result when tested on (online) unsupervised class incremental learning setting.