 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Recognition with Objectness, Attribute and Category Learning
Paper and Code
Jul 20, 2022
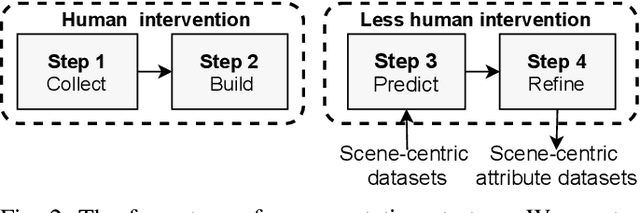
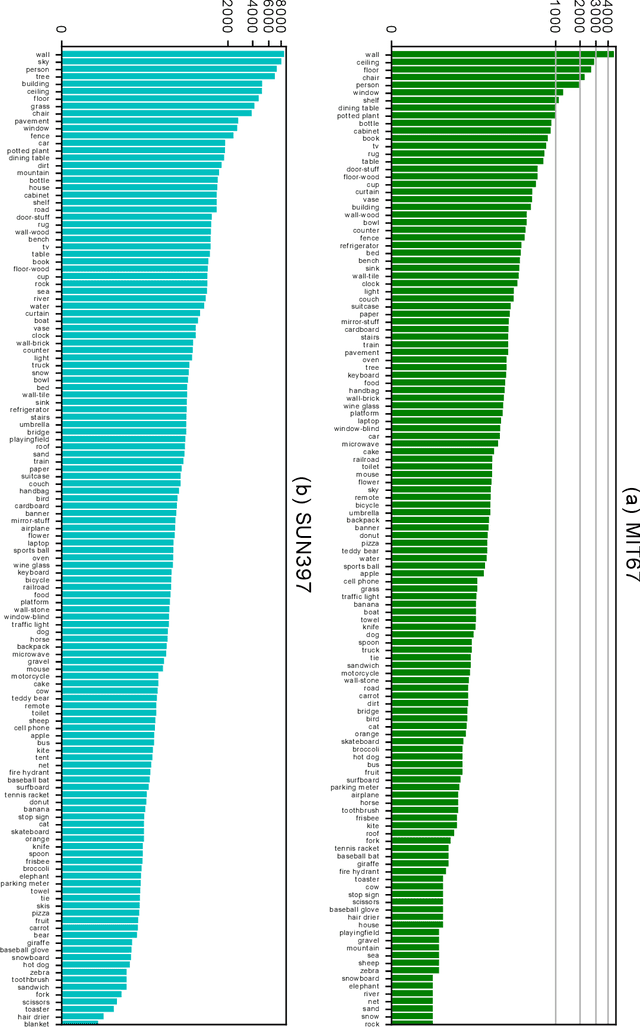
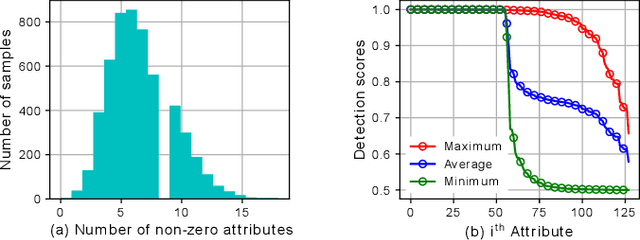
Scene classification has established itself as a challenging research problem. Compared to images of individual objects, scene images could be much more semantically complex and abstract. Their difference mainly lies in the level of granularity of recognition. Yet, image recognition serves as a key pillar for the good performance of scene recognition as the knowledge attained from object images can be used for accurate recognition of scenes. The existing scene recognition methods only take the category label of the scene into consideration. However, we find that the contextual information that contains detailed local descriptions are also beneficial in allowing the scene recognition model to be more discriminative. In this paper, we aim to improve scene recognition using attribute and category label information encoded in objects. Based on the complementarity of attribute and category labels, we propose a Multi-task Attribute-Scene Recognition (MASR) network which learns a category embedding and at the same time predicts scene attributes. Attribute acquisition and object annotation are tedious and time consuming tasks. We tackle the problem by proposing a partially supervised annotation strategy in which human intervention is significantly reduced. The strategy provides a much more cost-effective solution to real world scenarios, and requires considerably less annotation efforts. Moreover, we re-weight the attribute predictions considering the level of importance indicated by the object detected scores. Using the proposed method, we efficiently annotate attribute labels for four large-scale datasets, and systematically investigate how scene and attribute recognition benefit from each other. The experimental results demonstrate that MASR learns a more discriminative representation and achieves competitive recognition performance compared to the state-of-the-art methods