 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Label Smoothing for Semi-supervised Person Re-Identification
Paper and Code
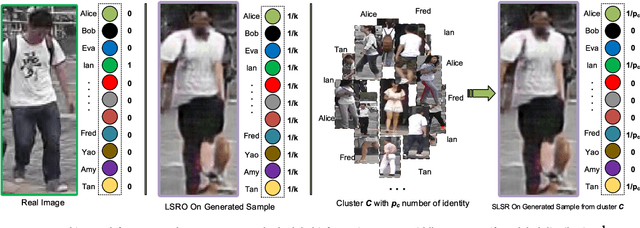

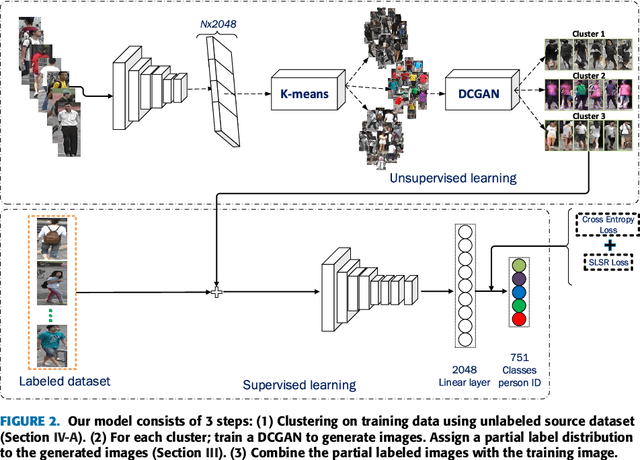

Person re-identification (re-id) is a cross-camera retrieval task which establishes a correspondence between images of a person from multiple cameras. Deep Learning methods have been successfully applied to the problem and achieved impressive results. However, these methods require large amounts of labeled training data. Current labeled datasets in person re-id are limited in scale and manually acquiring such large-scale dataset in surveillance camera is a tedious and labor-intensive task. In this paper, we propose a semi-supervised framework that performs Sparse Label Smoothing Regularization (SLSR) by considering similarities between unlabeled sample and training sample in the same feature space. Our approach first exploits the clustering property of existing person re-id datasets to create groups of similar objects that model the correlation among view. We make use of the training set to create cluster of similar objects using the intermediate feature representation of a CNN model. Each cluster is used to generate synthetic data samples using a generative adversarial model. We finally defined a sparse smoothing regularization term and train the network with join supervision of cross-entropy loss. The proposed approach tackles two problems (1) how to efficiently use the generated data and (2) how to address the over-smoothness problem found in current regularization. We solve these two problems by using a generative model for data augmentation and by maintaining and propagating similarities across the network through the concatenation of training images and generated images into one homogeneous feature space. Extensive experiments on four large-scale datasets show that our regularization method significantly improves the Re-ID accuracy compared to existing semi-supervised methods.